








AI-Driven Attack Surface Discovery
June 20, 2025
8 min read


AI is on everyone’s lips these days — and let’s be honest, it’s not always used effectively. But when applied wisely, it can deliver a real productivity boost.
At Netlas, we’re actively exploring how AI can streamline user workflows. While the obvious use case — generating search queries — is on our roadmap, we’ve identified another area where AI can offer practical value.
The Attack Surface Discovery Tool
Netlas is best known as an internet scanner, but it also includes a set of EASM-class tools. One of them is the Attack Surface Discovery Tool, which maps relationships between network entities. For example:
- A domain resolves to an IP address.
- That IP belongs to a subnet.
- WHOIS data reveals the organization managing the subnet.
- We then search for other subnets owned by the same organization.
- These subnets may contain IPs linked to additional domains — expanding the attack surface.
This is just one of dozens of discovery paths the tool supports for different asset types. Check out this video to see the tool in action, or read this in-depth article for a deep dive into its logic and use cases.
Recommended Reading
Complete Guide on Attack Surface Discovery

The Asset Classification Challenge
When mapping an attack surface via entity relationships using tools like Discovery, researchers typically rely on three main traversal strategies:
- Vertical downward: Exploring child assets from a known parent (e.g., subdomains).
- Vertical upward: Moving from a specific asset to its broader ownership context (e.g., IP to ASN, subdomain to root domain).
- Horizontal: Following lateral links between assets (e.g., shared infrastructure, WHOIS, certificates).
The downward path (broad-to-specific) is the most straightforward. Once a parent asset is confirmed to belong to the target, its children are presumed relevant. This is where brute-force techniques shine — such as dictionary-based subdomain enumeration or wide-range port scanning. No intelligence or context is required.
In contrast, upward and horizontal exploration require contextual understanding and judgment. These paths often yield ambiguous results that defy deterministic classification. While skilled analysts can intuitively recognize dead ends, automated tools struggle to determine whether a given discovery truly expands the original attack surface — or simply leads to unrelated third-party infrastructure.
Let’s look at real-world scenarios where this becomes especially critical.
Case 1: Public MX and NS
Mail and name server relationships can be fruitful — or completely misleading — depending on the organization’s infrastructure setup.
For example, FireEye operates its own MX servers, while delegating DNS management to Cloudflare. In this case, only the MX path is worth exploring1.
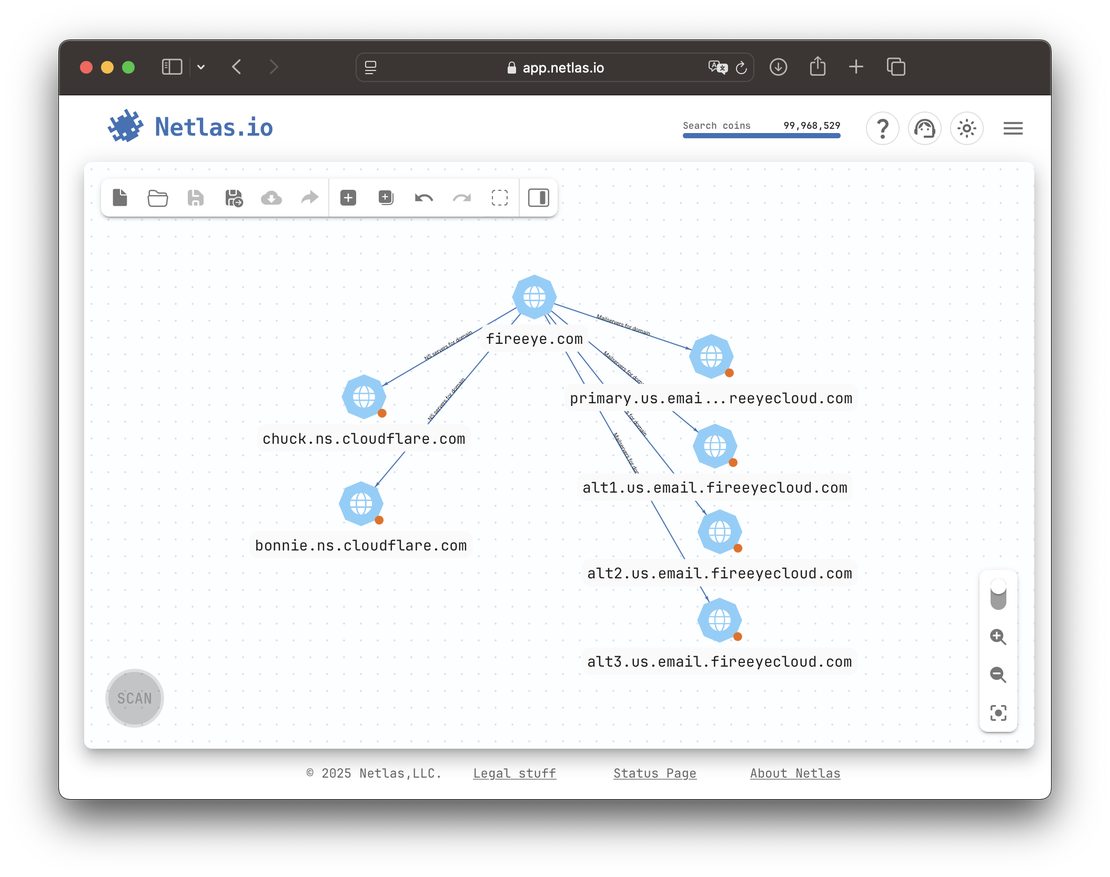
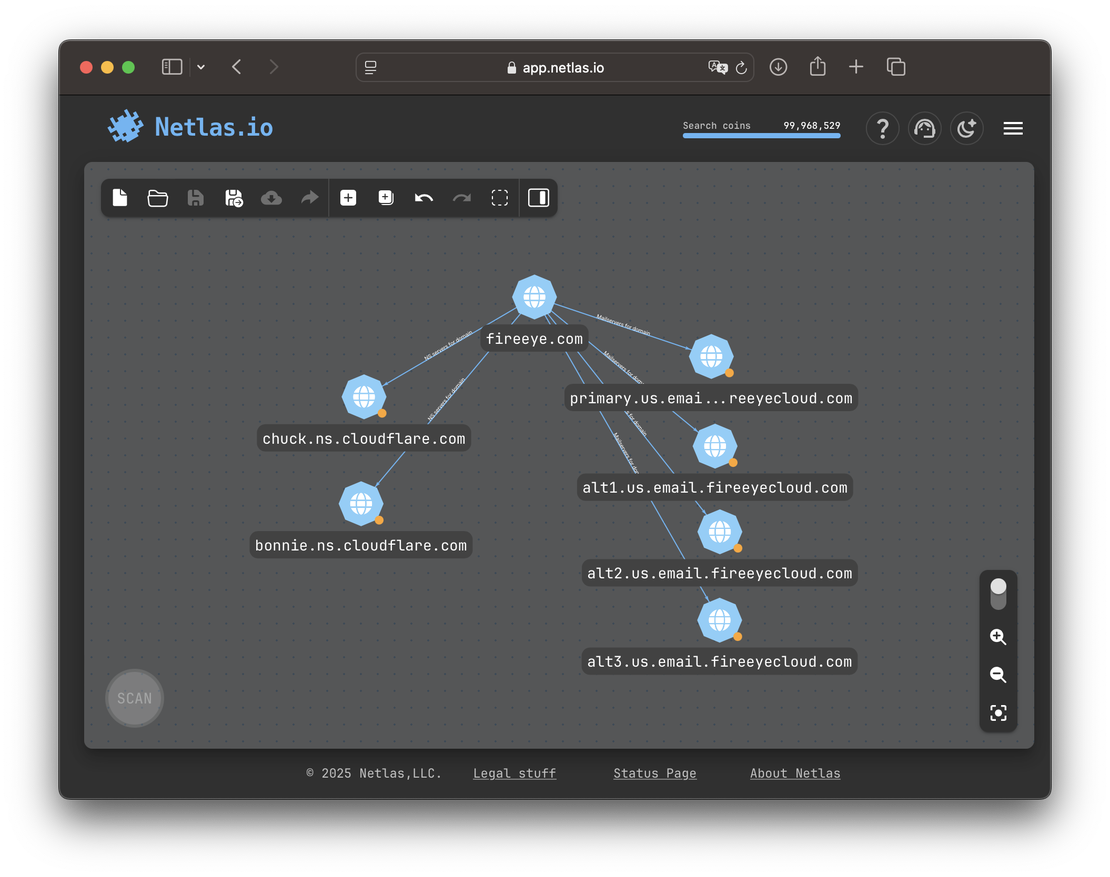
By contrast, Kaspersky hosts both MX and NS records on its own infrastructure — making both paths valuable for expansion.
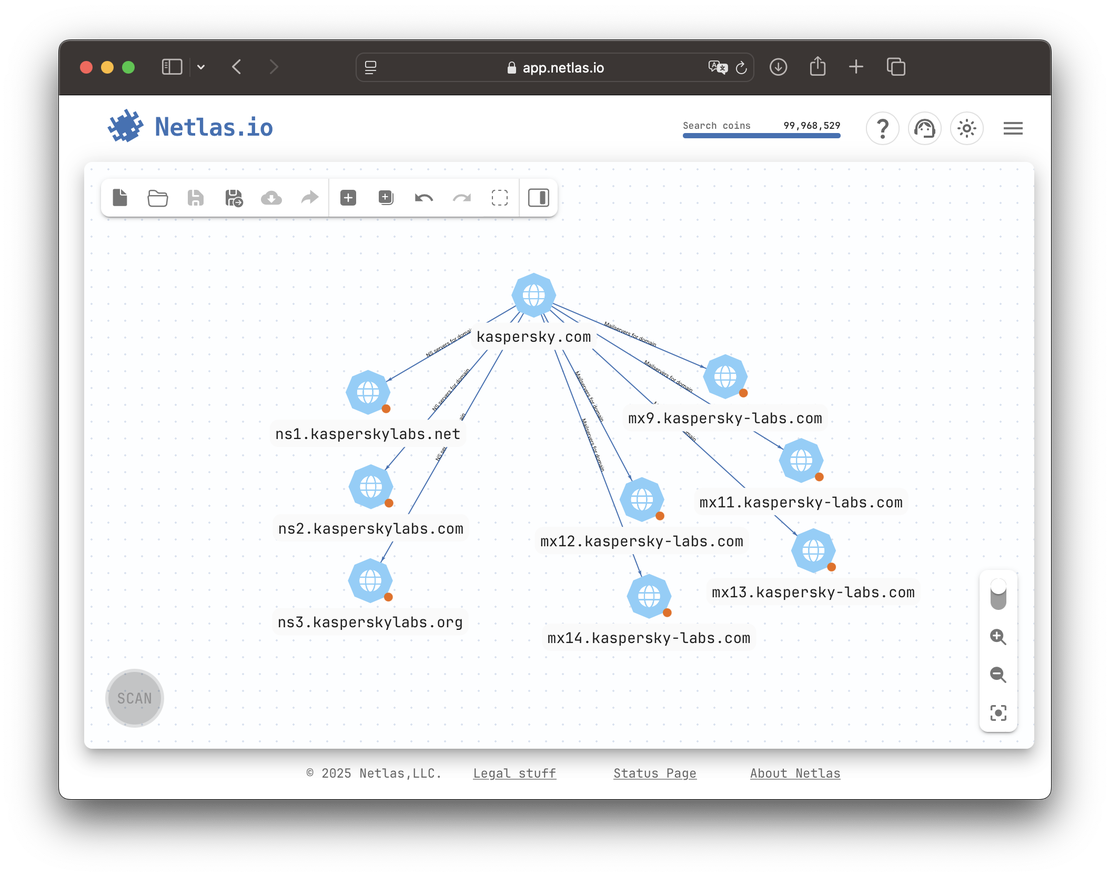
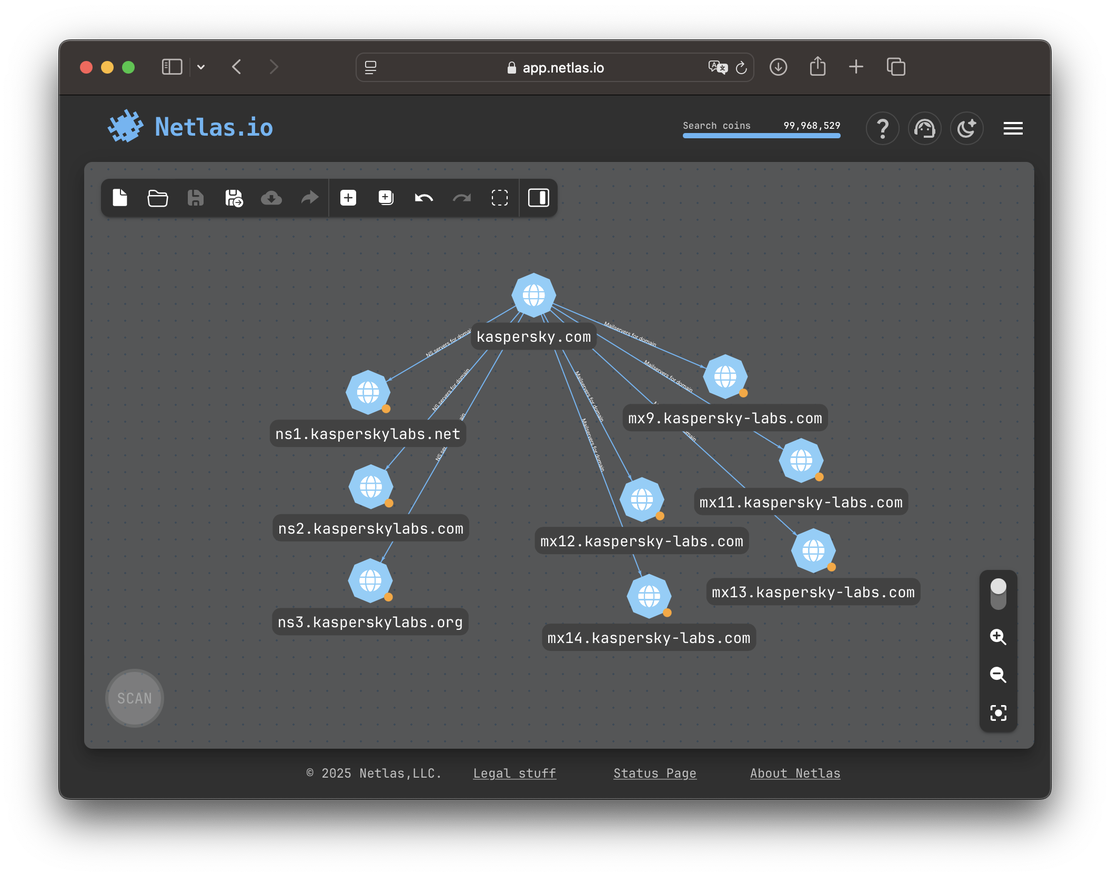
In Mandiant’s case, nameservers point to Cloudflare and MX to Google. Neither path offers much value — both lead to massive shared platforms with no clear links to other Mandiant-owned assets.
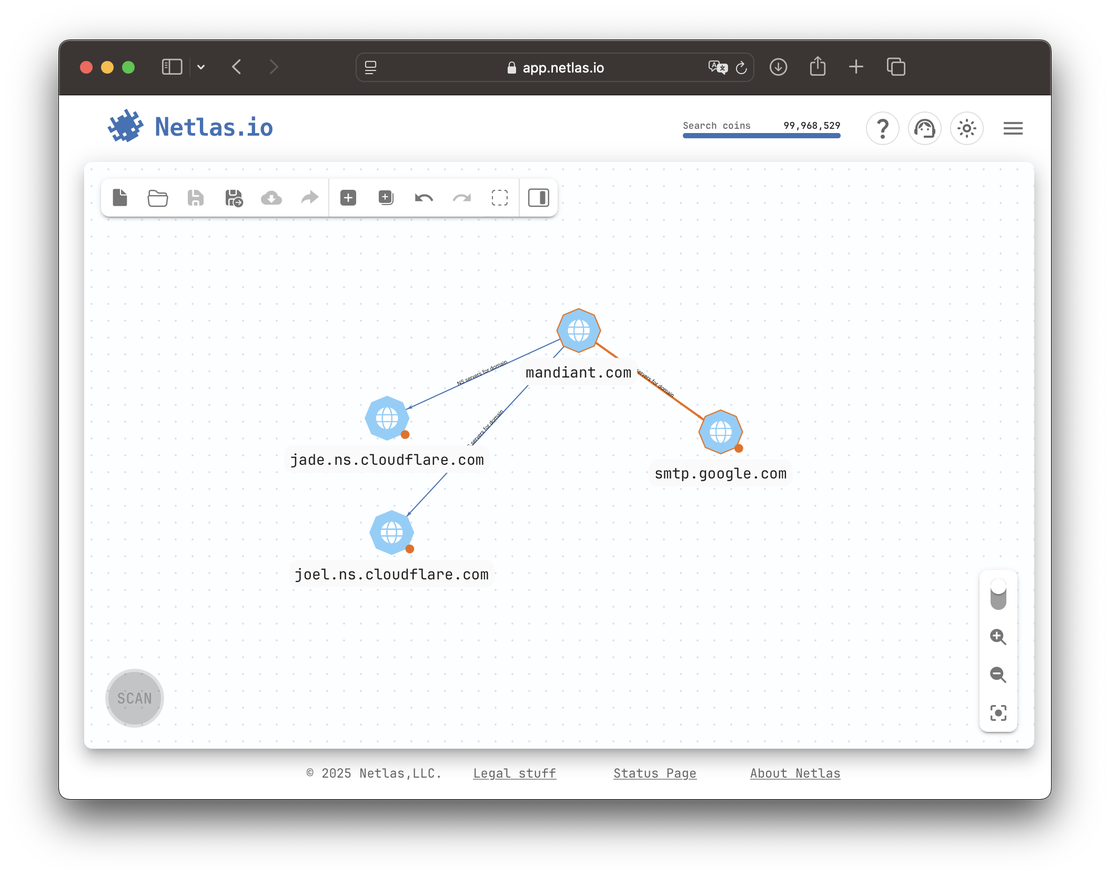
At first glance, the correct choice may seem obvious. But programmatically distinguishing between first-party and third-party infrastructure — especially at scale — is extremely difficult. There is no universal list of third-party providers comprehensive enough to enable deterministic filtering.
Case 2: WHOIS Privacy and Context
Another complex area is WHOIS analysis. Many domains expose only generic or privacy-protected WHOIS info, while others offer potentially valuable clues — but only if you know how to interpret them.
Here’s a WHOIS record for a fireeye.com domain:
Registrant Name: Host Master
Registrant Organization: Musarubra US LLC
Registrant Email: [email protected] This looks routine — unless you recognize that FireEye merged with McAfee Enterprise to form Trellix. That final email field becomes a strong signal only when placed in its broader context.
Now contrast with the WHOIS for mandiant.com:
Registrant Organization: Google LLC
Registrant State/Province: CA
Registrant Country: US
Registrant Email: Select Request Email Form at https://domains.markmonitor.com/whois/mandiant.comThis record is privacy-protected and belongs to the registrar, MarkMonitor. No useful discovery paths emerge here — unless you’re performing deeper registrar-based infrastructure fingerprinting.
Other Cases
Third-Party Hosting and CDNs
Many assets are hosted on platforms like AWS, Azure, or Akamai. Without context, it’s hard to tell whether an IP or domain actually belongs to the target or is just a shared hosting environment.
Certificate Subject Analysis
SSL certificates may contain organization names, email addresses, or domains. But interpreting these fields correctly (e.g., spotting misspellings, legacy names, or M&A indicators) requires domain knowledge.
Typosquatting and Brand Abuse
Suspicious domains with similar names might be part of the attack surface — or belong to adversaries. Identifying intent requires investigation, not just string similarity.
Request Your Free 14-Day Trial
Submit a request to try Netlas free for 14 days with full access to all features.
Can Large Language Models Help?
This exact question came to mind during a demo of our Discovery tool for potential clients:
Could a language model like ChatGPT help solve the asset classification challenge — if given the right context and data?
To find out, I ran a few simple experiments by feeding Discovery’s output directly into ChatGPT’s interface. The results were surprisingly promising. ChatGPT 4.1 made almost no mistakes — it reliably determined which search directions were worth pursuing based on just the search name and a five-result preview. In many cases, it also correctly identified which paths could be safely skipped.
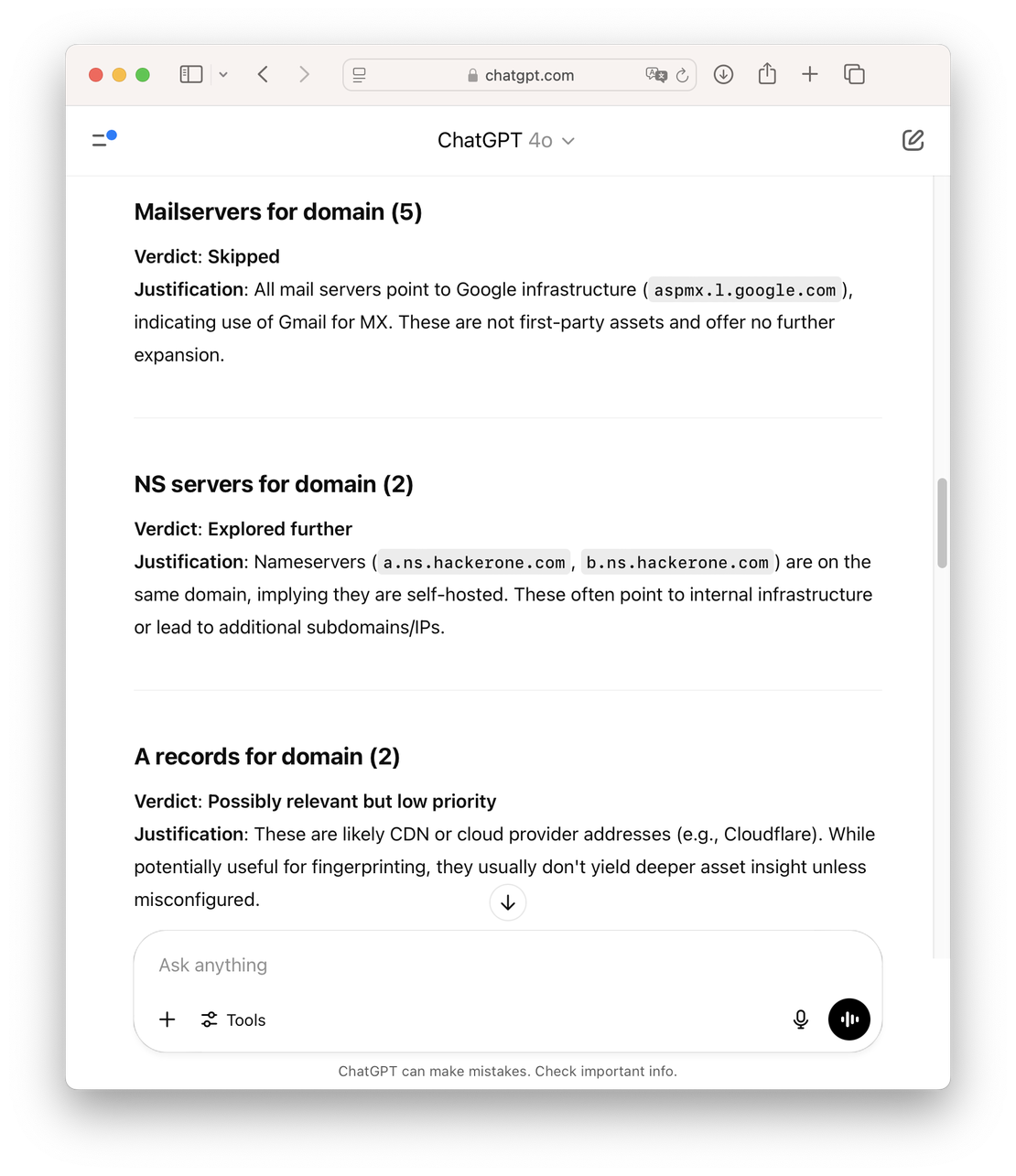
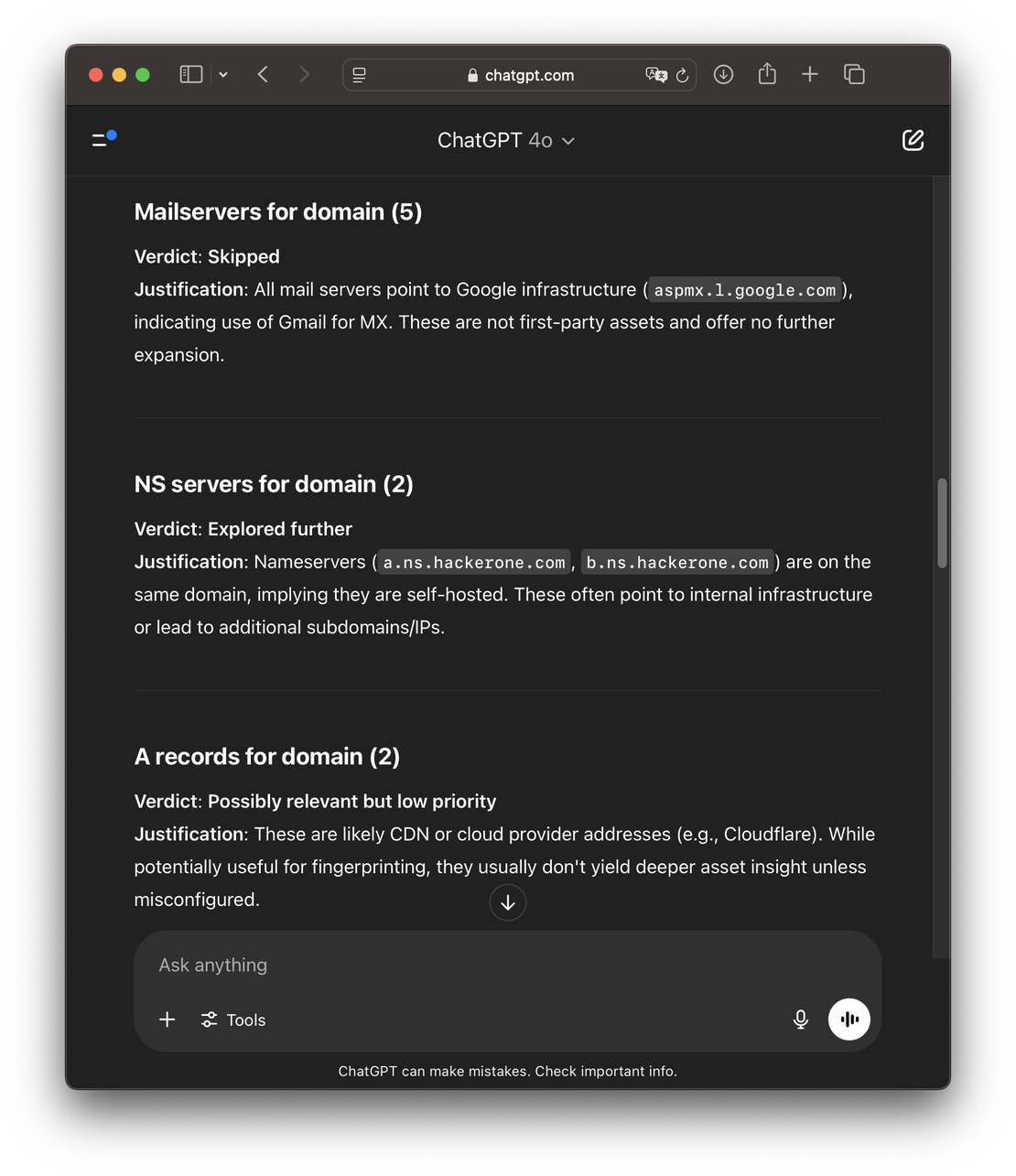
Encouraged by these early results, I built a Python proof-of-concept (PoC) to conduct more structured and extensive testing.
PoC Overview
The proof-of-concept operates through a straightforward workflow:
Initial Input
Start with an organizational domain as the entry point.Query Discovery API
Retrieve available search directions and result previews - identical to what appears in the web interface’s search panel.LLM Decision Layer
The language model evaluates which searches to:- Execute fully
- Run with partial filtering
- Skip entirely
Iterative Processing
Take the next unprocessed asset group and repeat steps 2 and 3.Termination
Return results when no unprocessed groups remain.
This is exactly how searches appear to researchers using Discovery’s web interface:
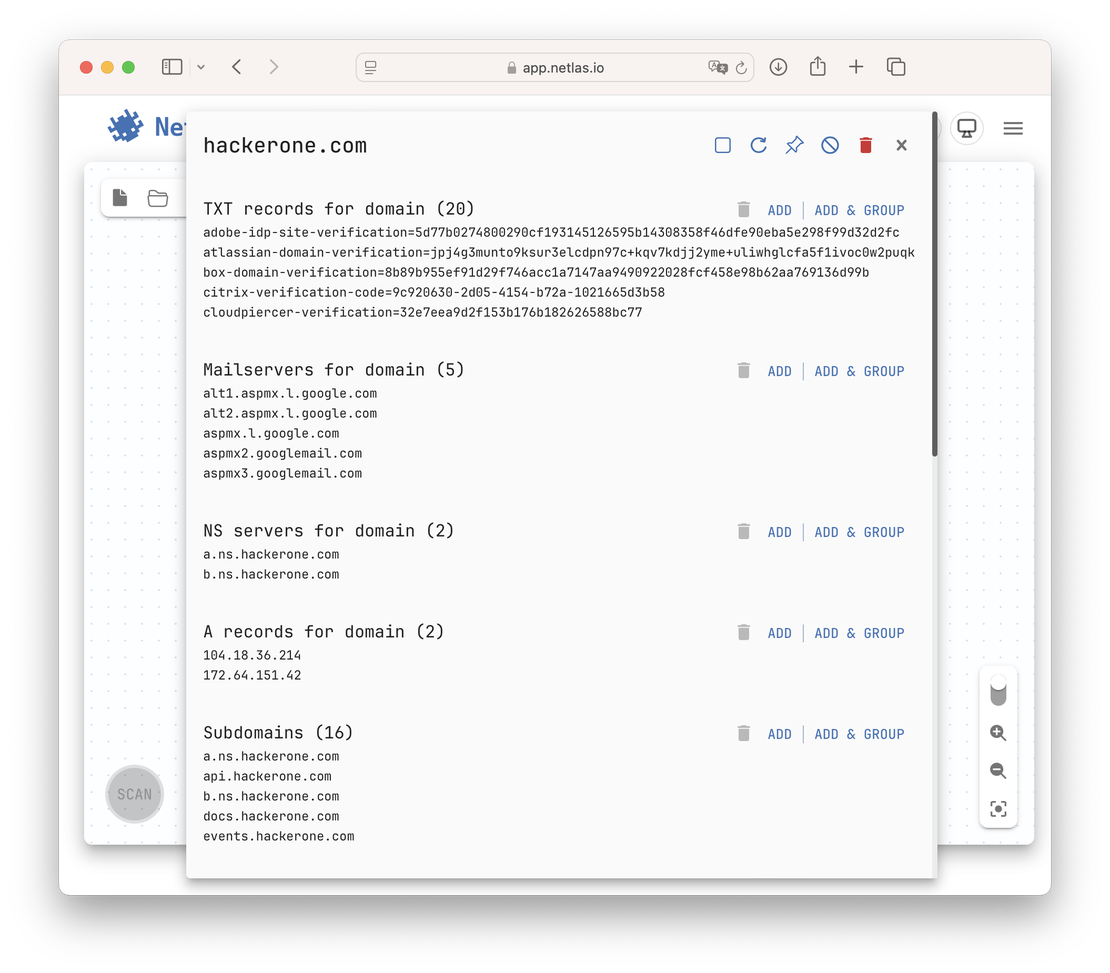
We request this identical data volume at Step 2 and pass it to the language model at Step 3. If this context proves sufficient for human researchers in most cases, it should theoretically suffice for the LLM as well.
Leverage the Discovery API
If you’ve worked with the Discovery tool and assumed its API must be complex because of the graph visualization — here’s some good news: it’s not. The graphical representation is handled entirely by JavaScript in the browser. The API itself simply returns available search directions and their corresponding results.
For this proof of concept (PoC), we’ll keep it simple and use just two endpoints:
Get Search Directions
Retrieves possible search paths for a given node group.Execute Search
Fetches the full result set for a given path.
Here is the example response from the first endpoint:
{
"search_field": "Mailservers for domain",
"count": 5,
"preview": [
"alt1.aspmx.l.google.com",
"alt2.aspmx.l.google.com",
"aspmx.l.google.com",
"aspmx2.googlemail.com",
"aspmx3.googlemail.com"
],
"search_field_id": 31,
"is_too_much_docs": false
}
{
"search_field": "NS servers for domain",
"count": 2,
"preview": [
"a.ns.hackerone.com",
"b.ns.hackerone.com"
],
"search_field_id": 30,
"is_too_much_docs": false
}
{
"search_field": "A records for domain",
"count": 2,
"preview": [
"104.18.36.214",
"172.64.151.42"
],
"search_field_id": 29,
"is_too_much_docs": false
}
{
"search_field": "Subdomains",
"count": 16,
"preview": [
"a.ns.hackerone.com",
"api.hackerone.com",
"b.ns.hackerone.com",
"docs.hackerone.com",
"events.hackerone.com"
],
"search_field_id": 35,
"is_too_much_docs": false
}
{
"search_field": "Registrant phone from WHOIS",
"count": 1,
"preview": [
"DATA REDACTED"
],
"search_field_id": 39,
"is_too_much_docs": false
}Leverage the OpenAI API
To automate decision-making, I instructed the model via the system prompt to return results in YAML format. For each available search direction, it must decide whether to:
- Execute the search
- Execute and filter partial results
- Skip the search entirely
Example YAML response:
add: [30, 35, 29]
skip: [31, 39]
partly: [37]One key feature of this PoC is response validation. Every model output is checked against two criteria:
Completeness
The model must make a decision about every proposed search direction. No entries can be left unaddressed.Rule Compliance
The model must follow specific quantitative rules defined in the prompt. For example, it cannot request filtering on searches that return more than a defined threshold of nodes.
Looking ahead, experiments confirmed that the system prompt is the single most critical factor for successful AI integration. It influences the model’s behavior more than the number of past messages included in the chat history.
I also noticed significant behavioral differences across model versions. A prompt that performed well with gpt-4-turbo often yielded subpar results when used with gpt-4.1 — and vice versa.
Seeing is Believing
See how Netlas can elevate your threat analysis. Book a quick demo with our team.
Experimental Findings
The key question I aimed to answer was:
Which language model performs best at classifying assets for attack surface mapping, and how effectively can this task be automated using today’s top models?
To explore this, I tested five OpenAI models available via API:
gpt-4.1gpt-4.1-minigpt-4ogpt-4-turbogpt-4o-mini
I began with a series of dry runs to fine-tune the system prompt and ensure consistent script behavior. Once stable, I launched the main evaluation.
In this stage, each model was tasked with classifying search paths and expanding the attack surface for 10 different domains, all belonging to well-known cybersecurity vendors.
Below is the test script I used:
OPENAI_MODELS=(
"gpt-4.1"
"gpt-4.1-mini"
"gpt-4o"
"gpt-4-turbo"
"gpt-4o-mini"
)
args=(
"mandiant.com"
"kaspersky.com"
"crowdstrike.com"
"fireeye.com"
"fortiguard.com"
"paloaltonetworks.com"
"sentinelone.com"
"ptsecurity.com"
"hackerone.com"
"hackthebox.com"
)
for arg in "${args[@]}"; do
for model in "${OPENAI_MODELS[@]}"; do
export OPENAI_MODEL="$model"
echo "$model: Building perimeter for $arg"
python3 ai-perimeter.py -s "$arg" > "ai-comparison/$arg.$model.txt"
done
doneThe results were evaluated manually. For each domain, I used a line-by-line file comparison tool to inspect and compare the outputs from each model.
Which Model Performed Best?
Before starting the experiment, I reviewed OpenAI’s documentation — and even asked ChatGPT itself. After all, who better to recommend an LLM than an LLM? Based on both sources, the most promising candidates were expected to be gpt-4-turbo and gpt-4.1.
The results largely confirmed this. While gpt-4.1 didn’t outperform every model in every single case, it consistently delivered the most accurate and reliable results overall.
Here’s a comparison of the tested models:
| Model | Cost | Performance |
|---|---|---|
| gpt-4.1 | $$ | ★★★ |
| gpt-4.1-mini | $ | ★ |
| gpt-4o | $$ | ★★ |
| gpt-4-turbo | $$$ | ★★ |
| gpt-4o-mini | $ | ★ |
Task Completion Success Rate
Below are the results for gpt-4.1-2025-04-14:
- In 70% of cases, the model successfully completed the task with sufficient coverage and accuracy.
- In the remaining 30%, the output failed validation due to either incomplete responses or violations of prompt constraints.
Additional insights:
- The outcome is highly sensitive to the system prompt. Even minor wording changes can significantly impact performance.
- Re-running the same task with identical input sometimes leads to success, suggesting variability in model behavior.
It’s also worth noting that I’m not an AI engineer. With more advanced techniques (e.g., fine-tuning, or custom validation layers), results could likely be improved even further.
UPDATE: Since drafting this article, I’ve implemented Structured Output, leading to a substantial decrease in validation errors. In most instances, the model now consistently generates the expected structured output. Nonetheless, I believe there’s still room for enhancement in the results.
If you have experience in this space, I’d love to hear your thoughts or suggestions.
The proof-of-concept source code is available on GitHub.

Book Your Netlas Demo
Chat with our team to explore how the Netlas platform can support your security research and threat analysis.
Some attackers investigate Cloudflare NS servers anyway, since all domains under a single Cloudflare account often share the same NS pair — a potential fingerprinting vector. ↩︎
Related Posts

October 9, 2024
Complete Guide on Attack Surface Discovery

June 10, 2025
How to Detect CVEs Using Nmap Vulnerability Scan Scripts

June 19, 2025
Nmap Cheat Sheet: Top 10 Scan Techiques

June 25, 2025
theHarvester: a Classic Open Source Intelligence Tool

January 20, 2025
Using Maltego with Netlas Module

June 16, 2025
Google Dorking in Cybersecurity: Techniques for OSINT & Pentesting




