









Google Dorking in Cybersecurity: Techniques for OSINT & Pentesting
June 16, 2025
13 min read

Google dorking is a must-know technique for uncovering hidden resources on the internet. In this article, we’ll explore how Google dorking can be leveraged in information security, examine practical examples, and introduce alternative techniques to enhance your cybersecurity toolkit.
Basic Concepts
Before diving into Google dorking directly, let’s cover some brief theoretical background. Experienced users may choose to skip this section, but for those who have only a vague understanding of what Google Dorking entails, we recommend giving it a read.
What is Google Dorking?
Google Dorking, also known as Google Hacking, is a technique for crafting search queries on Google using specific keywords (dorks) and logical operators to access particular sites, file types, or pages.
With Google Dorking, you can search target sites for files with specific extensions, pages with particular titles, or specific keywords within URLs. This technique is highly useful for OSINT investigations, reconnaissance during penetration tests, or even for satisfying personal curiosity.
Most Valuable Google Dorks
The list of dorks that can be used in Google search is quite extensive. However, from an information security perspective, not all of them are relevant — after all, checking the weather (using the dork “weather:CityName”) isn’t typically part of a security assessment. In this section, I’ll provide a list of search queries that are most valuable for cybersecurity specialists.
- after/before
allows you to set date boundaries for search results.
"netlas" & (before:2025-06-06 after:2025-01-01)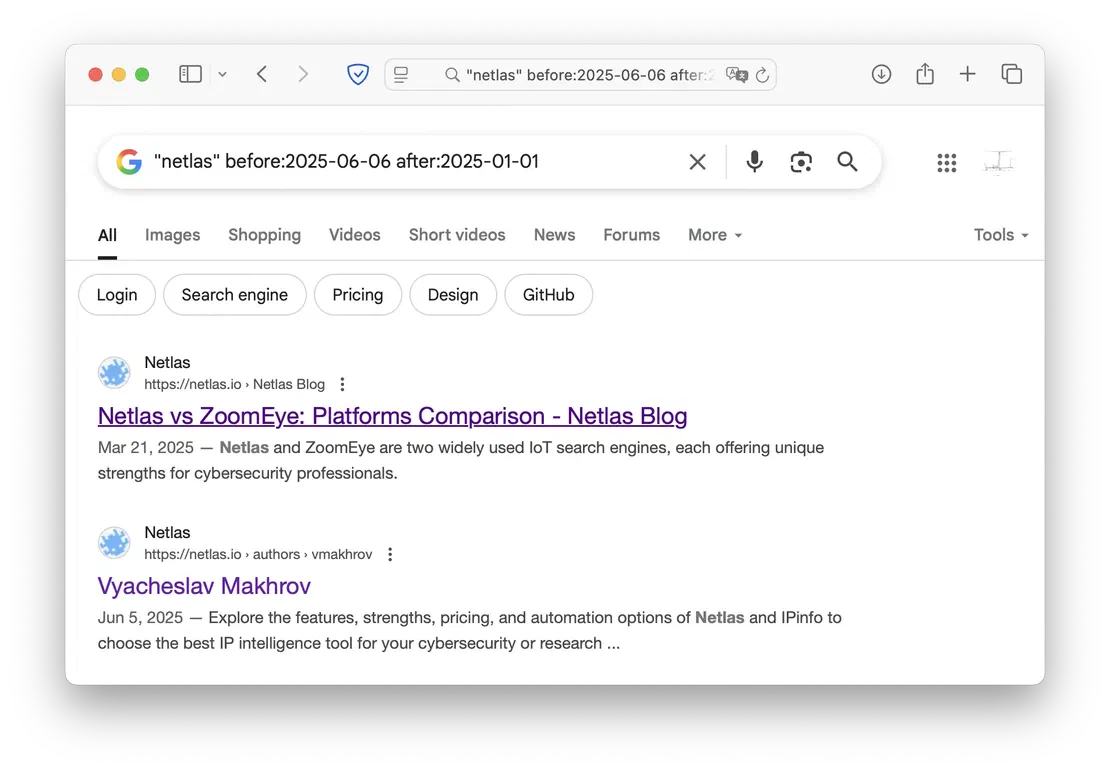
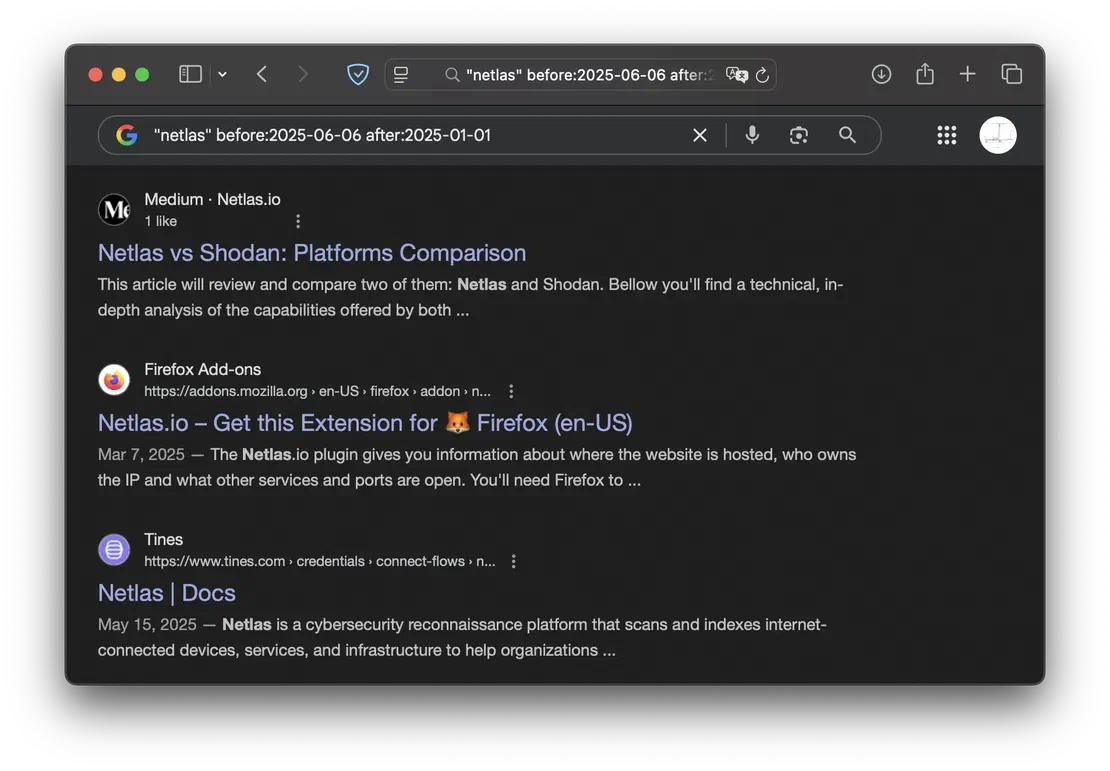
- cache
enables you to access Google-cached versions of sites that may currently be unavailable.
It functions similarly to using the Wayback Machine but allows you to explore a wider range of websites.
"cache:netlas.io"
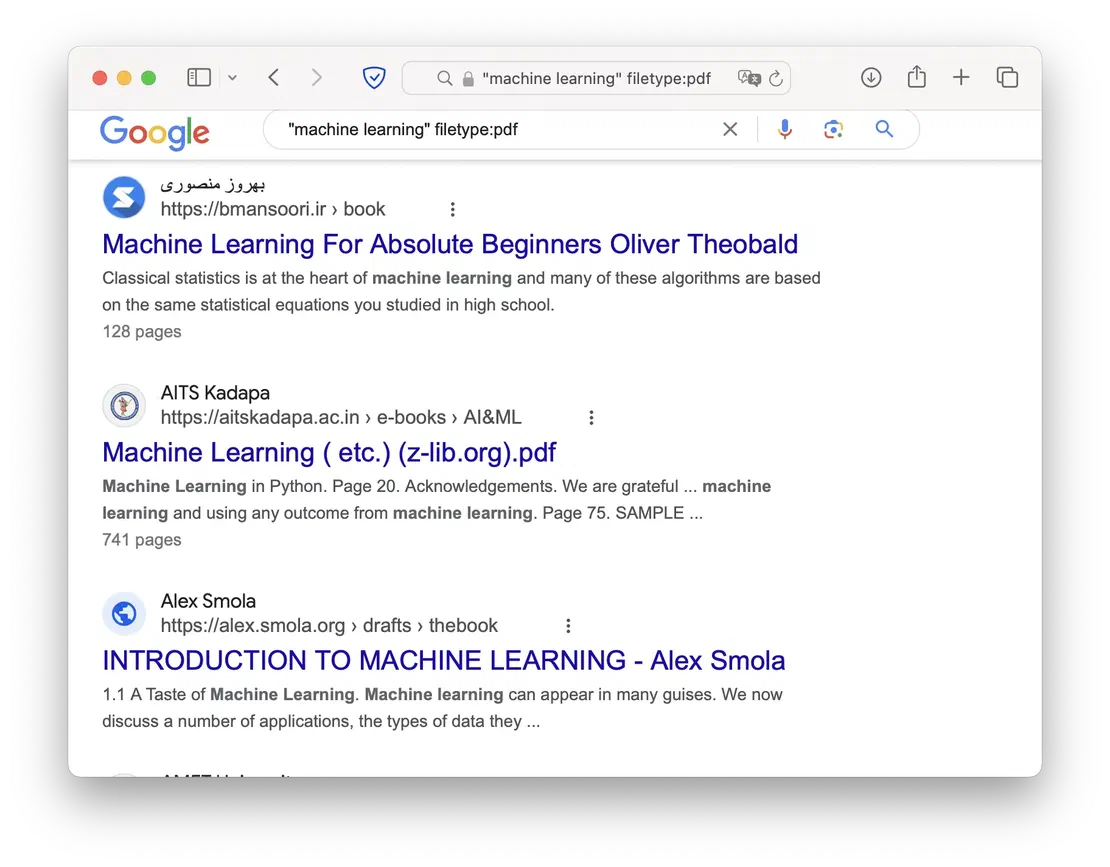
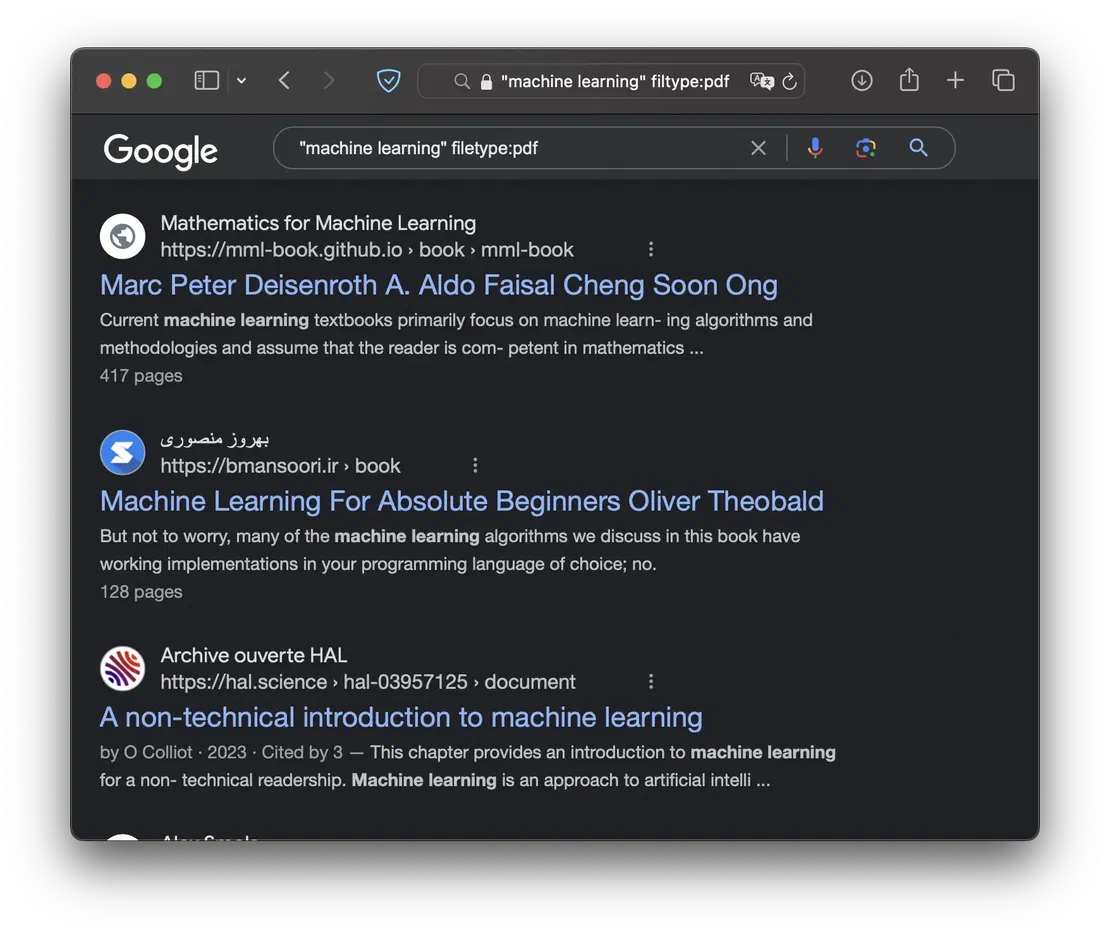
- filetype
allows you to define the file extension to search for.
Some of the possible extensions include PDF, PS, DWF, KML, KMZ, XLS, PPT, DOC, RTF, and SWF. Files not covered in this list can be located using combinations of other dorks, which will be discussed in the use cases section.
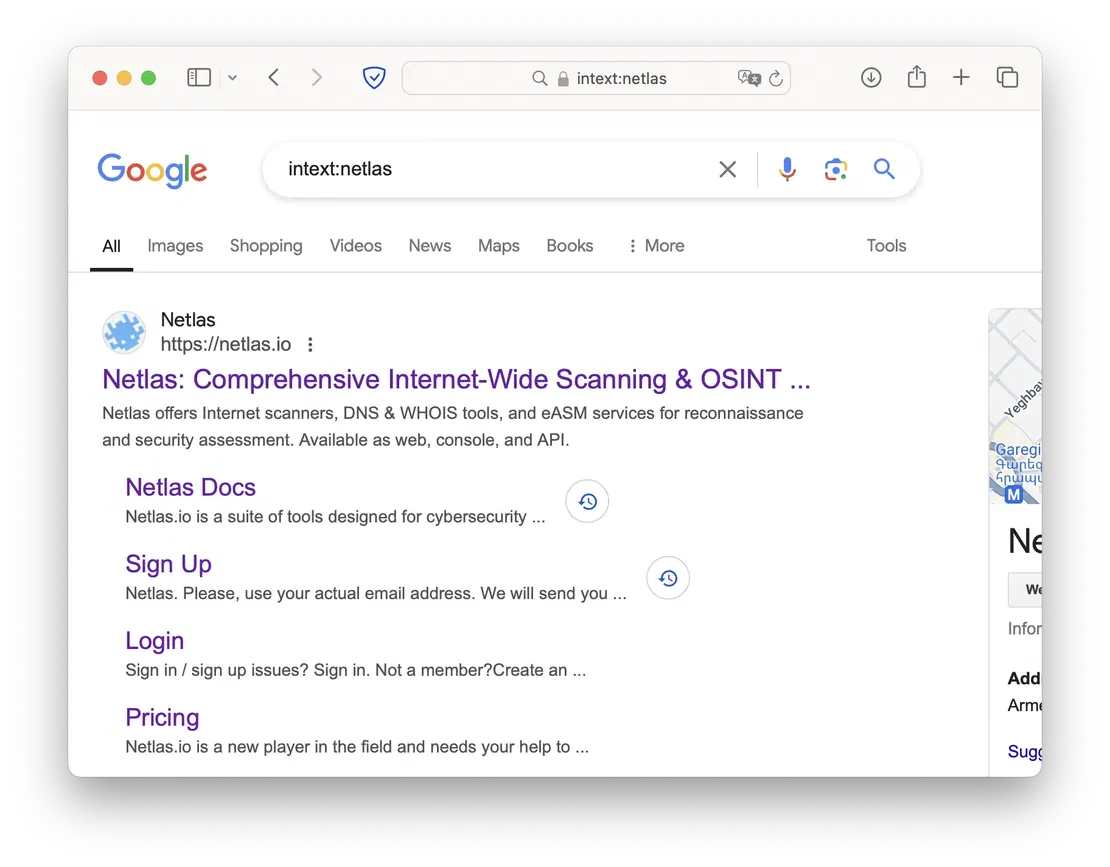
- intext
- pages in the text of which the keyword appears.
- allintext
- pages in the text of which the exact sequence of words occurs.
These two dorks are similar to a regular Google search and a search for a query in quotation marks. The only exception is that using intext/allintext, you will only find pages whose keyword is in the body. At the same time, a regular search and a query in quotation marks will also return pages where the keyword is in the title.
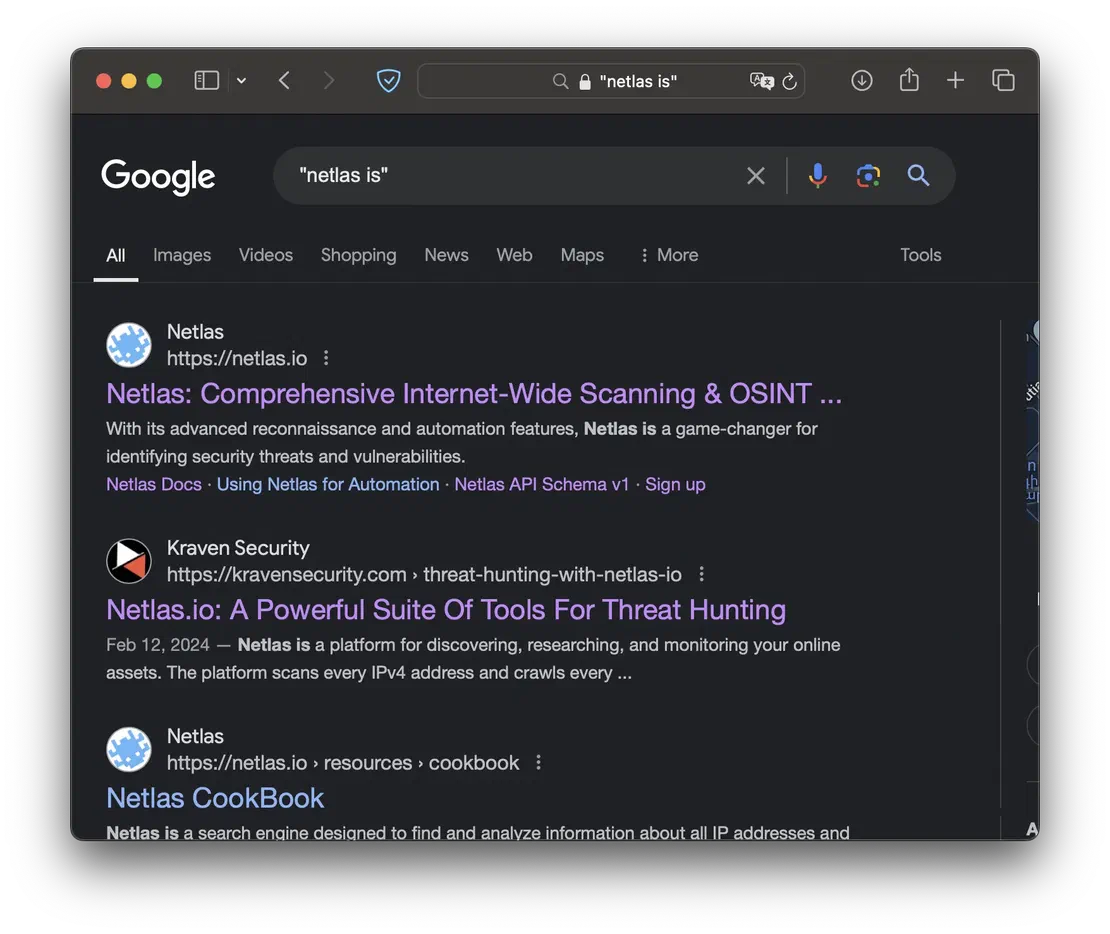
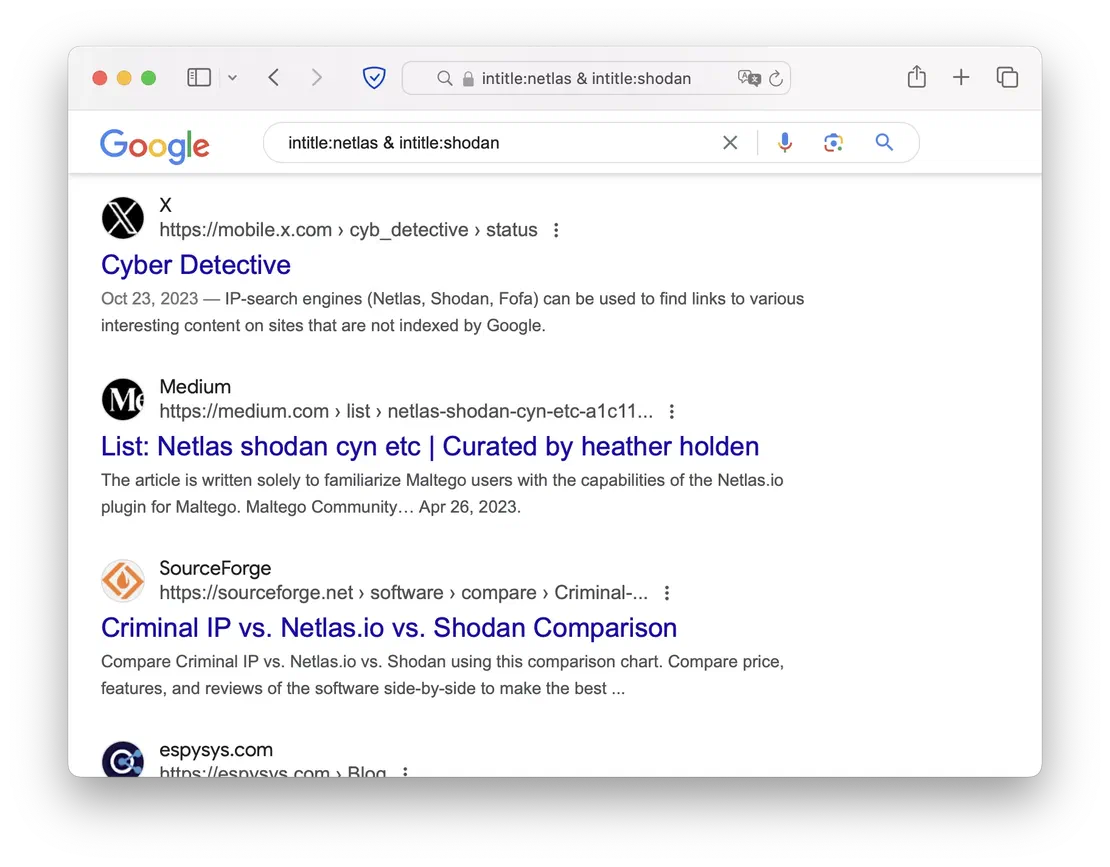
- intitle
- search for a specific word in the page title.
- allititle
- search for a specific combination of words in the page title.
This is a highly useful and commonly used dork, enabling you to find web interfaces, articles, login pages, and more.
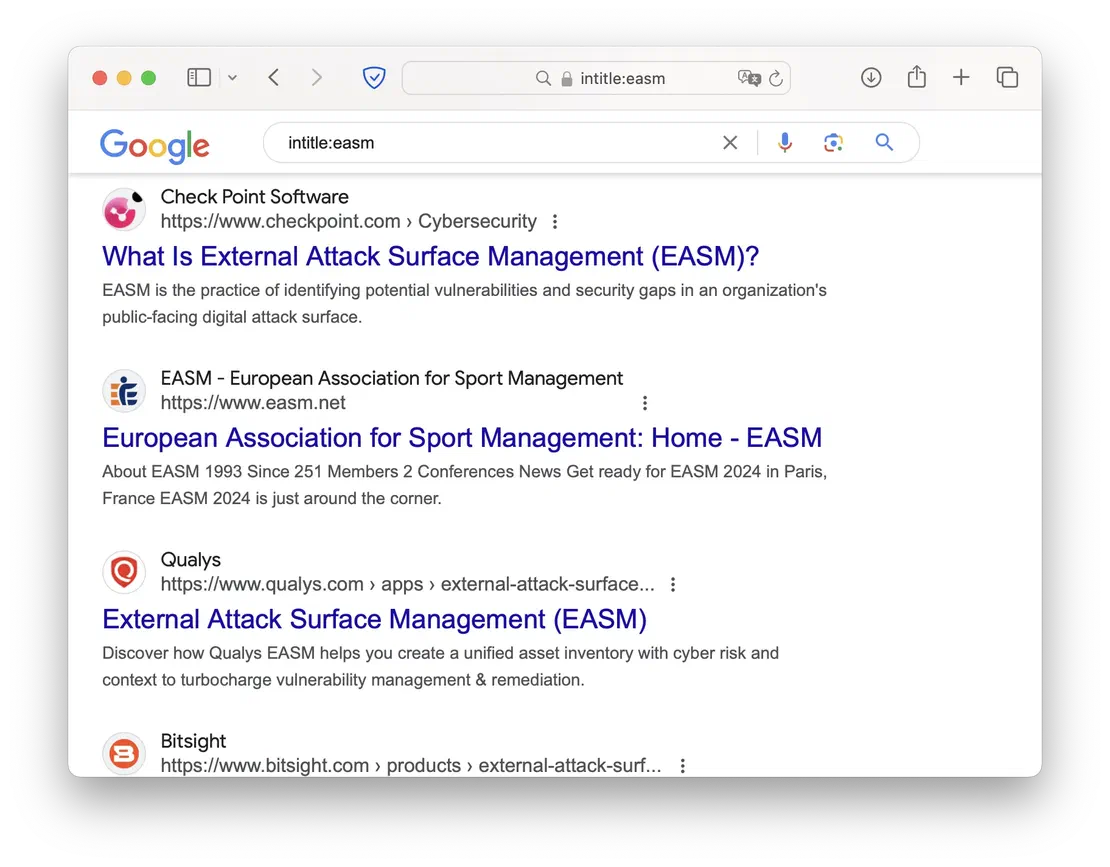
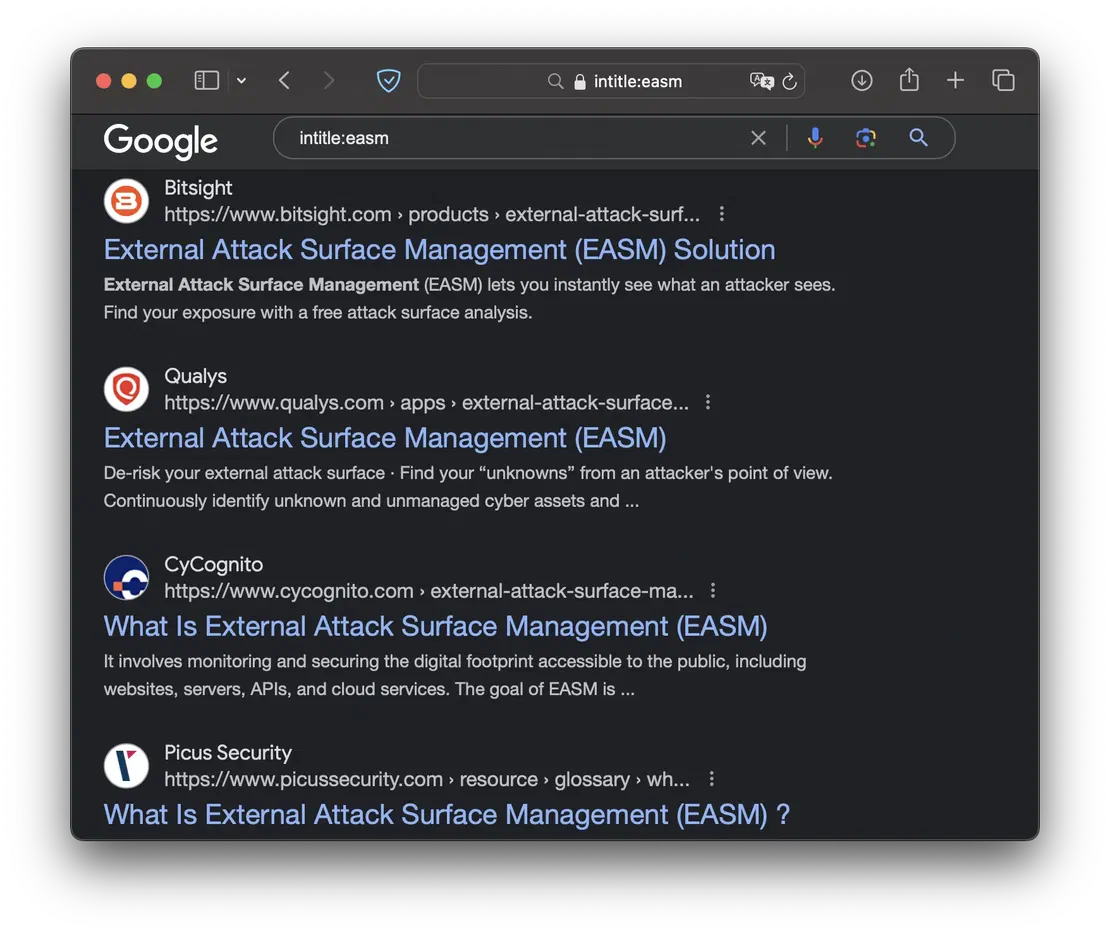
- inurl
- a specific word in the page address.
- allinurl
- a combination of certain words in the page address.
This dork is equally valuable, as it helps locate various technical pages (like login portals) and services within a specific domain.
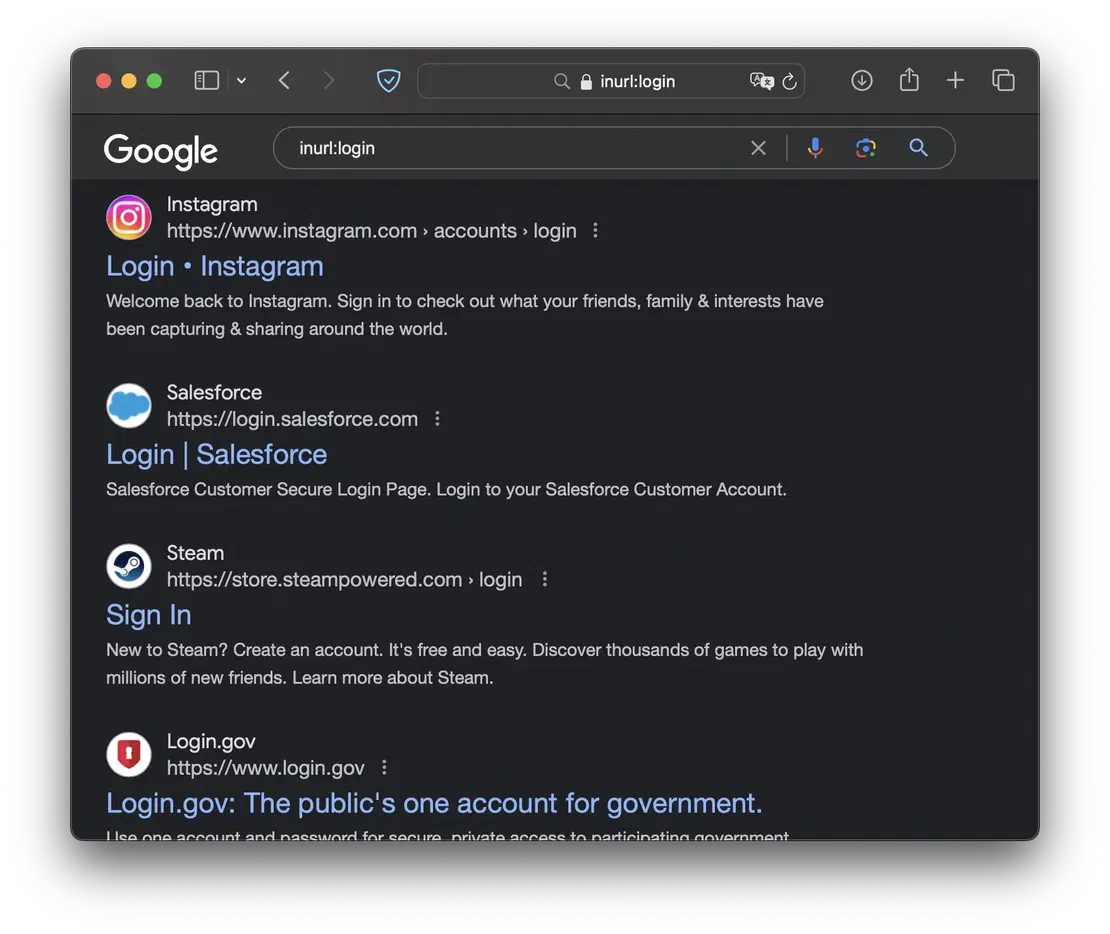
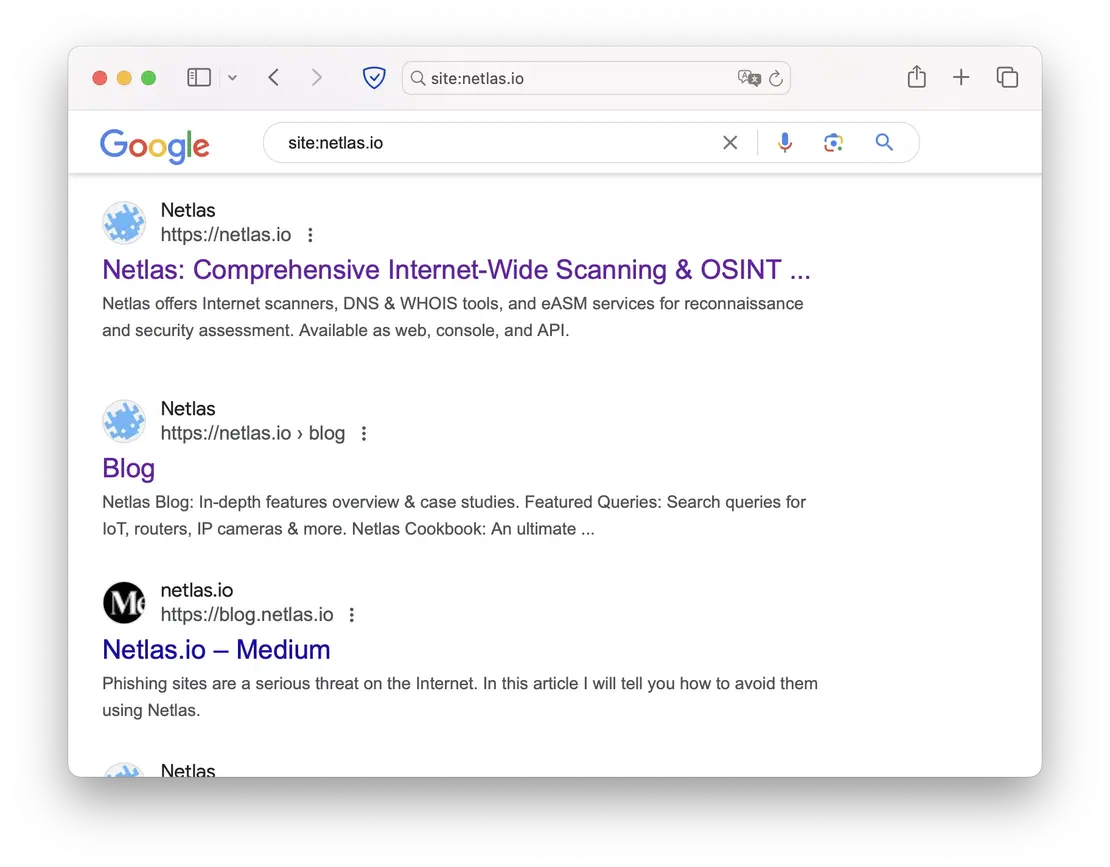
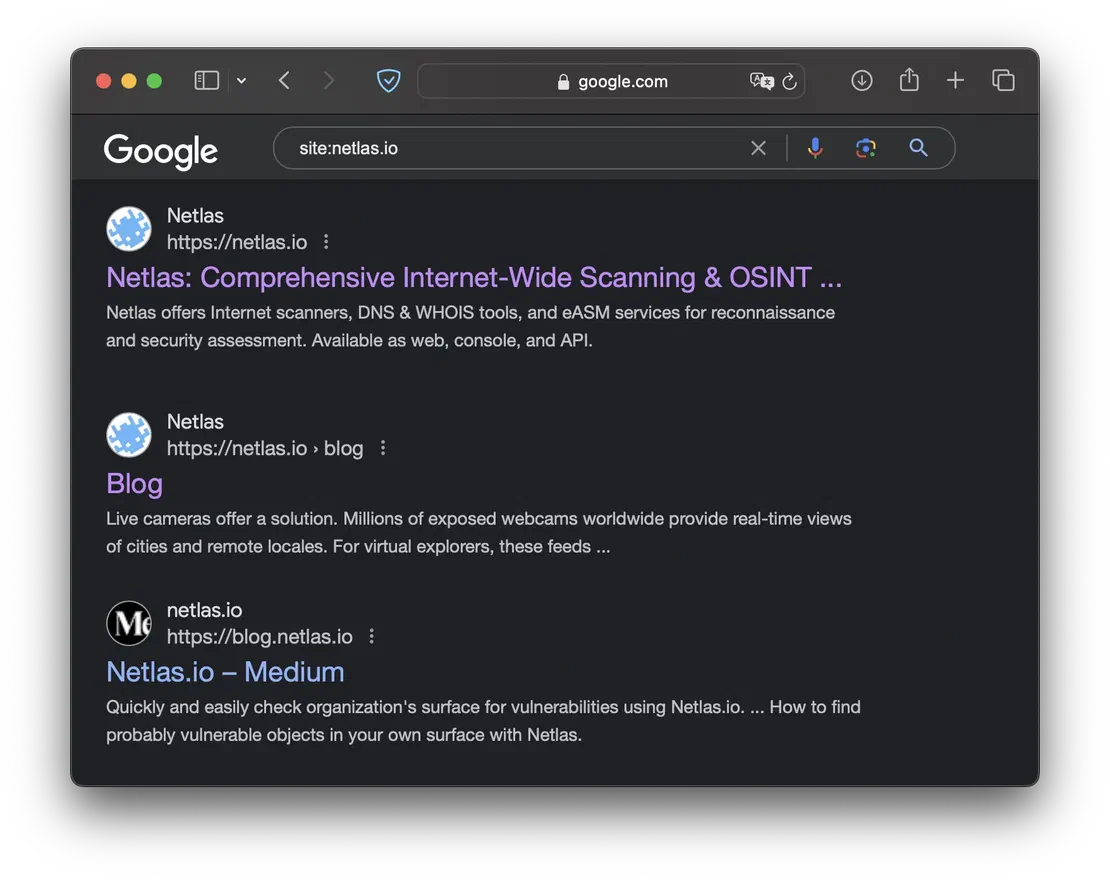
- site
- limits search results to a specific website and its subdomains, allowing you to concentrate solely on the resources of the target company without being distracted by unrelated content.
Logical Operators
When working with Google dorking, you can combine multiple queries into more complex constructs by using various logical operators. The AND operator combines two dorks, returning only results that meet both conditions. It can be particularly useful when you have multiple domains within your scope. The OR returns results that satisfy at least one of the specified queries. You can also use & and | symbols.
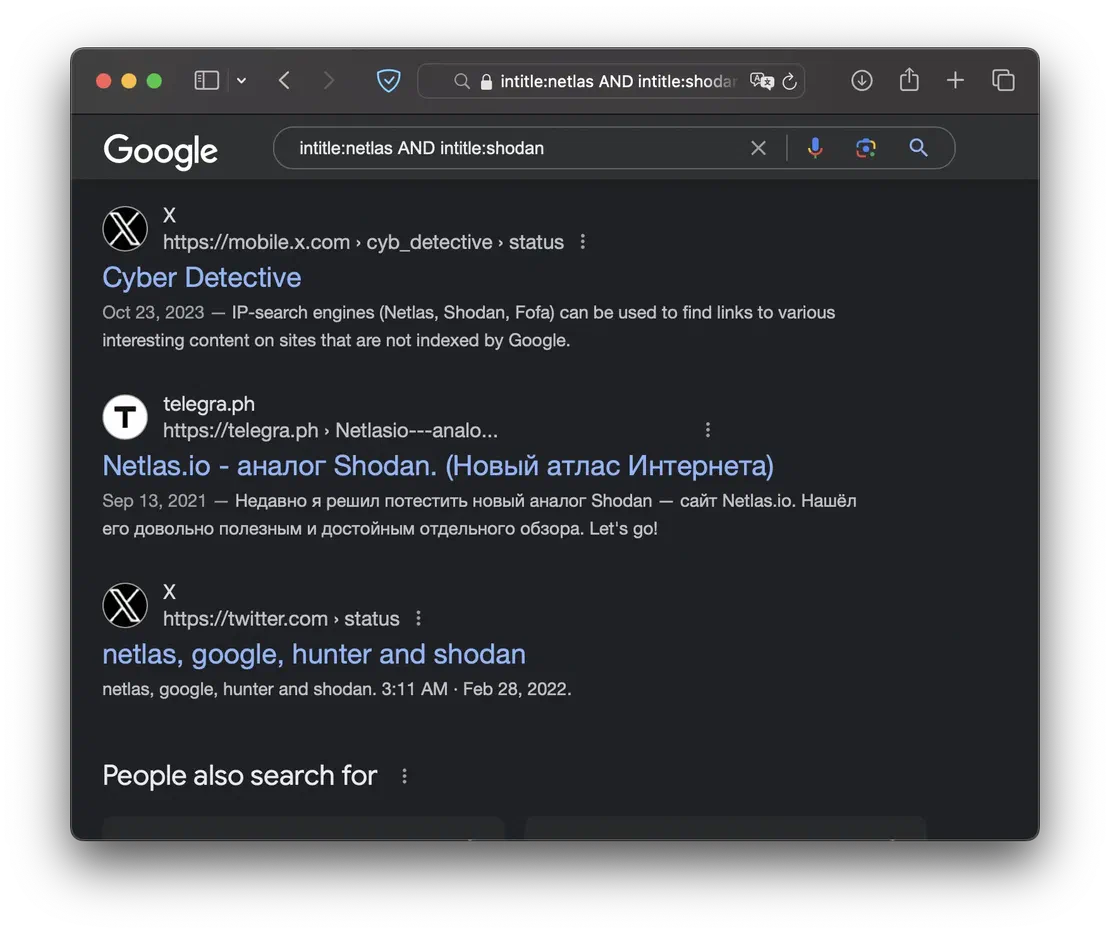
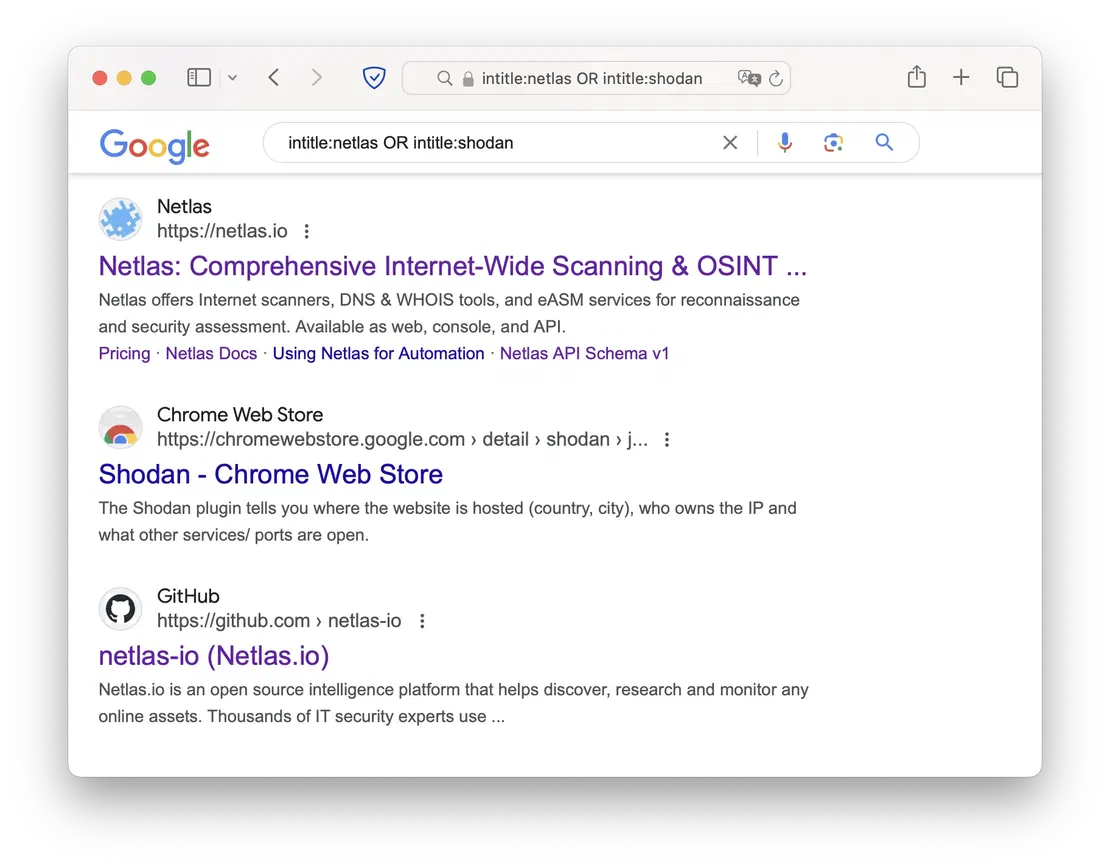
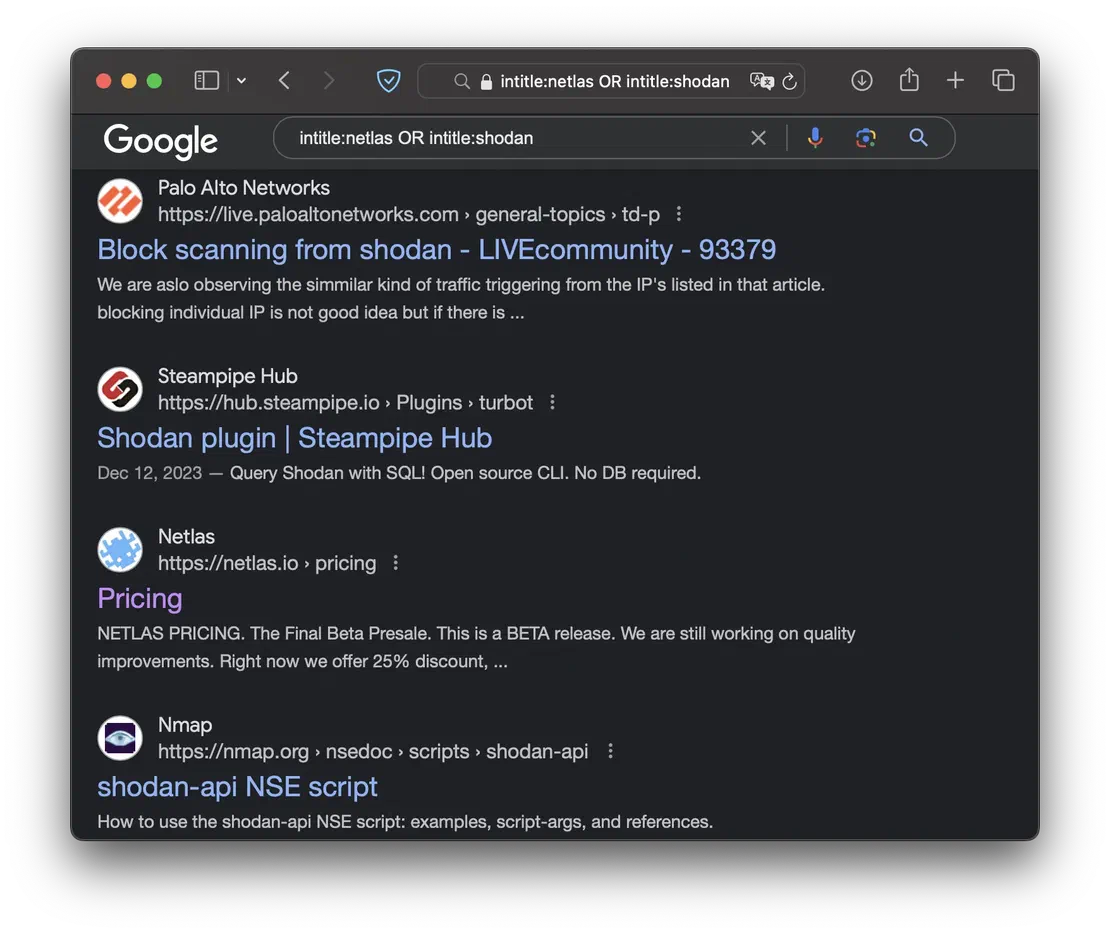
The - symbol acts as a NOT operator. By placing it before a query, you can exclude results that match that query from your search results. For example, you can use it to filter out specific domains or pages.
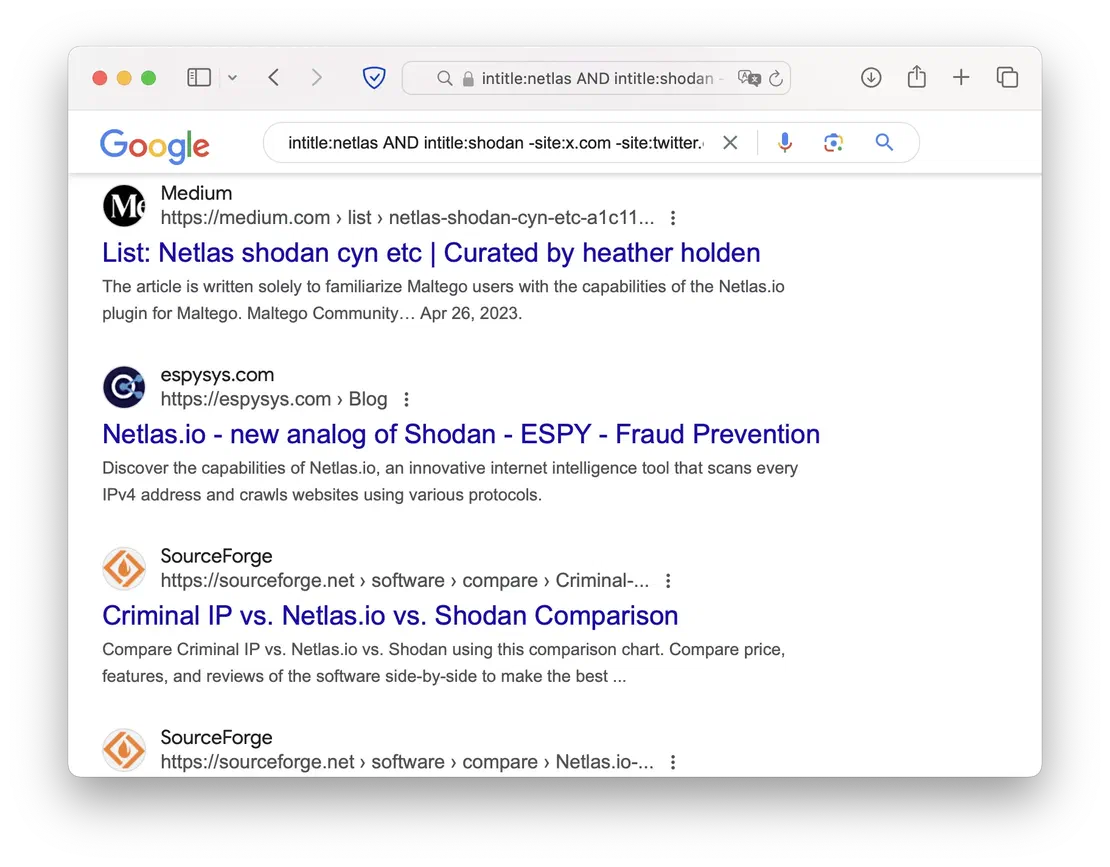
Using Google Dorking
So, let’s move on to use cases. In this section, we’ll explore the most common applications of Google dorking in the context of information security, along with some practical examples.
Google Dorking Techniques for OSINT
OSINT (Open Source Intelligence) involves gathering data about a company, individual, or other target by working with publicly accessible sources. The primary tool for an OSINT investigator is the Internet, including search engines. By leveraging Google dorking, a researcher can customize search queries to efficiently locate the required information.
Mentions Search
The first and most straightforward application of Google dorking in OSINT is searching for references to a person or company across the Internet. All you need is the name or nickname of your target. Here are some example dorks that can be utilized for this purpose:
"John Doe"allintitle:"John Doe"allintext:"John Doe"inurl:"NickName"
However, the mentions might be too numerous or irrelevant. In such cases, it makes sense to narrow the scope of your search. For instance, if you want to find a person’s LinkedIn account, you can refine your query accordingly.
allintext:"John Doe" & site:linkedin.comSimilarly, you can use Google dorks to find profiles on platforms like Twitter, Reddit, and others by refining your search terms.
By combining the target’s name with additional keywords, you can search for contact information, such as:
"John Doe" "contact information"allintext:"John Doe" AND intext:"phone number"By using the various dorks described in the first section, you can gather all relevant mentions of the company or person you’re investigating.
Related Documents Search
The next use case involves searching for documents related to your target. As you may have guessed, we’re going to focus on the filetype dork.
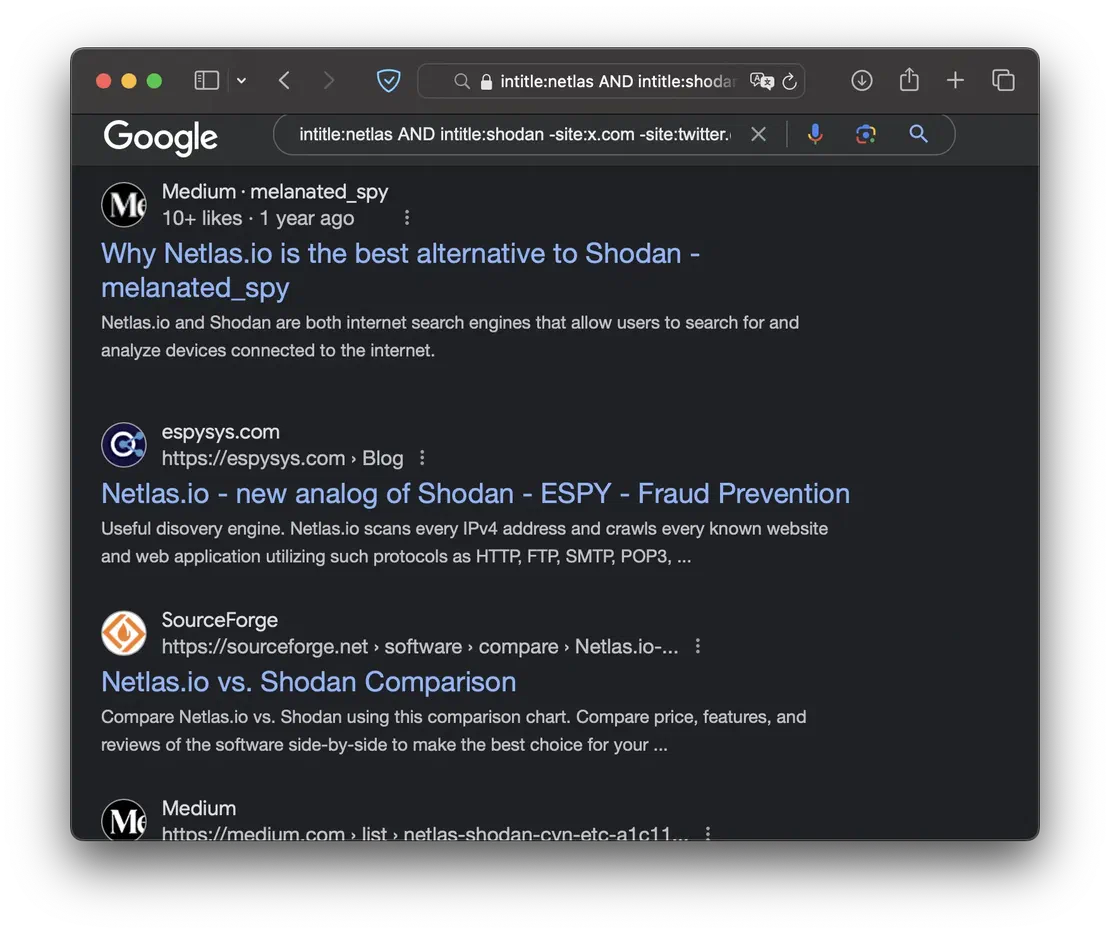
Let’s begin by searching for documents on a specific website. I’ll use arxiv.org as an example, as it often contains a large number of PDFs:
site:arxiv.org filetype:pdfThis will return us the following results:
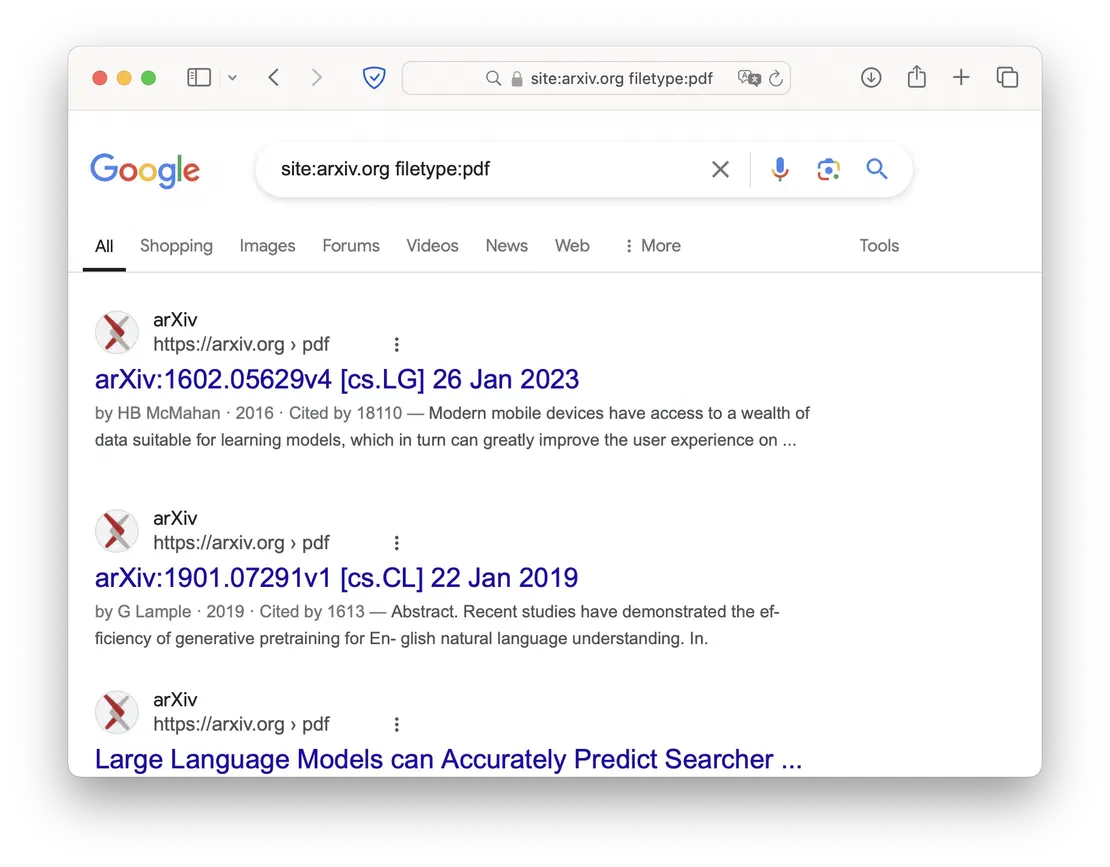
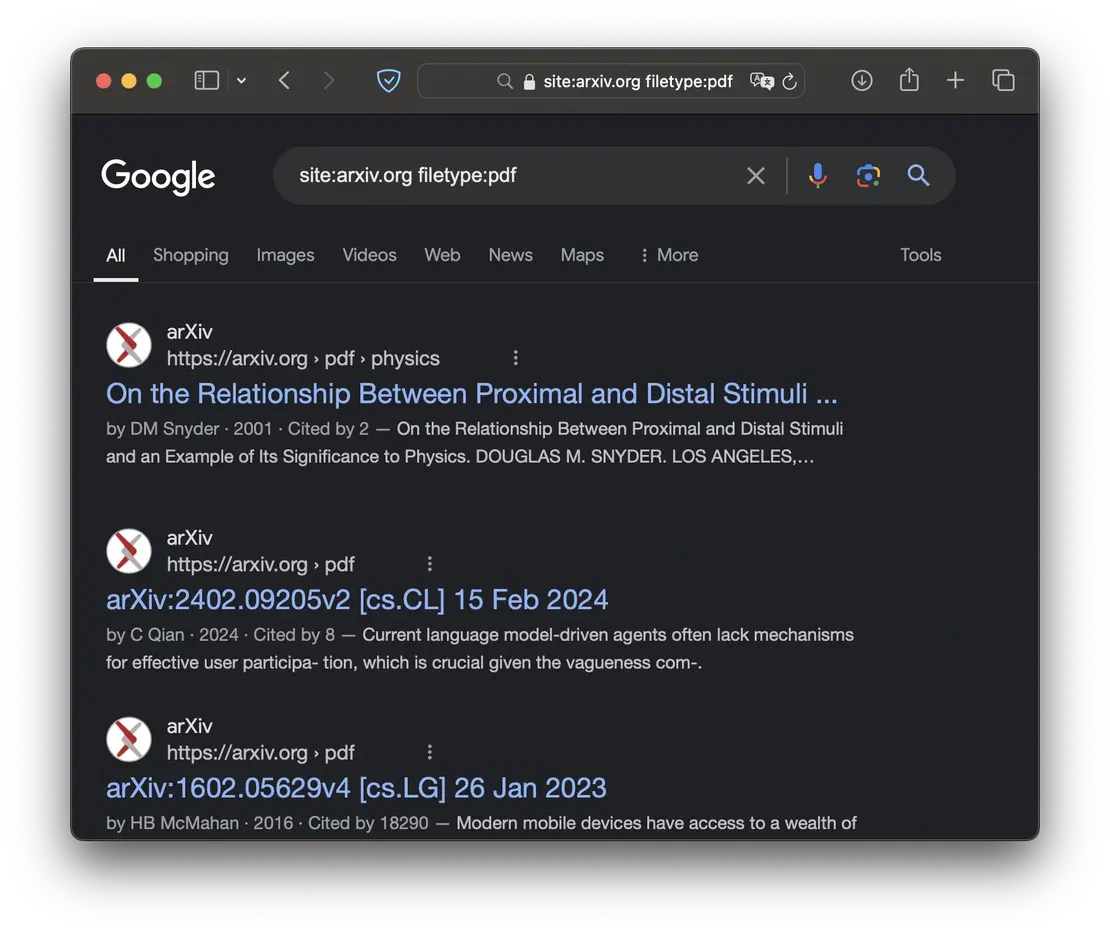
Now, if you want to find documents that mention a specific person or organization, you can use the following dork:
"John Doe" filetype:docxThis way, Google will return all DOCX files that mention the long-suffering John.
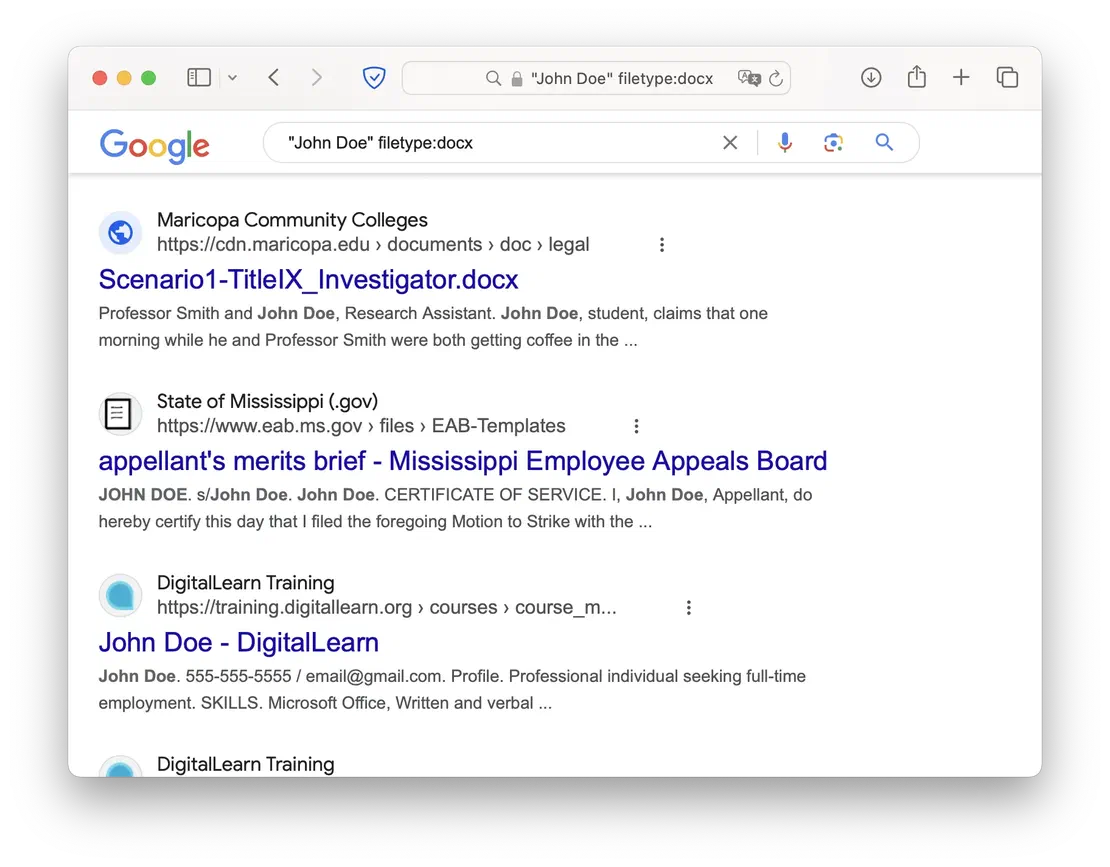
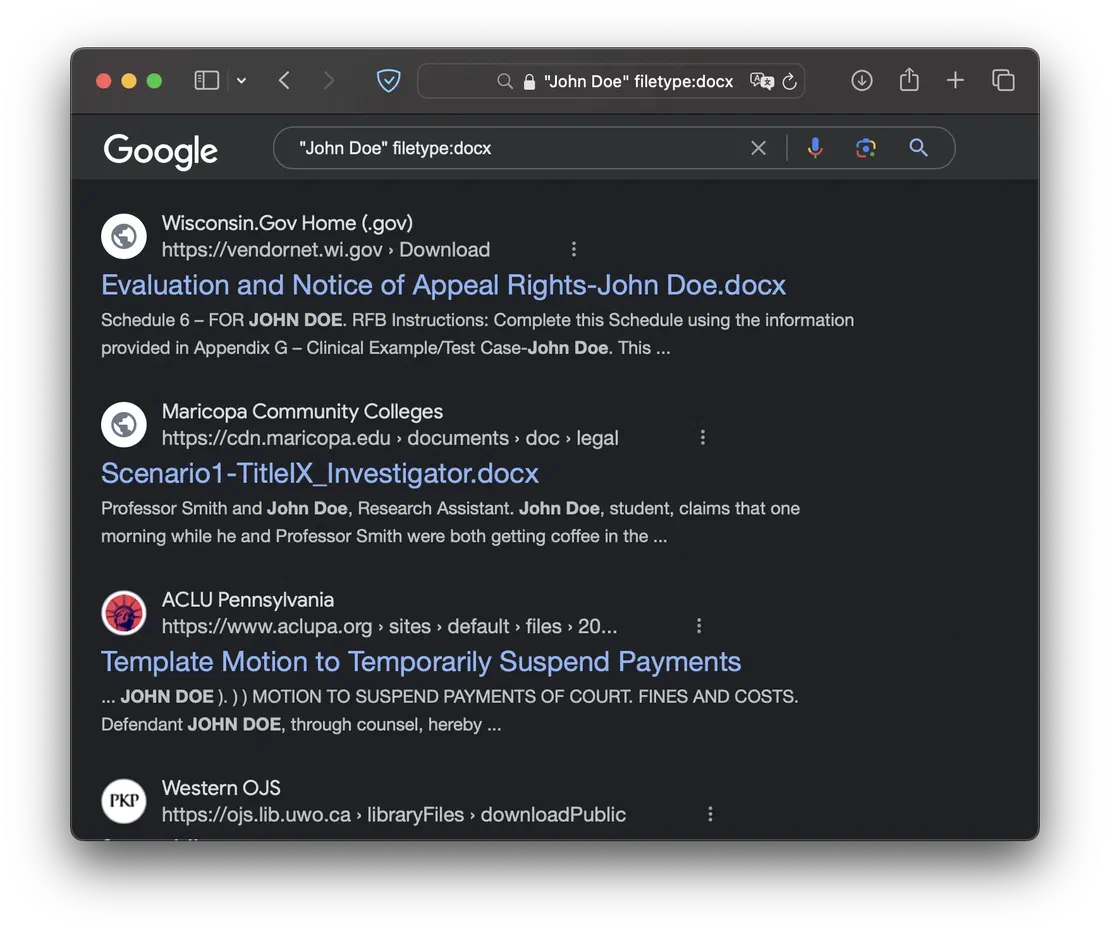
Unfortunately, as previously mentioned, Google doesn’t support dorks for searching many file extensions. The method for handling this limitation will be described in the next use case.
Webcameras Search
Often, during your research, you may want to explore a location without physically visiting it. For this purpose, you can utilize online maps (such as Google Maps) or access live cameras. Google Dorking are particularly effective for locating these cameras.
To detect some camera models or software for them, you can use the following dorks:
- Android IP Webcam -
inurl:"videomgr.html" - Blue Iris -
allintitle:"Blue Iris Login" - etc.
Recommended Reading
Mastering Online Camera Searches

Google Dorking Techniques for Penetration Testing
The second use case we’ll cover in this article is penetration testing, specifically the reconnaissance phase before a pentest. With Google Dorks, you can easily search for potential entry points, such as login pages, services on a domain, or input forms. Let’s examine each of these use cases in more detail.
API Endpoints Search
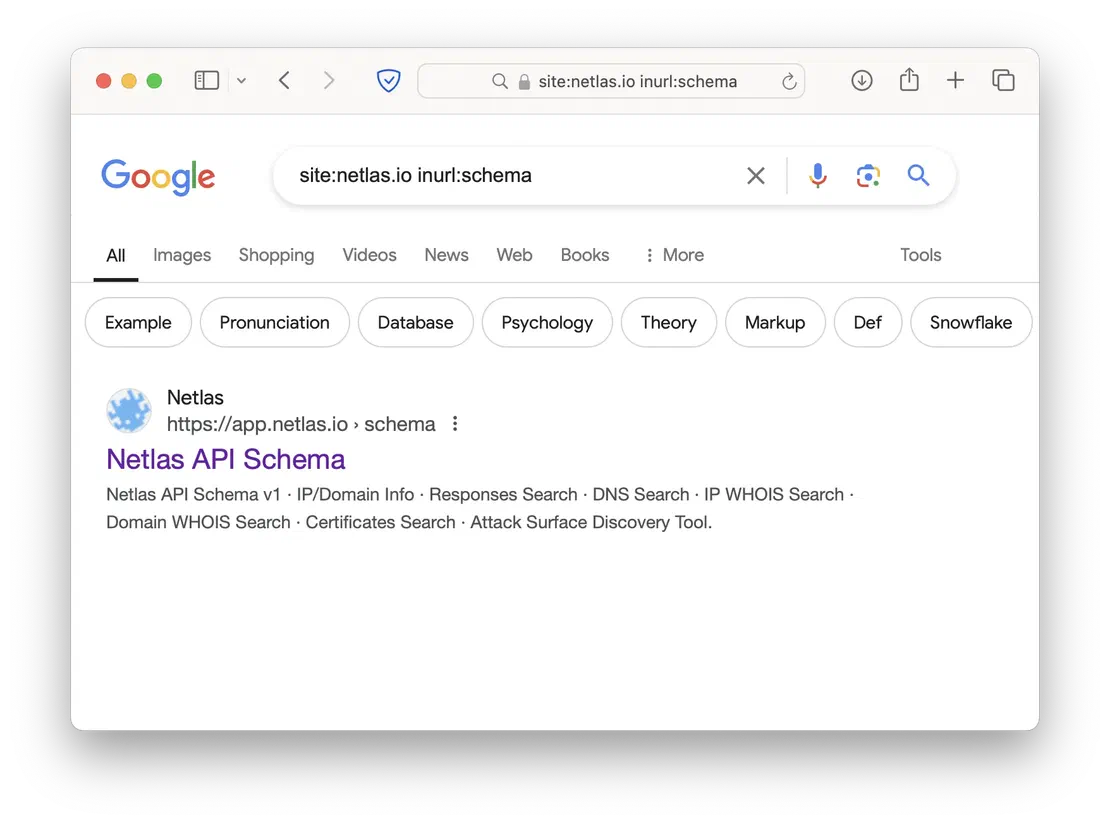
When testing any web application, the API is often one of the most critical entry points. If developers haven’t sufficiently secured endpoints or have left access to restricted ones, this can significantly compromise the application’s security. To find such endpoints, you can use one of the following dorks:
site:example.com inurl:apisite:example.com inurl:schema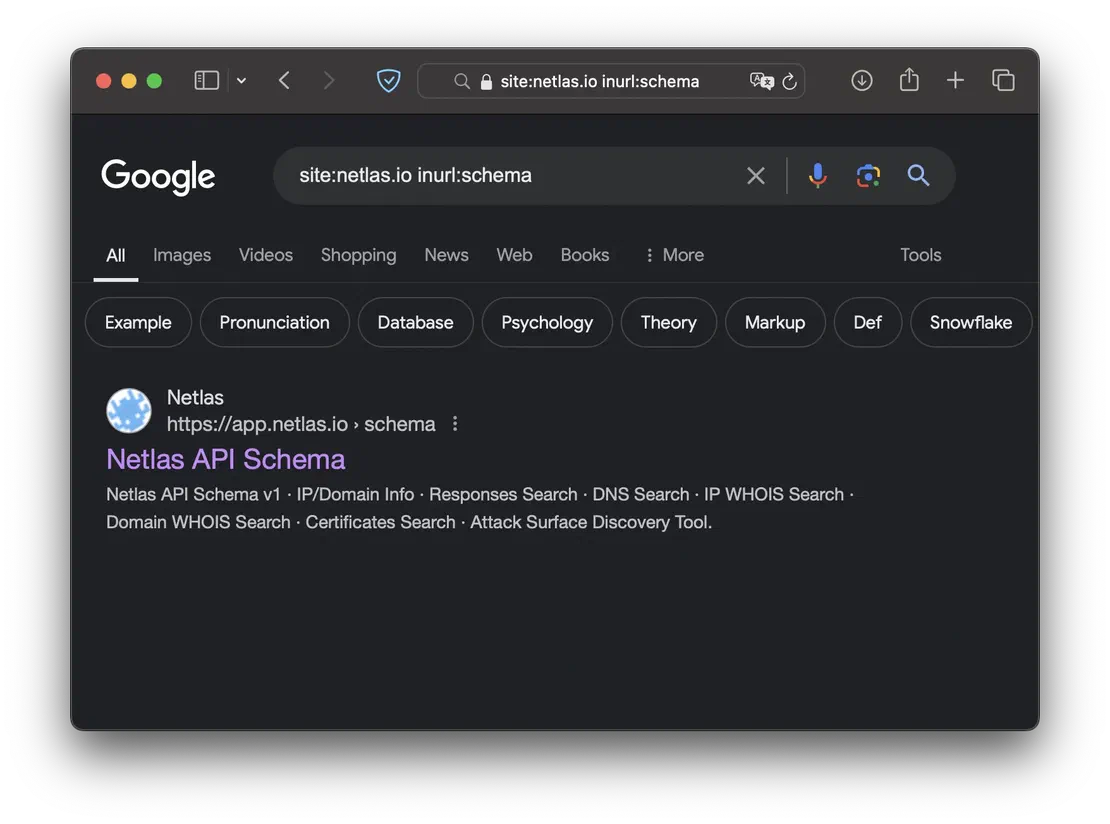
Probably XSS
To execute an XSS injection, an attacker needs to find a vulnerable input form where code can be inserted. Such input is often reflected in the URL of the page, making it easier to detect with Google Dorking.
site:example.com inurl:q=site:example.com inurl:s= | inurl:query=Sensitive Files
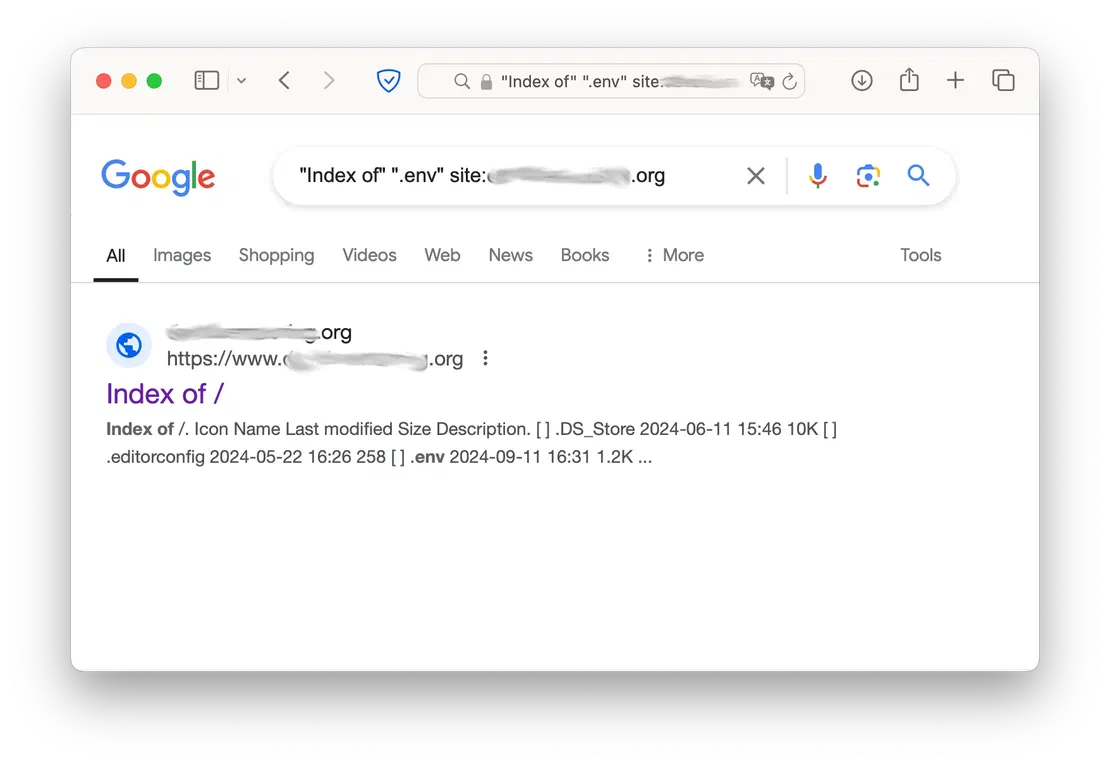
The topic of file searching was previously covered in the OSINT section. However, as mentioned earlier, not all file extensions can be located using the filetype keyword. During a pentest, you may want to find “technical” files, such as logs, environment settings, and more. To discover these files, you can use a dork like the following:
intitle:"Index of" ".env" site:example.com"parent directory" ".log" site:example.com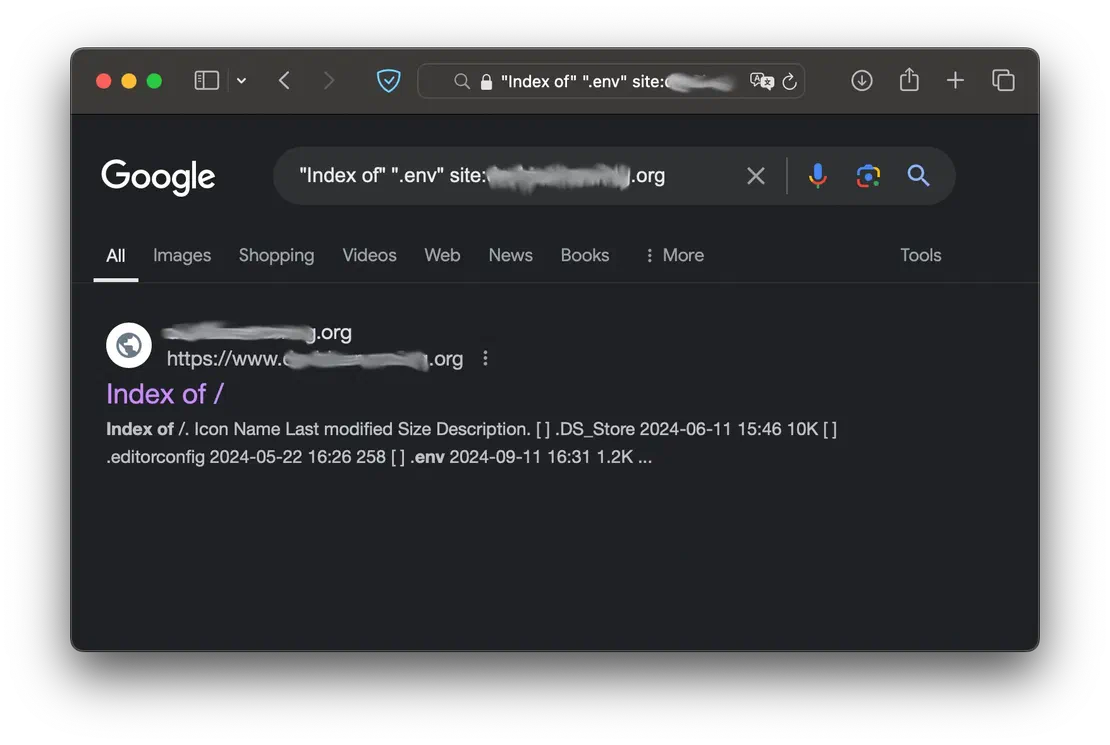
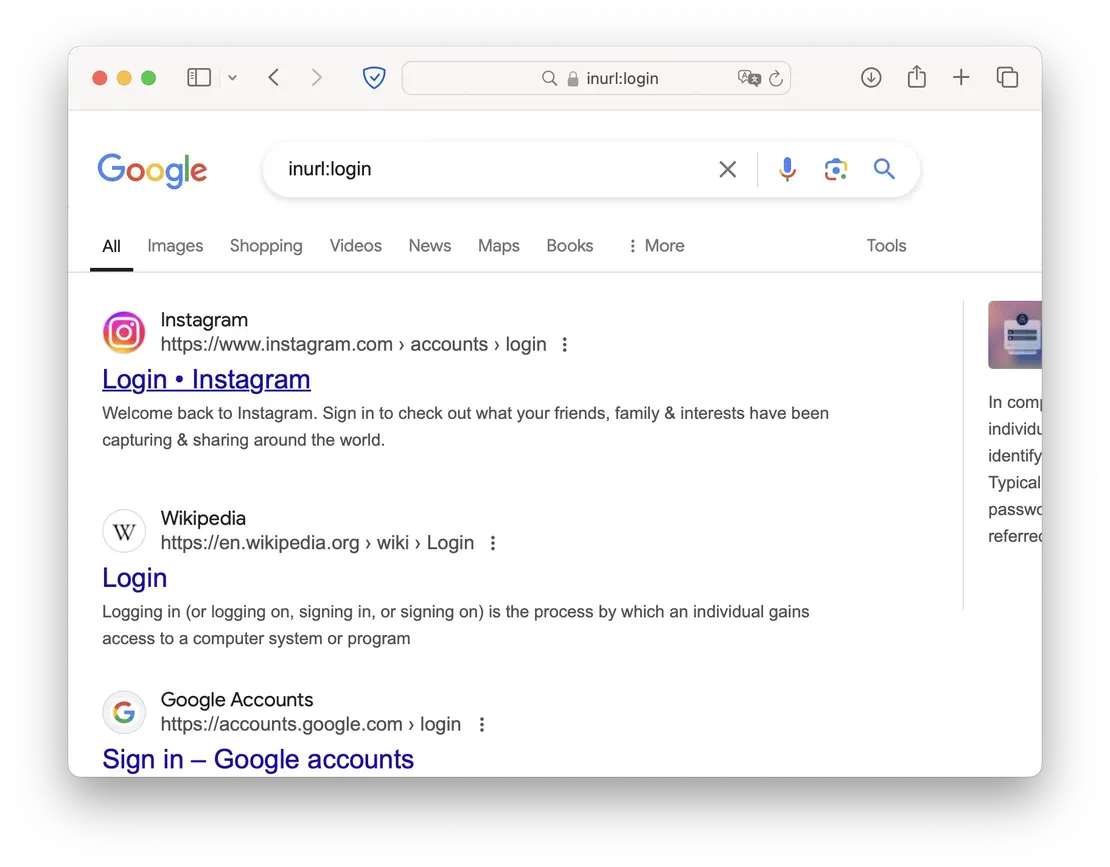
Login and Services Pages
Equally important is finding authorization pages and domain services with distinct URLs. These dorks are straightforward to use—you just need to know what elements to look for in the page URL.
inurl:login site:example.cominurl:signin site:example.com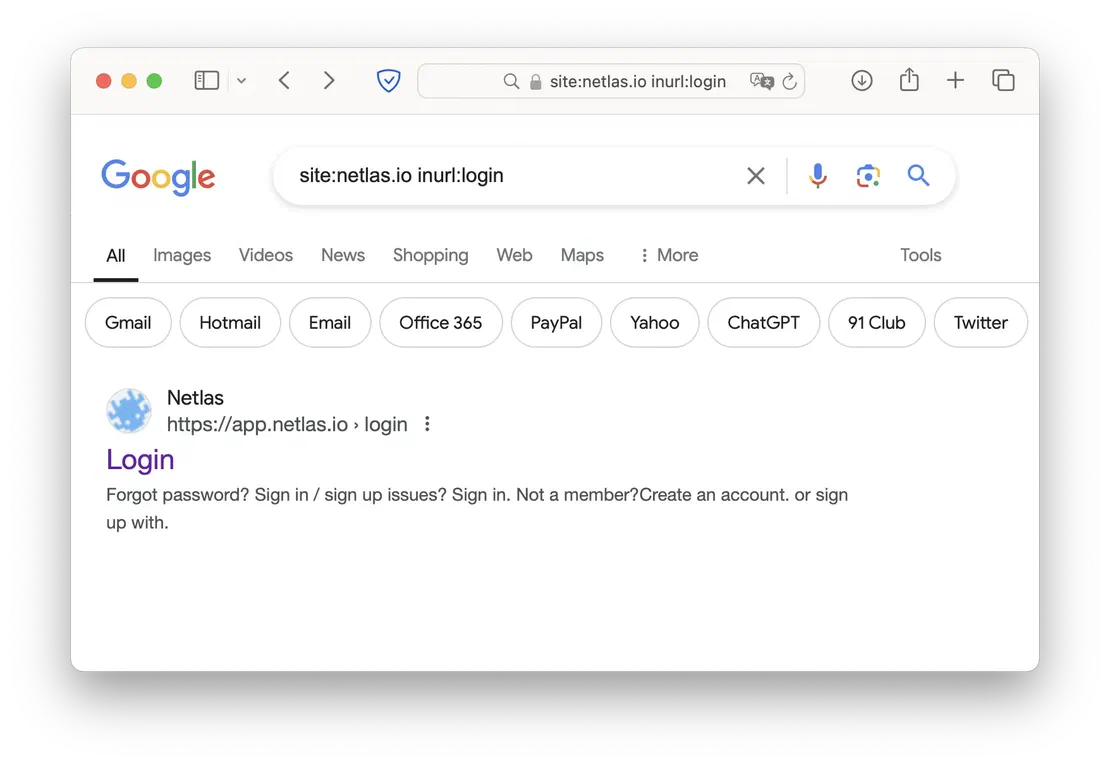
Unlocking Insights with Google Dorking
Google Dorks offer a wide range of practical applications beyond just cybersecurity, including use cases in SEO, marketing, competitive research, and information gathering. Whether you’re interested in exploring specific domains, uncovering pages with relevant keywords, accessing cached versions of websites, or even pulling data from specialized devices like Weather Wing, Google Dorks can help you access targeted content.
In SEO and marketing, leveraging Google Dorks as part of your content optimization strategy can greatly improve your ability to explore competitor websites, identify valuable SEO opportunities, and refine your keyword strategies. This method streamlines the process of gathering strategic insights, allowing marketers to create more effective and data-driven SEO campaigns.
Additionally, Google Dorks are invaluable in competitive analysis, where they facilitate the extraction of strategic data about competitors. By examining their SEO practices, content marketing approaches, and other tactics, you can gain a deeper understanding of their online presence and gain a competitive advantage in the digital marketplace.
Google Dorking Automation
Now that we’ve covered the most popular use cases, we can move on to the most exciting part of this article — building automation. Manually entering these dorks for each target can be tedious, especially if you have a large scope. In the following section, I’ll create the skeleton of a script that you can easily modify and use in practical scenarios.
First Scripts
First, you need to choose a programming language and the necessary libraries. For this example, I used Python 3.11, and the main module will be googlesearch. To install it, enter the following command in your terminal:
python3 -m pip install googlesearch-pythonGreat! Now, you can import the module into your project and make your first Google search request directly from your code:
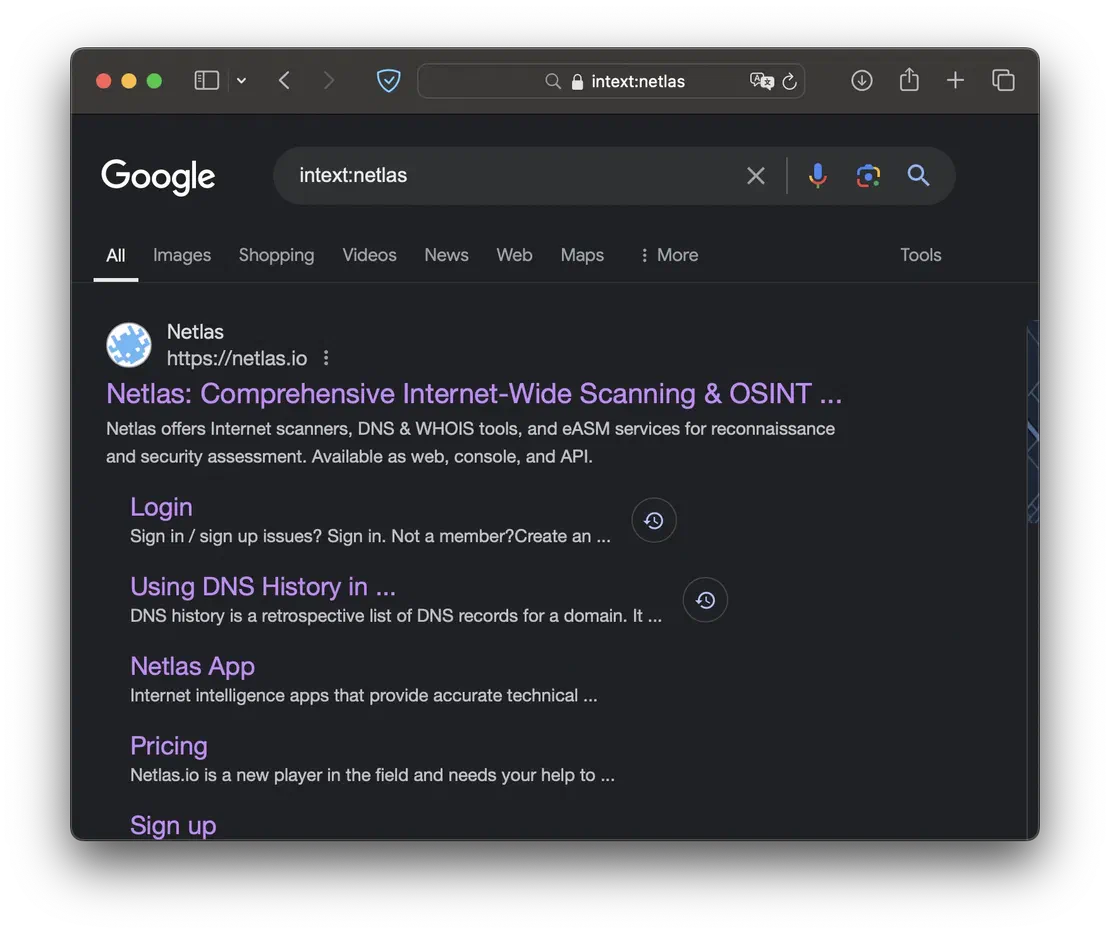
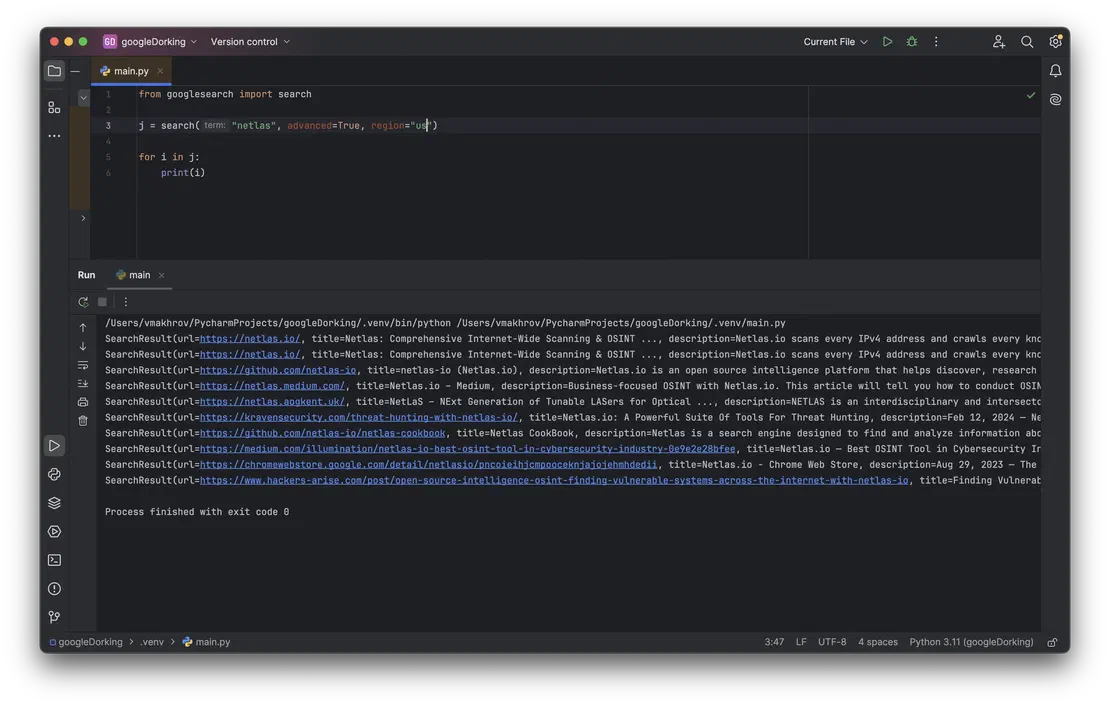
from googlesearch import search
j = search("netlas", advanced=True)
for i in j:
print(i)Here I requested the word “netlas”. The advanced parameter is needed in order to get results in all details: URL, title, description. The result of running the script is shown in the following image.
A good start! Now that we can retrieve results from Google search without a browser, let’s enhance the script’s functionality. We need to add more complexity to the query by incorporating different patterns and create a simple input system to allow the user to specify a scope.
Complex Patterns
While I was writing this article, I came across a list of Google Dorks specifically for bug bounty that was compiled by Mike Takashi. You can prepare your own patterns, but as an example I will take queries from this list, since they cover a large layer of the needs of a pentester.
Input/Output
Now that we have figured out what to do and roughly how to do it, we need to figure out what we will do it with. In my version of the script (simplified and educational), the following will be submitted to the input:
- File with domain names for research.
- Output format (YAML/JSON).
- Number of results collected for one request.
The script will output the data to the console so that the user can redirect the output stream to any desired location.
What format will the data be output in? It will be a dictionary of dictionaries, looking something like this:
Domain_Name_1:
| Search_Pattern_1:
| URL_1: Description_1
| URL_2: Description_2
...
| URL_k: Description_k
| Search_Pattern_2:
| ...
Domain_Name_2:
| ...This format will allow us to clearly structure the data, after which it can be easily read in JSON or YAML formats.
Main Request Function
Next, we will write the main function that will be responsible for requests. In the first version of the script, I made many such functions that were as similar as two peas in a pod. However, this is bad form, so there will be nothing like that here. We will limit ourselves to just this:
def oneRequest(query, count):
responseDict = {}
j = search(query, advanced=True, num_results=count)
for i in j:
responseDict[i.url] = i.description
return responseDictIn this function, we create a dictionary of the lowest level, where we enter key:value pairs. The URLs of pages corresponding to the request will act as keys, and their descriptions will act as values. The maximum number of values, as already mentioned, is fed to the script as input.
Queries Hub
Next, we need to submit requests to the function from the previous paragraph. I decided to make it as simple as possible by passing them this way:
def functionHub(site, resultsCount):
domainDict = {}
domainDict["API Endpoints"] = copy.deepcopy(oneRequest("site:" + site + " inurl:api | site:*/rest | site:*/v1 | site:*/v2 | site:*/v3", resultsCount))
time.sleep(10)
#...
return domainDictHere we are creating a dictionary that will contain all the information about the domain. Next, the URLs of the results that satisfy the request are written into the values of this dictionary. Between each of the oneRequest() function calls I set a timer of 10 seconds. This is necessary to prevent Google from blocking your IP address due to frequent use of dorks.
Fighting Blockages
As I mentioned in the previous point, Google will block your IP if you try to make queries containing dorks too often. It will look something like this:
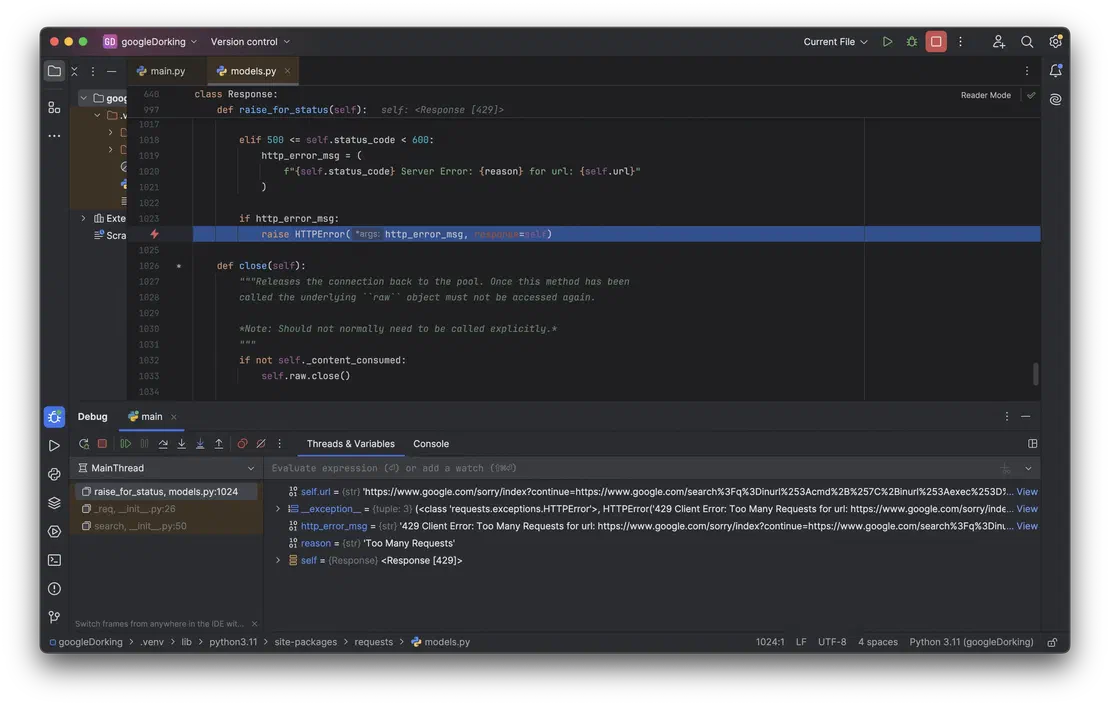
Unpleasant. And what’s even more unpleasant is that this problem is not solved by timeouts. More than 10 seconds passed between my requests, but this did not prevent Google from blocking me.
However, there is a solution. You can use a rotating proxy and change IP addresses before the search engine considers the script’s activity suspicious. In this article, I will not provide instructions for setting up this mechanism, I will only mention that the library we use supports it. In code, it looks something like this:
from googlesearch import search
proxy = 'http://API:@proxy.host.com:8080/'
j = search("proxy test", num_results=100, lang="en", proxy=proxy, ssl_verify=False)
for i in j:
print(i)Final
I won’t describe the rest in sufficient detail, since only technical nuances remain. We will need to set up an argument parser to run the script from the command line. In addition, the functionality for outputting results and processing the input file will be written. You can find the full script code in our GitHub repository.
Finally, let’s look at the results. As a test subject, I chose the site google-gruyere.appspot.com, which was intentionally made vulnerable to train information security specialists. The results of running the script are shown in the following image.
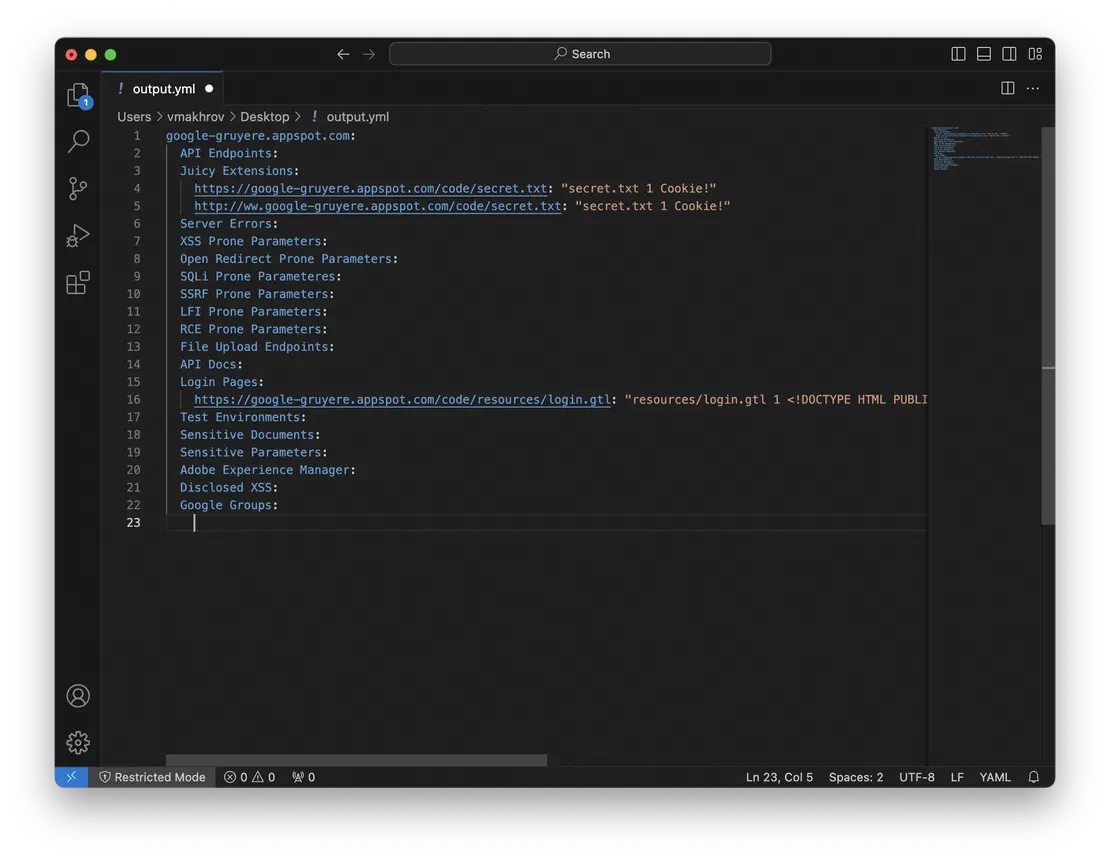
You may notice that the results are somewhat limited… and you would be correct. My own instance of Google Gruyere doesn’t last long, and testing the script on live, functioning sites can pose security risks and ethical concerns. As a result, the example above serves more as a demonstration of the code’s functionality than as an operational success.
If you decide to test this script in your work and share your feedback in the comments, I would be extremely grateful!
Additional Search Engines
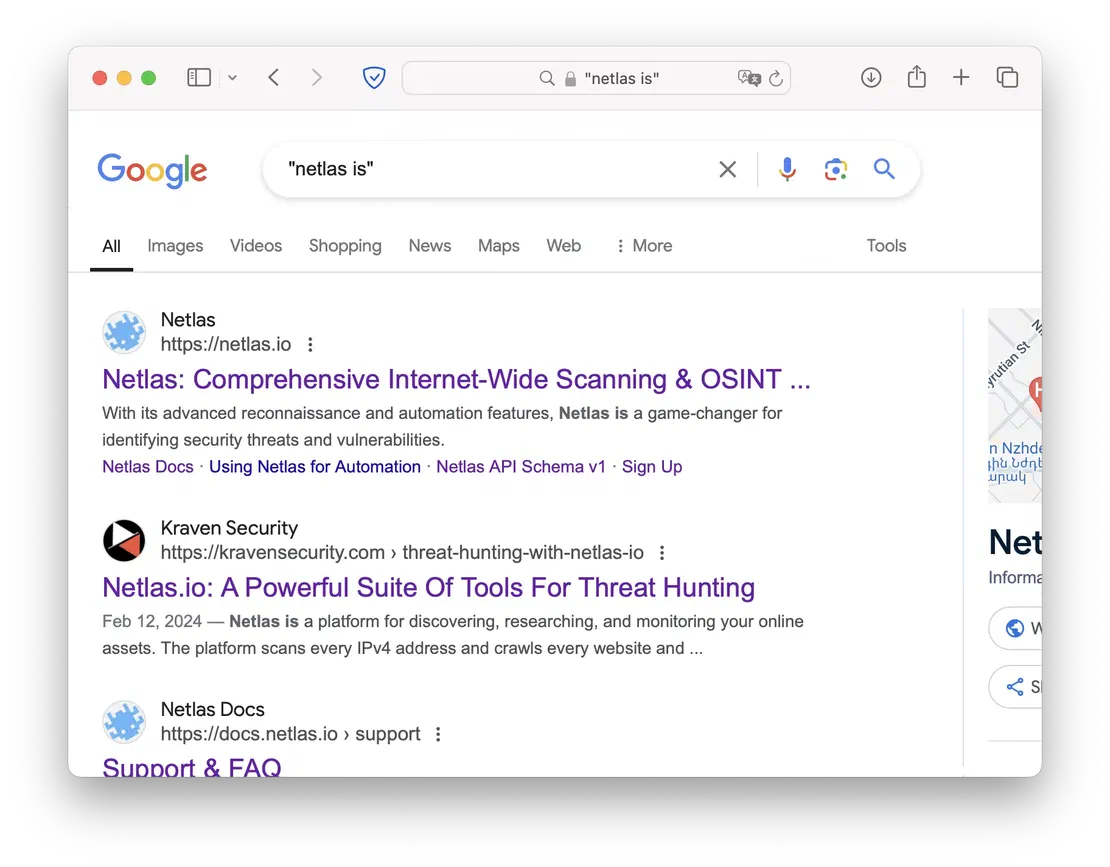
This concludes the part of the article dedicated to Google dorking. This is a very powerful tool that allows you to detect rather unobvious objects using only a Google search. However, you can supplement your search results by using other search engines. For example, Netlas.io.
Having a not so abundant data set, Netlas can provide great search opportunities. Thus, it allows you to both replace some of the dorks with your own requests, and create completely new ones. For example, the replacement might look like this:
- intitle -> http.title
- intext -> http.body
- etc.
Here is an example of similar requests in Netlas:
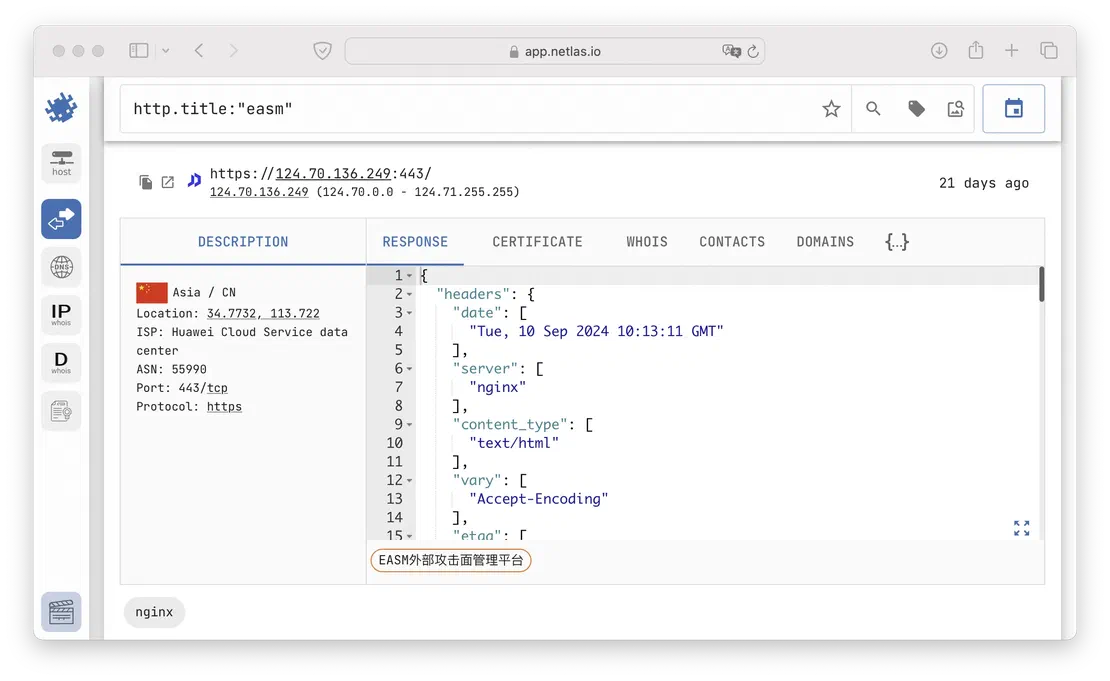
However, this search is not very interesting. It would be much better to consider the additional capabilities of Netlas. These include:
- Search by favicons.
- Search by software used on server.
- By protocol.
- By SSL certificates fields.
- By WHOIS data.
- etc.
Search examples:
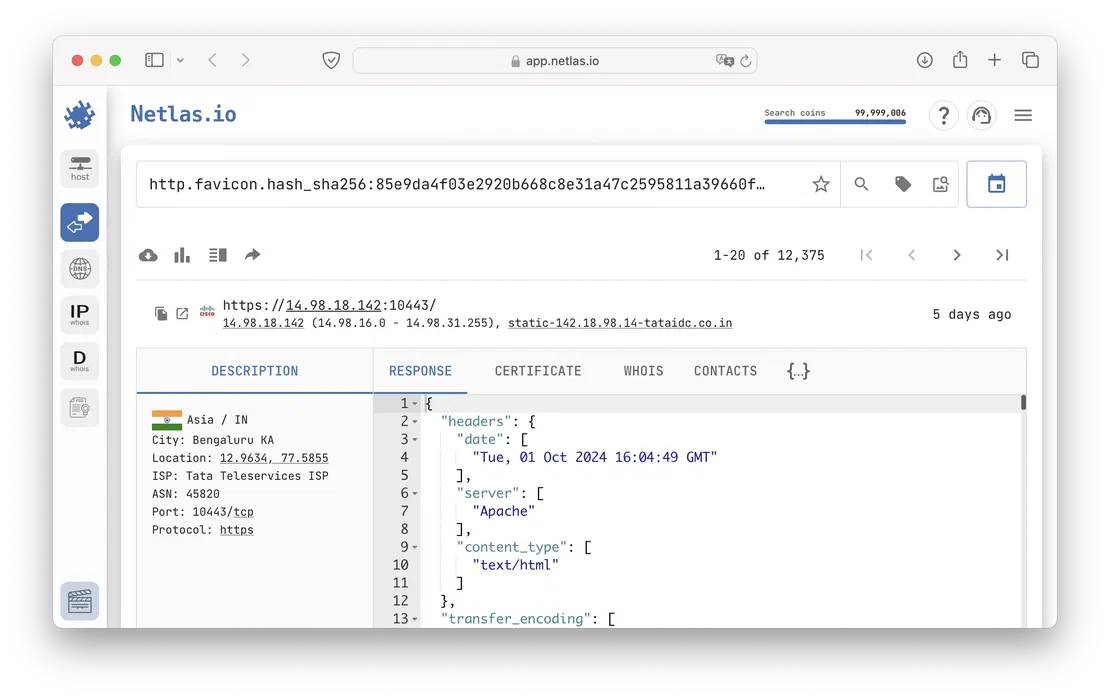
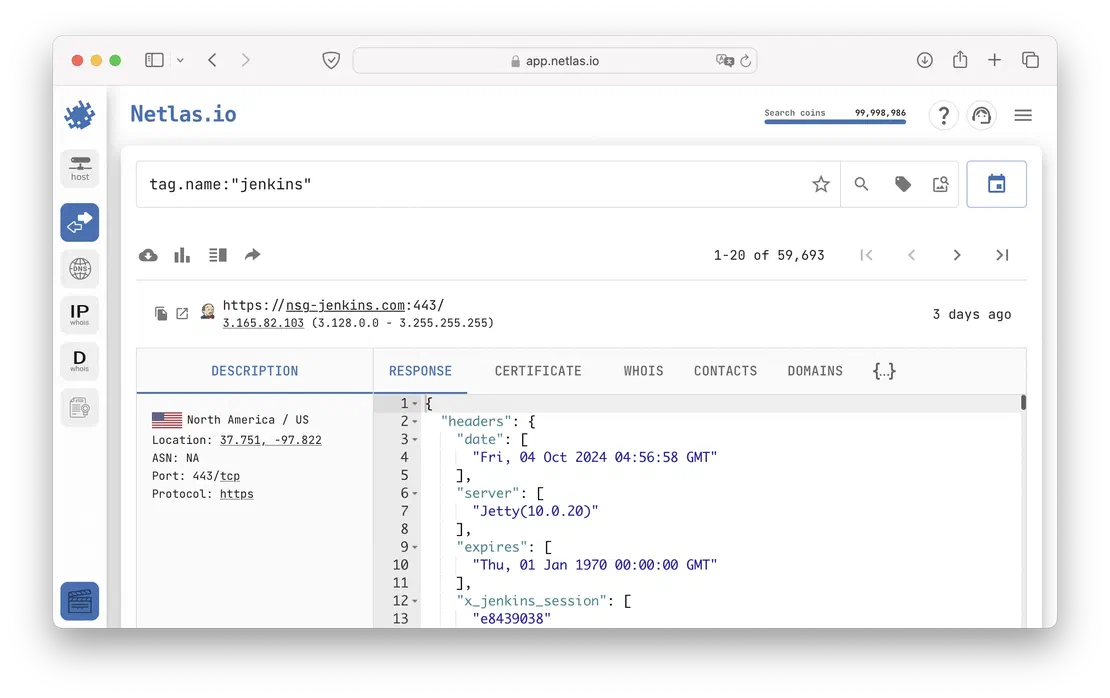
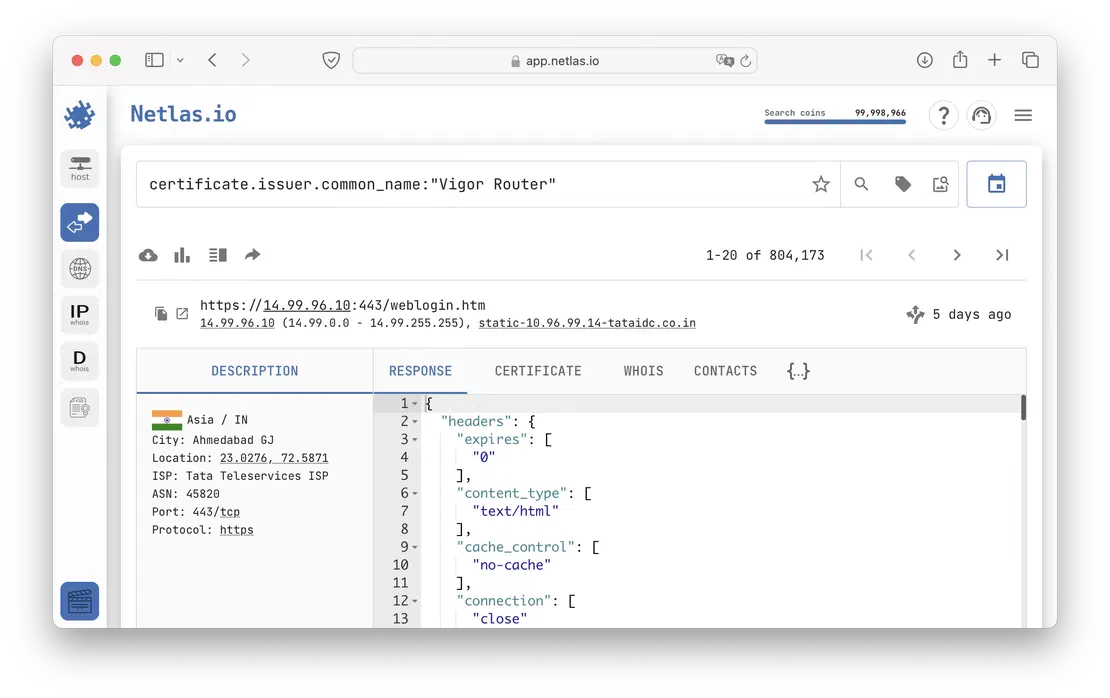
Using these and thousands of other queries, the user can greatly enhance the data obtained while working with Google dorks, especially when it comes to pentesting or building an Attack Surface.
Another advantage of Netlas and similar search engines (for example, Shodan or Censys) is the fact that they ignore the restrictions imposed on search robots. Thus, Google does not touch the resources mentioned in the robots.txt file during crawling. IoT search engines don’t care about this, which is why they may store results that cannot be found through Google Search.
Request Your Free 14-Day Trial
Submit a request to try Netlas free for 14 days with full access to all features.
Minimizing Exposure to Dorks
As demonstrated above, Google Dorks enable anyone — be they a threat actor or a security researcher — to uncover information that appears hidden at first glance. So the question becomes: how do you shield your assets from this form of reconnaissance?
This section will dive into exactly that.
Preventing Dork Google Exploits at the Source
To protect your website from Google Dorking, employing effective access control methods is essential. One of the key techniques is using access management protocols like robots.txt, which can restrict the indexing of sensitive files and directories by search engines. This file, placed in the root directory of your web server, allows you to set rules that prevent certain resources from being discovered through search queries.
Although relying on access controls like robots.txt can be considered a form of “security through obscurity”, it’s an important step in directing search engines away from sensitive content. By doing so, you can minimize the chances of private data being exposed to the public. However, it’s important to recognize that while these controls limit access for search engines, they may not be fully foolproof. Combine these techniques with additional security measures to ensure comprehensive protection.
Here are some practical ways to enhance your site’s security with robots.txt:
- Block Sensitive Directories Prevent search engines from accessing directories that may contain private or confidential information.
User-agent: *
Disallow: /admin/
Disallow: /config/
Disallow: /includes/
Disallow: /backup/
Disallow: /private/- Restrict Specific File Types Disallow the indexing of specific file types that might contain sensitive data.
User-agent: *
Disallow: /*.config$
Disallow: /*.sql$
Disallow: /*.log$
Disallow: /*.bak$
Disallow: /*.json$- Block Sensitive URL Parameters Prevent search engines from indexing URLs that contain parameters potentially revealing sensitive information.
User-agent: *
Disallow: /*?secret=
Disallow: /*?admin=
Disallow: /*?config=
Disallow: /*?backup=Implementing these robots.txt rules can go a long way in reducing the risk of exposing sensitive content to search engines. However, it’s important to understand that robots.txt is just one tool in your cybersecurity toolkit. To fully protect your site, use it alongside other access control techniques, such as HTTP authentication, encryption, and regular security audits.
Blocking Google Dorlk Un Search Attempts
One of the most important steps in protecting your website from Google Dork searches is disabling directory indexing. When directory indexing is left enabled, visitors who navigate to a directory without an index file can easily view all the files and subdirectories contained within. This makes it much easier for both search engines and malicious users to uncover sensitive content. Disabling this feature prevents unauthorized browsing of your directories.
To disable directory indexing, add this simple line to your .htaccess file:
Options -IndexesThis command instructs the web server to block directory listings. If someone attempts to access a directory without an index file, they will receive a “403 Forbidden” error. This is a straightforward and effective method for ensuring that your sensitive files and directories remain concealed from unwanted attention.
Conclusion
So, in this article we looked at using Google dorking both manually and in automated way, and also touched on one of the possible analogues. At the end, we can briefly summarize the main points:
- Google dorking is a powerful tool that allows you to accomplish many tasks using just a search bar.
- Using dorks, you can carry out reconnaissance before pentests, as well as conduct OSINT investigations.
- Working with dorks can be automated in the form of scripts.
- An analogue of using Google dorking can be working with various Internet search engines, such as Netlas, Shodan, Censys, etc.
Finally, I would like to remind you once again that while Google dorking is legal, it can easily allow you to access sensitive files or web pages that are not intended for public use. Be careful and remember to follow the laws.

Book Your Netlas Demo
Chat with our team to explore how the Netlas platform can support your security research and threat analysis.
Related Posts

March 30, 2026
Mastering Online Camera Searches

October 9, 2024
Complete Guide on Attack Surface Discovery

September 13, 2024
7 Tools for Web Penetration Testing

August 30, 2024
Using DNS History in Cybersecurity

July 20, 2026
Best Attack Surface Visualization Tools

August 1, 2025
Hannibal Stealer: A Deep Technical Analysis



