








Netlas CookBook


The goal of this guide is to teach anyone interested in cybersecurity, regardless of their knowledge level, how to make the most of Netlas Search Tools. This is a long read. We have collected as many simple use cases as possible and demonstrated how to automate them.
⭐️ Give us a star to show your appreciation
👁️ Subscribe for updates
Netlas is a search engine designed to find and analyze information about all IP addresses and domains available on the Internet. Netlas has some attack surface management features, but this guide focuses mostly on Netlas Search Tools and how to use them in automations.
Table of Contents
- Simple Usage Examples
- Search Query Syntax
- API Requests
- How to Find the API-key?
- Tools for Debugging API Requests
- Structure of Netlas API JSON Response
- Tools for Working with Data in JSON Format
- Netlas Python Library
- Examples of Response Keys for Getting Useful Data
- Netlas Python Response Datatypes
- Netlas CLI Tools
- Search vs Download vs Host Methods
- Additional Request Parameters
- Make Requests with Python (without Netlas Python Library)
- Examples for Other Programming Languages
- JQ Utility
- AI Tools for Writing Code
- Code Checkers
- Using Netlas.io for OSINT (Open Source Intelligence)
- Search Person’s Nickname or Email in WHOIS Contacts
- Search for Person’s Nickname or Email in Title and Body of Web Page
- Search for “Juicy Info Files” on Subdomains of the Company’s Website
- Phone Number Mentions Search
- Search File Mentions (Looking for Content That May be Infringing on Copyrights)
- Domain WHOIS Information Gathering
- Search Location in <address> Tag
- Search Author Name in Meta Tags
- What Other Interesting Things Can Be Found in the Meta Tags of HTML Document?
- Search by FTP Server’s Banners Text
- Search for Contact Information in SSL Certificates
- Using Netlas as an Alternative to the WayBack Machine
- 9 Ways to Search Related Websites
- Scraping (Extract Data from Web Page Body)
- Using Netlas.io for Crypto Investigations
- Using Neltas for Pentest
- Subdomain Search
- Search for Sites with Specific Vulnerabilities
- Search for Sites with Vulnerabilities That Contain a Certain Word in Their Descriptions
- Search by Server HTTP Header
- Search for Vulnerable Servers by Favicon Hash
- Search for Vulnerable Servers by Tag Name
- Search for Vulnerable Servers and Devices Near You (or Any Other Location)
- Search for Login/Admin Panels
- Search for Vulnerable Database Admin Panels
- Search for Sites Vulnerable to SQL Injection
- IoT Search: 9 Basic Ways
- Using Netlas.io for Darknet Research
- Files, Backups and Logs Directories Search
- Using Netlas.io for Digital Forensics and Incident Response
- Search for Technologies and Code Examples
- Using Netlas.io for Fun or Netstalking
- Common Problems
- Attack Surface Management
- Working with Very Large Amounts of Data
- Acknowledgments
Simple Usage Examples
Netlas includes several search tools:
- IP/Domain info →
- Response search →
- DNS search →
- IP WHOIS search →
- Domain WHOIS search →
- Certificates search →
We will mostly use Responses search (internet scan results), but all the tools works in the same way. If you understand how to use Responses Search Tool, you can handle any other.
Before we get into the technical details, let’s see how Netlas.io works with a few simple examples.
Getting Information About IP or Domain
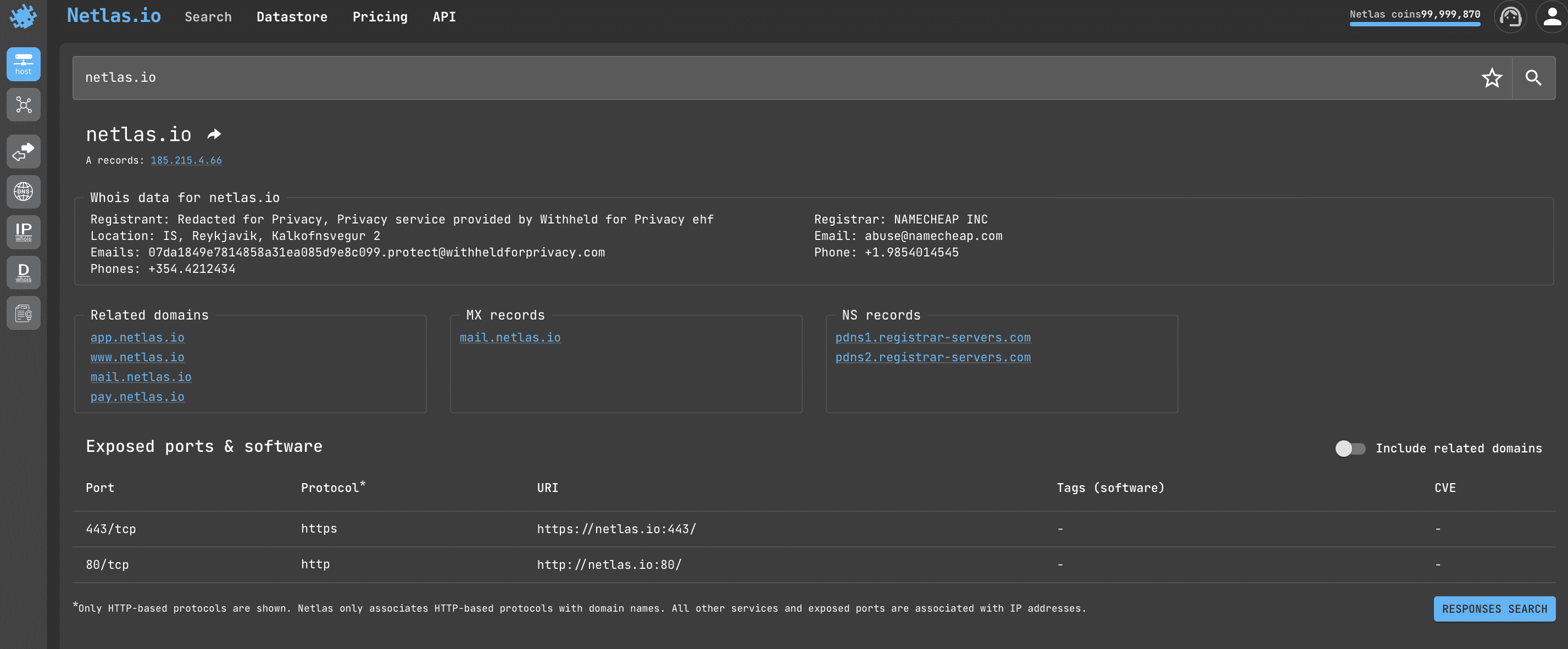
Open Netlas.io IP/Domain info and enter the domain name or IP. The following information will be displayed as a result:
- whois data (registrant, location, emails, phones)
- related domains
- MX and NS records
- exposed ports & software (sometimes additionally displays information about vulnerabilities)
Search for Non-Latin Domains

If you need to find Chinese or other internationalised domain names, then convert them to Punycode. For example:
domain:*.xn--fiqs8sYou can do this with the help of special online tools. For example - Charset.org
Looking for Websites That Contain a Certain Word in Their Title
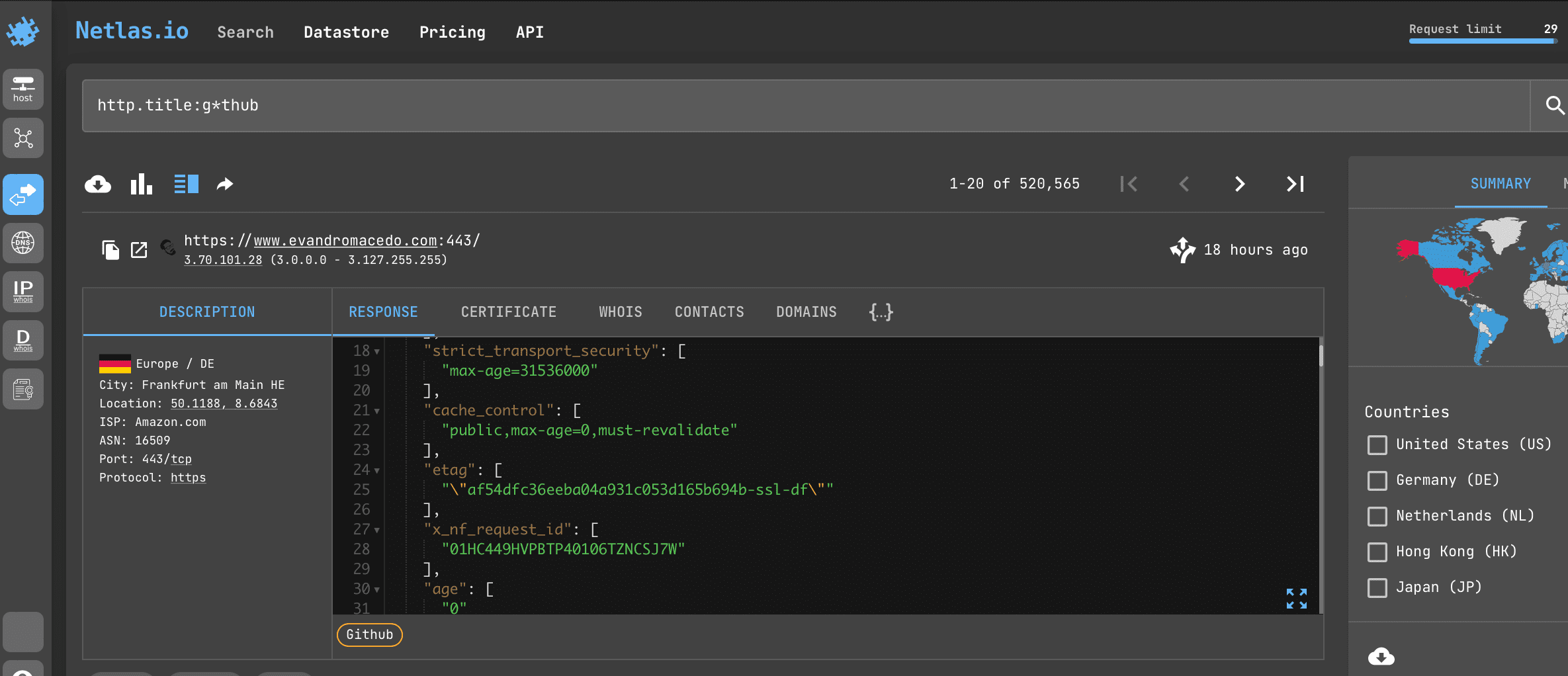
Open Netlas.io response search and enter:
http.title:g*thubThis will find all servers whose HTTP titles contain the word starts with “g” and ends to “thub”. Read more about using asterisks below.
Search Query Syntax
Now let’s learn more about how search queries work in Netlas.io.
Netlas.io based on Elasticsearch, free and open, distributed, RESTful search engine. And the search methods in Netlas.io are very similar to those of other Elasticsearch-based databases.
Filters (Fields)

Response, DNS, IP and Certificates search allow you to use filters (fields) in search queries. For example:
http.body:netlasYou can use this query to find pages which contain the word “netlas” inside their
html tag.A list of available filters for each search type is displayed on the right side of the page.
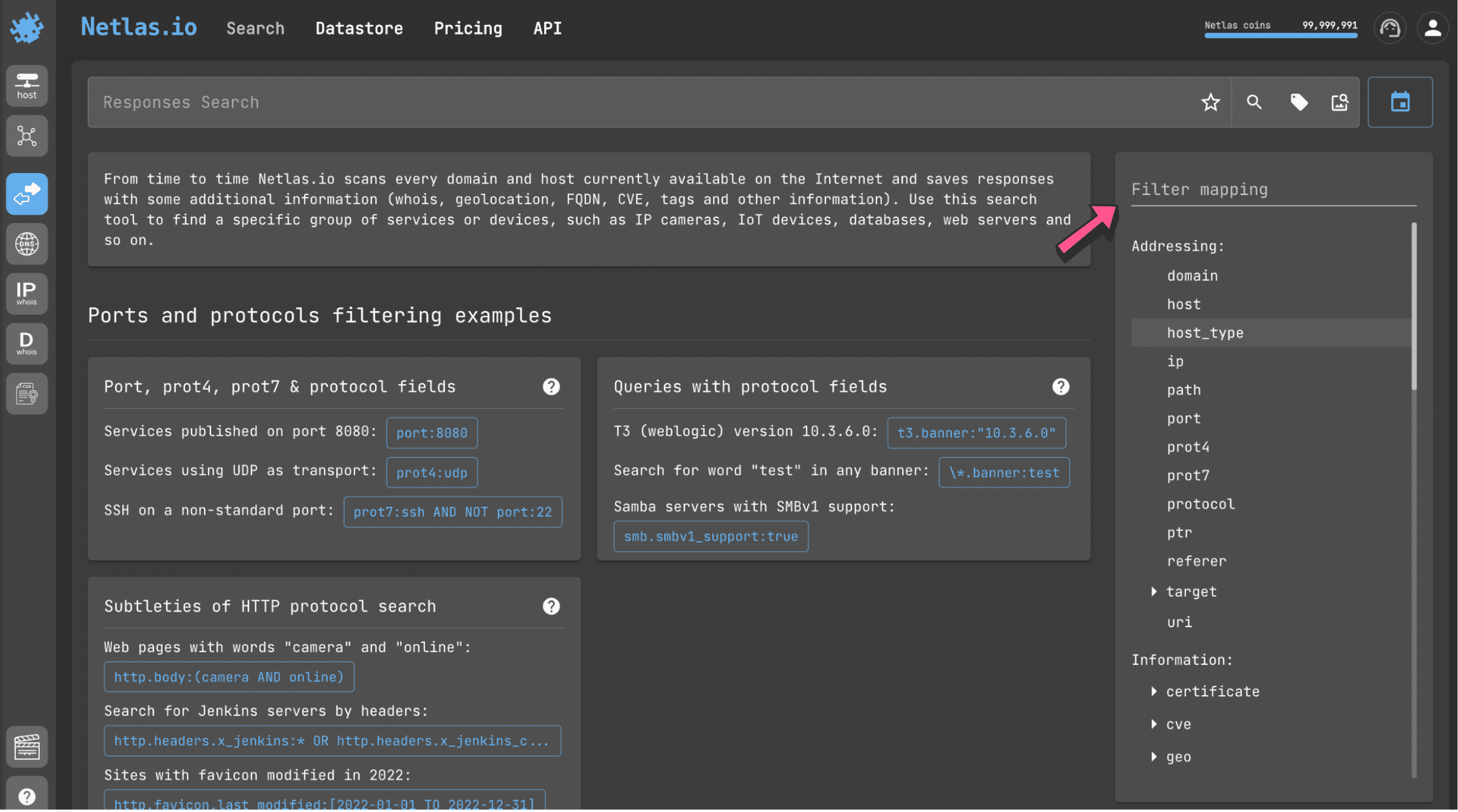
Filters allow you to search for servers based on many different parameters. For example:
domainipprotocolcertificatecvegeolocation(city,continent,country)
and many others.
Logical Operators
You can use multiple filters in a single query and combine them using logical operators AND, OR, NOT. For example:
http.title:netlas NOT port:443If you want to combine multiple conditions in your query, use parentheses:
http.title:(netlas OR shodan) NOT port:443Ranges
If you use a numeric value as the value of a field, you can designate it as a value from and to (extreme limits of the value range):
ip:[173.194.222.0 TO 173.194.222.255] Or mark only the upper or only the lower limit of the value:
host:"1.1.1.1" port:<=1000Wildcards
If you don’t know the exact description of a certain character in your query (for example, you don’t know the exact zone for a domain or the spelling of a name), you can replace it with an asterisk:
domain:google.*You can also use question mark:
domain:google.?* - many symbols, ? - one symbol.
You can also use asterisks in filters. For example:
\*.banner:databaseThis query do a search on all banner types simultaneously and replaces several filters: amqp.banner:, ftp.banner:, dns.banner:, telnet.banner:, etc.
Fuzziness
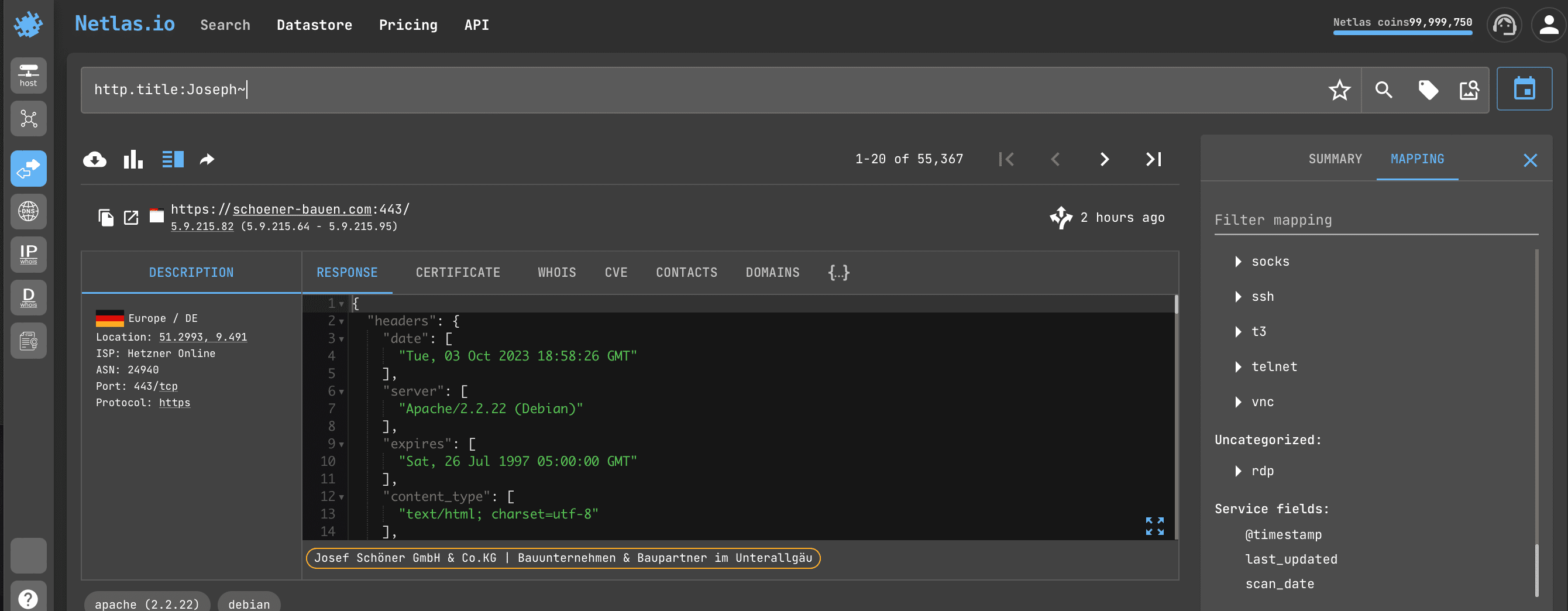
If you need to search not by exact, but by approximate value of a field (for example, pages whose titles contain all names consonant with Joseph), just add ~ to the query:
http.title:Joseph~Regular Expressions
Regular expression is a sequence of characters that allows you to search for, retrieve and replace pieces of text in a source document that match certain patterns. For example:
- Any email address:
([a-zA-Z0–9+._-]+@[a-zA-Z0–9._-]+\.[a-zA-Z0–9_-]+) - Any HTML tag:
<.*?> - Any phone number:
^[\+]?[(]?[0-9]{3}[)]?[-\s\.]?[0-9]{3}[-\s\.]?[0-9]{4,6}$ - Any Bitcoin address:
^[13][a-km-zA-HJ-NP-Z1-9]{25,34}$
For more information on using regular expressions, see the examples in the Netlas Cookbook (what you’re reading now) and the links below:
Regex Syntax Manual in Elasticsearch documentation
How regular expressions can be useful in OSINT. Theory and some practice using Google Sheets
Other Netlas.io Search Features
Download Results
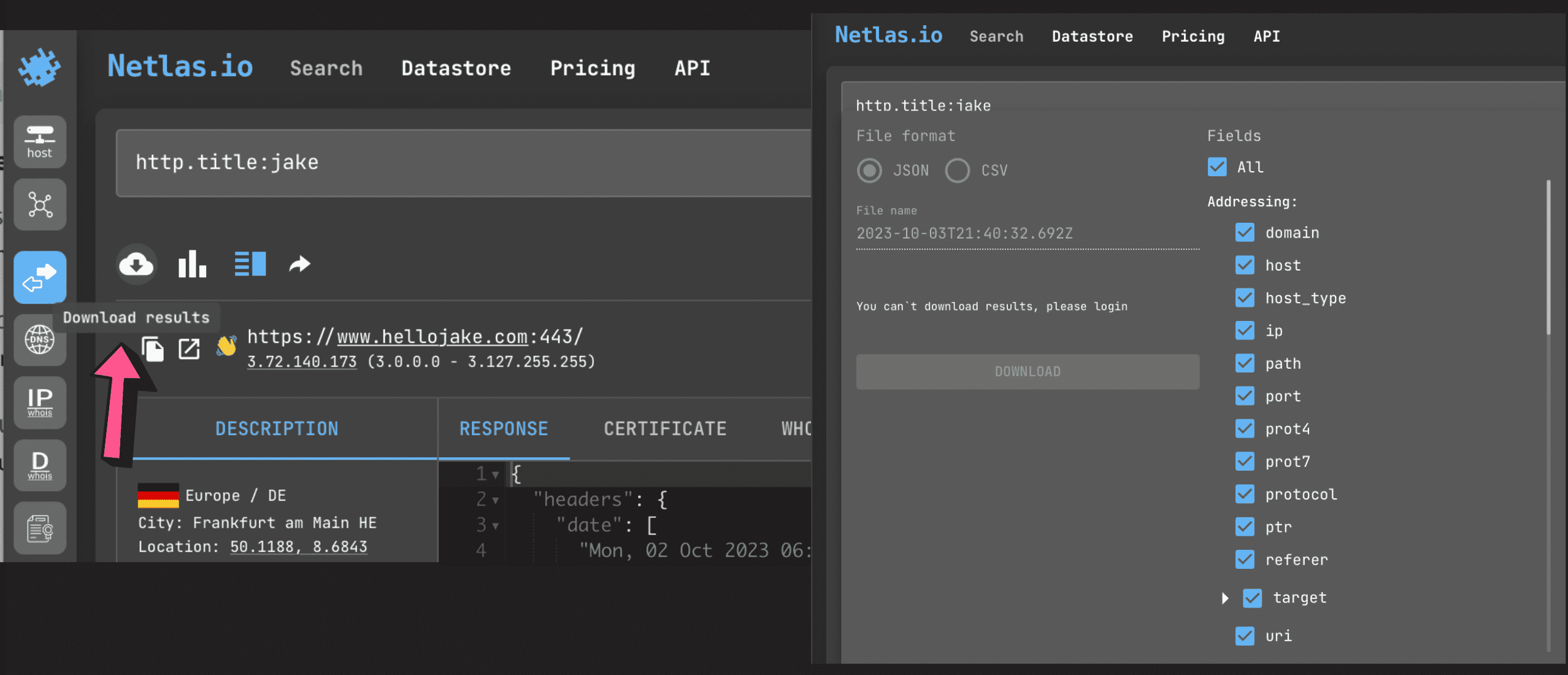
You can save your results (all or selected fields) in JSON and CSV format to view them in a format you like or automatically analyse them with different tools.
Group Results
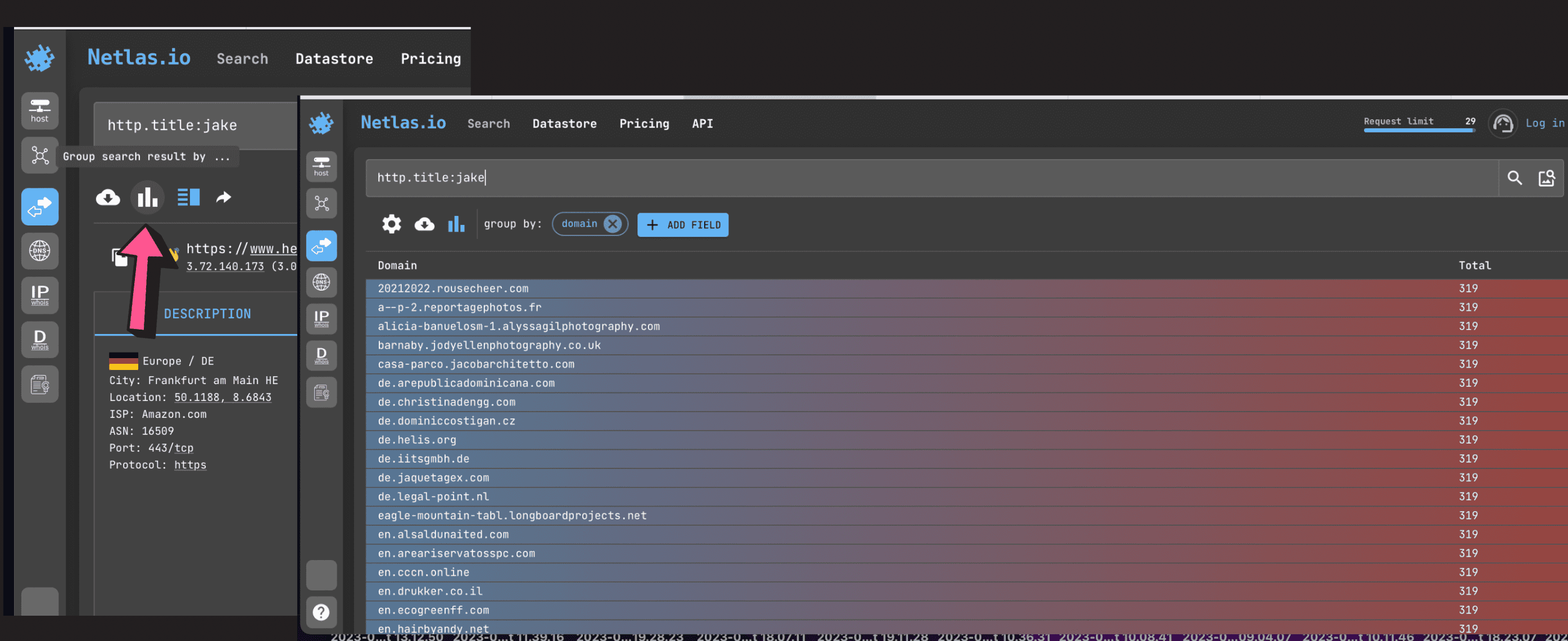
You can group results by different field values to speed up the search time. For example, by domain name or geolocation.
Share Results
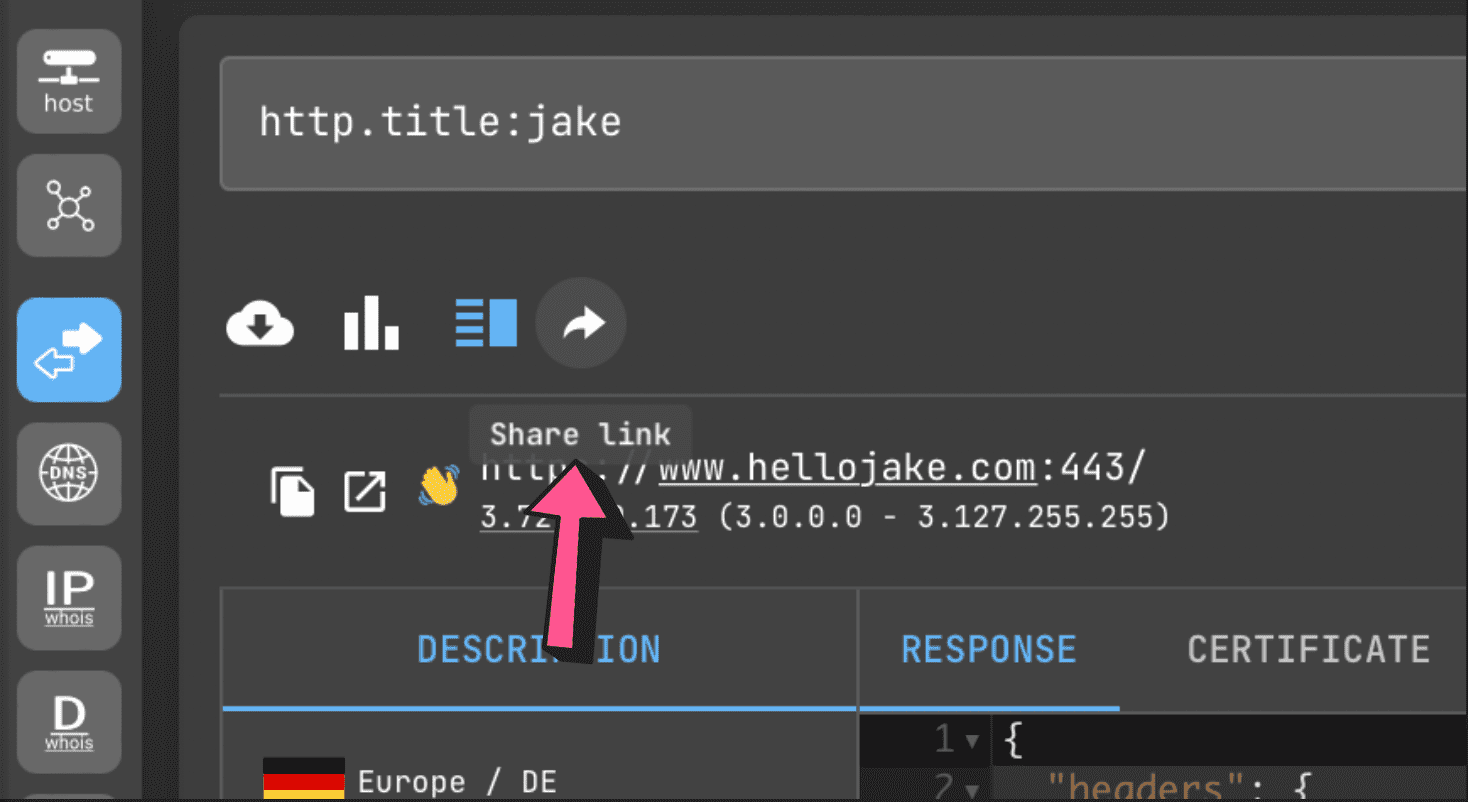
You can freely share links to search results (no registration is required to open them, unless the user has exceeded the free limit of 50 requests).
Search History
Also remember that all the quiries you have made can be viewed on your profile page (link in the top right corner).
API Requests
Netlas.io’s most important function is to help people conduct cybersecurity research faster and more efficiently. The service has an API (application programming interface) that allows you to automate the execution of various requests.
It can be implemented both in simple Python or Bash scripts of a few lines in length and in complex multifunctional applications.
You can read more about using the Netlas API in the Netlas Cookbook (what you’re reading now) or in the official documentation:
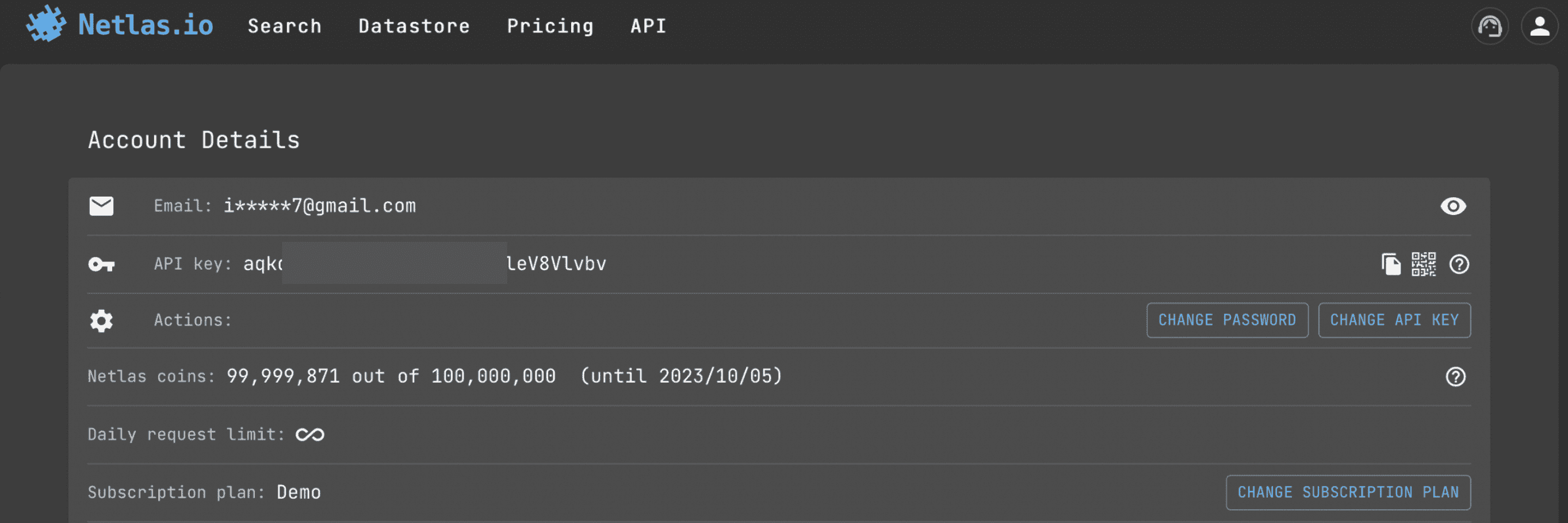
How to Find the API-key?
This is the very first place to start with the API. You don’t even have to pay for a subscription (50 requests per day are free). Just go to profile page.
Tools for Debugging API Requests
You don’t have to write scripts or create applications to start using the Netlas API. You can simply test it using your favorite API client. See instructions here.
Structure of Netlas API JSON Response
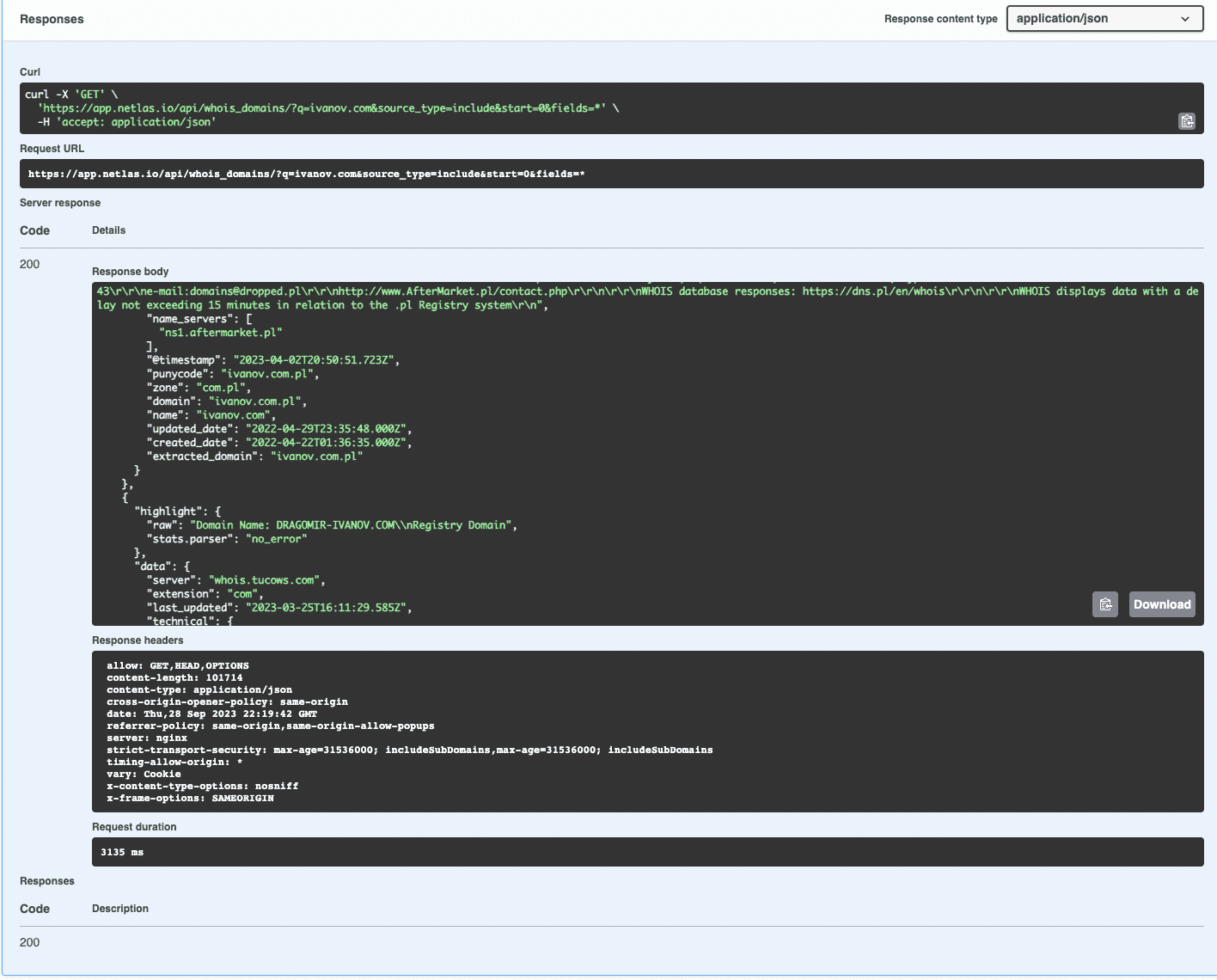
Similar to other APIs, the Netlas API response consists of headers and a response body in JSON (JavaScript Object Notation) format. JSON files contain data in key-value format and can be analysed using almost any programming language.
If you use Swagger, you can copy or download the response body and view it in any text editor or JSON analyser.
Tools for Working with Data in JSON Format
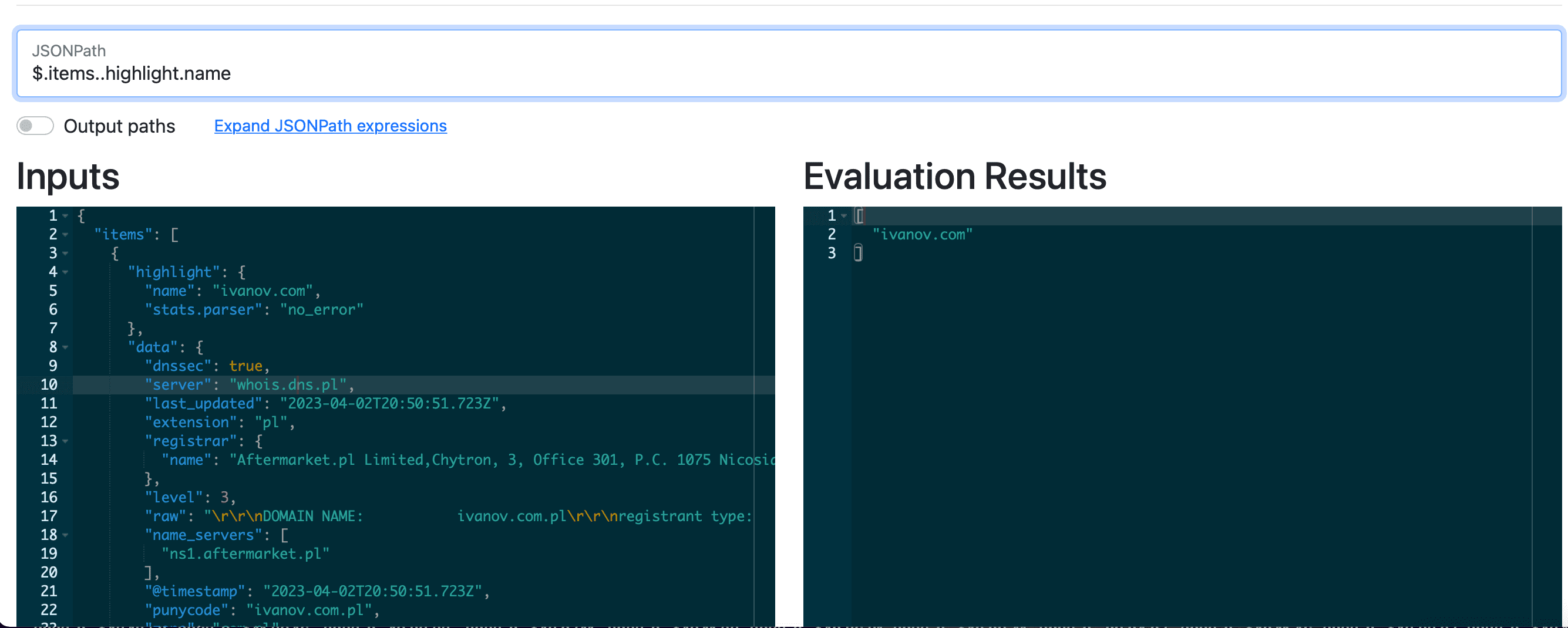
A little tip that will come in handy when writing code using the Netlas API. In order to understand the structure of a JSON file faster and find the path to get a certain value, use special tools such as:
Netlas Python Library
The easiest way to automate requests to the Netlas API is to use a specially designed Python library (package).
Netlas-Python library Github repo
Let’s see how it works with a simple example. All code samples from Netlas Cookbook are located in the scripts folder. You can clone this repository and run them on your device:
git clone https://github.com/netlas-io/netlas-cookbookIf you haven’t run a Python scripts before today and don’t know how to do it, you can start by open Netlas CookBook repository in Gitpod. Gitpod is a cloud development environment based on Ubuntu (Linux distribution). Just open this link in your browser (log in with your Github account):
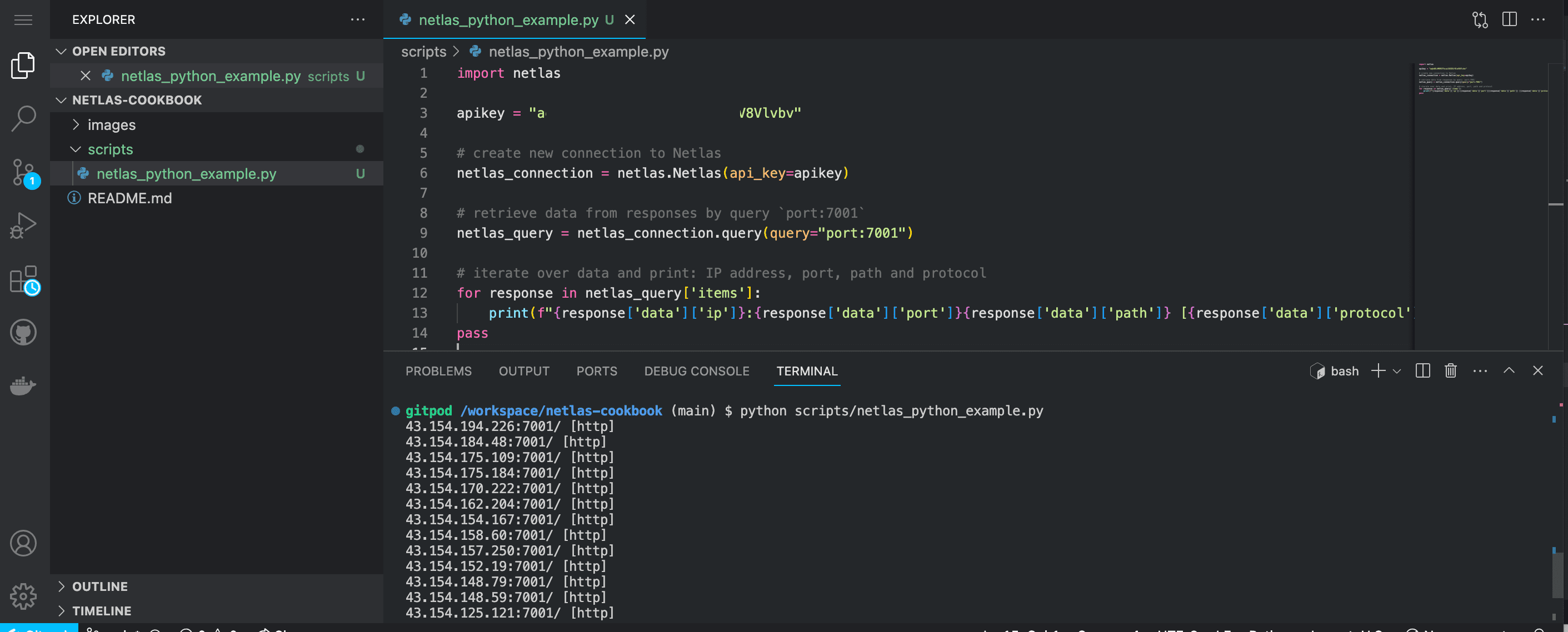
Install Netlas Python library using pip (package installer for Python). Enter in the command line:
pip install netlasCheck the installation. Enter in the command line:
netlas --helpRun netlas_python_example.py:
python3 scripts/netlas_python_example.pyAnd of course, you can just copy the code and save to files. Here is the code of the first example:
import netlas
apikey = "YOUR API KEY"
# create new connection to Netlas
netlas_connection = netlas.Netlas(api_key=apikey)
# retrieve data from responses by query `port:7001`
netlas_query = netlas_connection.query(query="port:7001")
# iterate over data and print: IP address, port, path and protocol
for response in netlas_query['items']:
print(f"{response['data']['ip']}:{response['data']['port']}{response['data']['path']} [{response['data']['protocol']}]")Examples of Response Keys for Getting Useful Data
It’s mentioned above that in order to find JSON patches of API response to get the data you need, you can use special online applications (JSON-evaluators). To make your life even better, here is a small list of examples of Python library response keys that are needed most often.
# Main domain/ip info
response['data']['uri']
response['data']['ip']
response['data']['http']['title']
response['data']['http']['meta']
response['data']['http']['body']
# Geo info
response['data']['geo']['continent']
response['data']['geo']['country']
response['data']['geo']['city']
response['data']['geo']['location']['lat']
response['data']['geo']['location']['long']
# Whois geo info
response['data']['whois']['net']['country']
response['data']['whois']['net']['address']
response['data']['whois']['net']['city']
response['data']['whois']['net']['contacts']['emails']
response['data']['whois']['net']['contacts']['phones']
# Http status and favicon ico info
response['data']['port']
response['data']['http']['status_code']
response['data']['http']['status_line']
response['data']['http']['favicon']['image']
response['data']['http']['favicon']['path']
# Basic CVE info
response['data']['cve'][0]['name']
response['data']['cve'][0]['description']
response['data']['cve'][0]['base_score']
response['data']['cve'][0]['has_exploit']
response['data']['cve'][0]['exploit_links']Netlas Python Response Datatypes
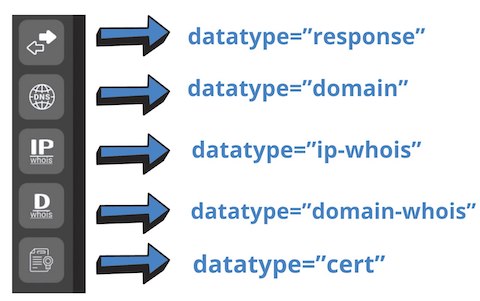
When working with the Netlas Python Library, it is very important to correctly specify the type of data you want to retrieve. By default, the response type is returned and many Netlas CookBook examples use it.
But for some tasks, like getting whoois information about a domain or searching for domains in a subnet you need to use a different data type. For example:
netlas_query = netlas_connection.query(query='a:"163.114.132.0/24"',datatype="domain")If you think some query is not returning results when it should - just try changing the value of the datatype parameter. It is very likely that this will help.
Available datatypes:
- datatype=“response” corresponds to the results that can be obtained in Netlas Responses Search.
- datatype=“domain” corresponds to the results that can be obtained in Netlas DNS search
- datatype=“domain-whois” corresponds to the results that can be obtained in Netlas Domain Whois Search.
- datatype=“ip-whois” corresponds to the results that can be obtained in Netlas IP Whois Search.
- datatype=“cert” corresponds to the results that can be obtained in Netlas Certificates Search.
Netlas CLI Tools
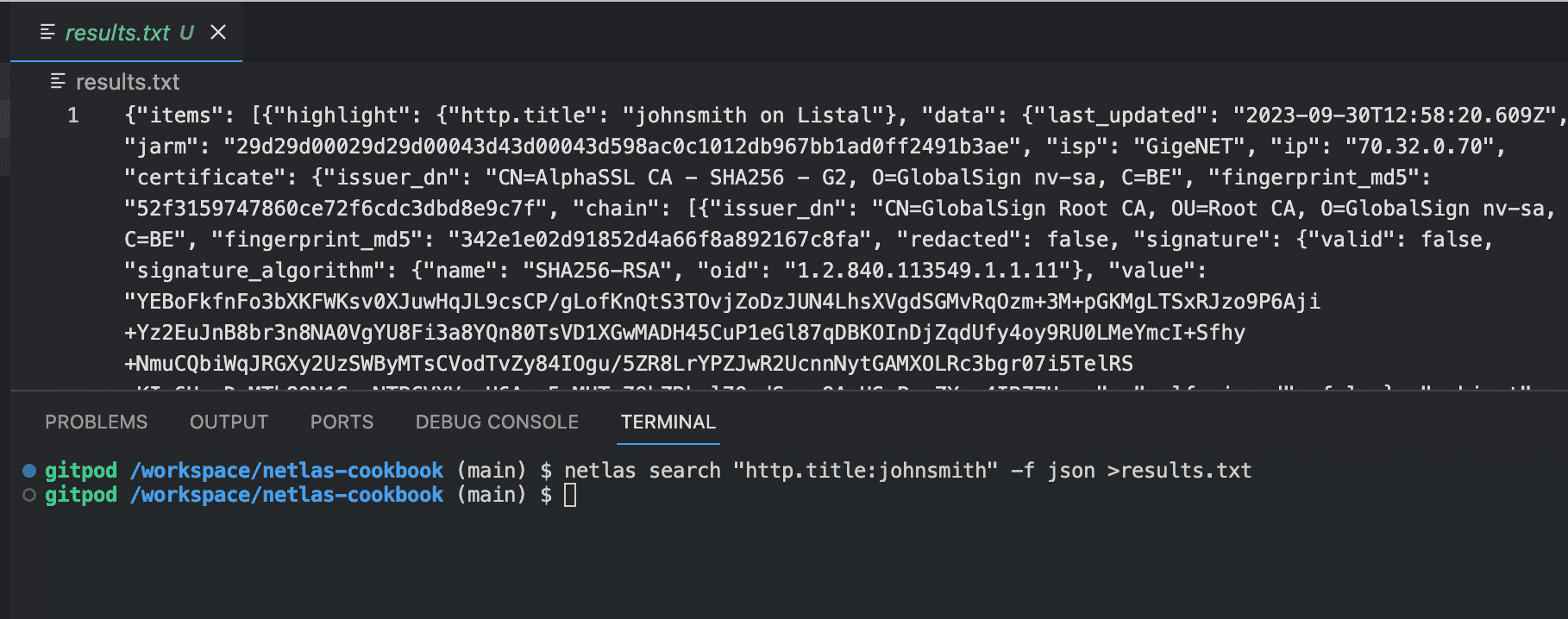
You can also use the Netlas Python Library directly from the command line. For example:
netlas search "http.title:johnsmith" -f json >results.jsonThis simple command searches for all servers that have the word johnsmith in their header, returns the results in JSON format, and stores the results in the resutls.json file.
All other features of the Netlas API can be used in the same way. You can learn more about this from the help (-h command) and examples in the Netlas Cookbook (what you are reading now).
Usage: netlas [OPTIONS] COMMAND [ARGS]...
Options:
-h, --help Show this message and exit.
Commands:
count Calculate count of query results.
download Download data.
host Host (ip or domain) information.
indices Get available data indices.
profile Get user profile data.
savekey Save API key to the local system.
search (query) Search query.
stat Get statistics for query.Before running different Netlas CLI Tools commands, save the API key in the settings:
netlas savekey YOUR_API_KEYWe also have a Github repository with a couple of examples of automating various tasks using bash script and Netlas CLI tools:
Search vs Download vs Host Methods
The Netlas API has many methods, but the most commonly used methods are search and download. They are very similar to each other, but still have some differences.
The search method loads one page of results (20 items) at a time and allows a maximum of 200 pages to be loaded (20*200=4000 items). The download method downloads all results (but requires more resources to execute).
There is also a host method that simply returns the most basic information about a particular domain or IP (datatype (like other methods) does not need to be specified):
netlas host "51.159.153.170"Additional Request Parameters
The Netlas API allows you to flexibly adjust the data returned by requests with additional parameters. For example:
- indices - id that corresponds to a specific indexing date. To find out the id for a specific date, open app.netlas.io, click on the calendar to the right of the search query entry bar, select the date you are interested in and see how the indices parameter in the URL in the browser address bar changes.
- start - result page number (default 0)
- fields - names of fields to be included in the results (all fields by default). It will be useful for speeding up and optimizing code with a large number of requests.
Make Requests with Python (without Netlas Python Library)
You may find it easier in some cases not to use the Netlas Python Library, but to use the standard Python request package, which is familiar to many developers:
Enter in the command line:
python scripts/python_example.pySource code of python_example.py:
import requests
response = requests.get("https://app.netlas.io/api/domains/?q=ivanov.com&source_type=include&start=0&fields=*",{'X-API-Key': 'YOUR API KEY'})
print(response.json())But Netlas Python Library is still preferable as it is designed to deal with different problems with query processing (errors, long waits, etc.).
Examples for Other Programming Languages
While we recommend using our Python Library to automate Netlas search, it’s worth noting that the Netlas API can be built into most applications with a wide variety of technology stacks. The main thing is that it should be able to make REST requests and parse JSON data.
Here are some examples in different popular programming languages.
NodeJS
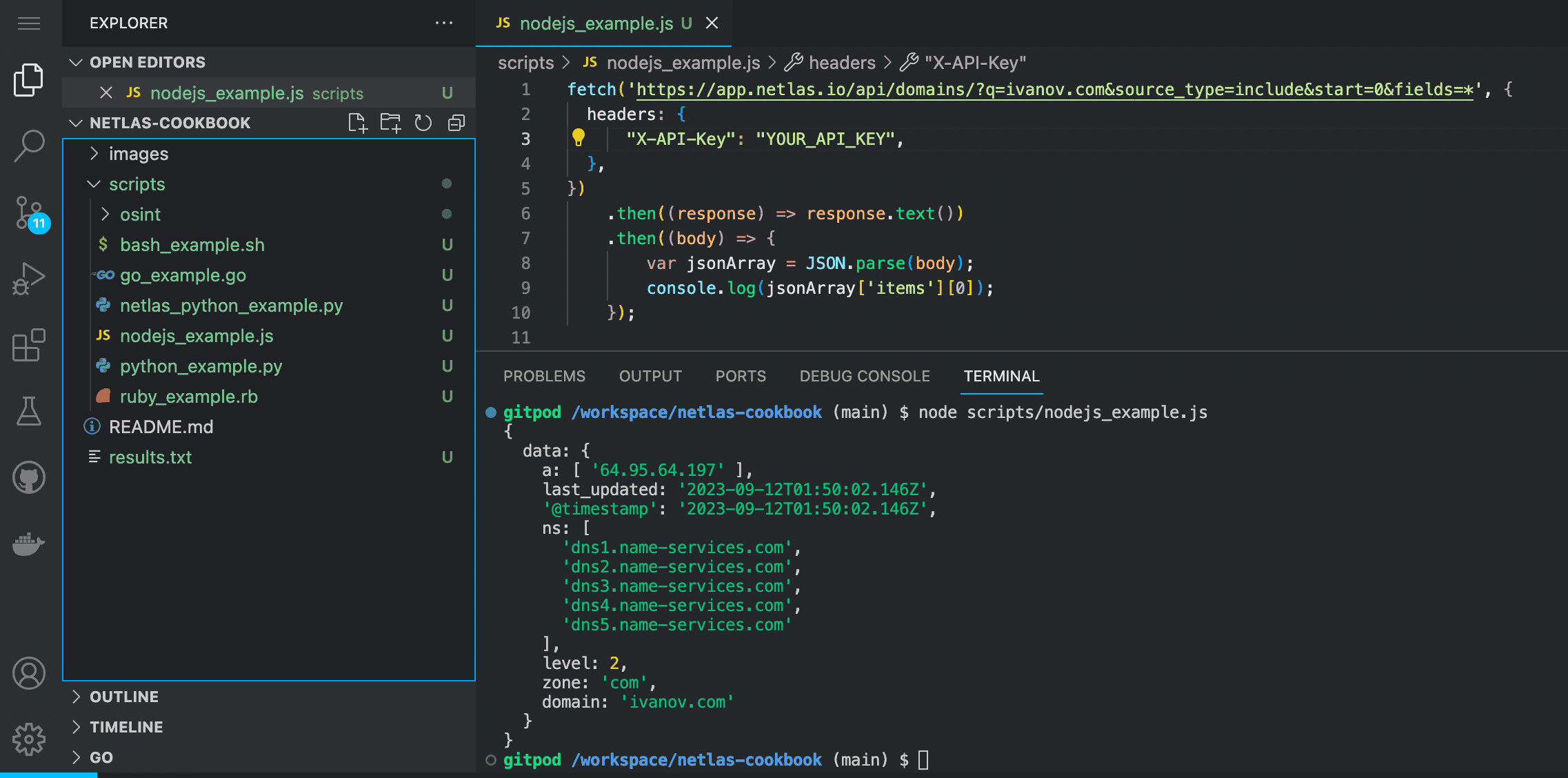
Enter in the command line:
node scripts/node_example.jsIf you are not using Gitpod, you should have NodeJS installed on your device.
Source code of nodejs_example.js:
fetch('https://app.netlas.io/api/domains/?q=ivanov.com&source_type=include&start=0&fields=*', {
headers: {
"X-API-Key": "YOUR_API_KEY",
},
})
.then((response) => response.text())
.then((body) => {
var jsonArray = JSON.parse(body);
console.log(jsonArray['items'][0]);
});Ruby
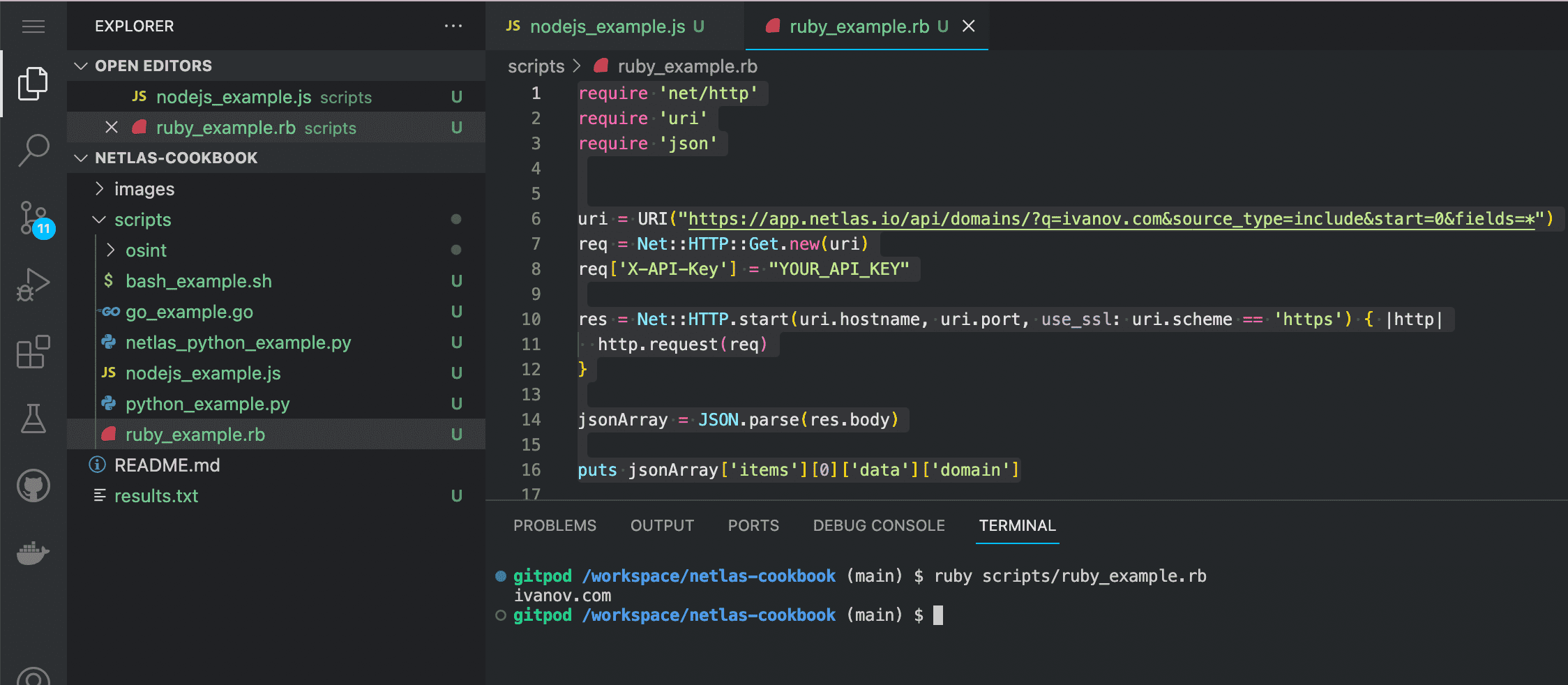
Enter in the command line:
ruby scripts/ruby_example.rbIf you are not using Gitpod, you should have Ruby installed on your device.
Source code of ruby_example.rb:
require 'net/http'
require 'uri'
require 'json'
uri = URI("https://app.netlas.io/api/domains/?q=ivanov.com&source_type=include&start=0&fields=*")
req = Net::HTTP::Get.new(uri)
req['X-API-Key'] = "YOUR_API_KEY"
res = Net::HTTP.start(uri.hostname, uri.port, use_ssl: uri.scheme == 'https') { |http|
http.request(req)
}
jsonArray = JSON.parse(res.body)
puts jsonArray['items'][0]['data']['domain']Bash
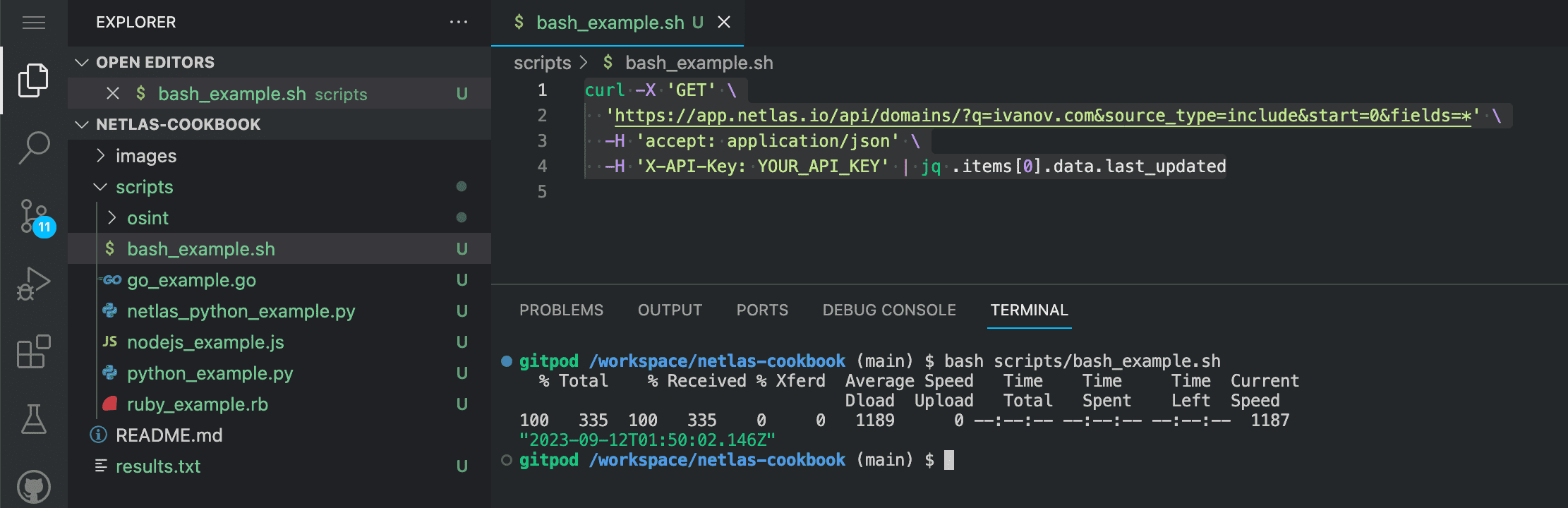
Enter in the command line:
bash scripts/bash_example.shSource code of bash_example.sh:
curl -X 'GET' \
'https://app.netlas.io/api/domains/?q=ivanov.com&source_type=include&start=0&fields=*' \
-H 'accept: application/json' \
-H 'X-API-Key: YOUR_API_KEY' | jq .items[0].data.last_updatedJQ Utility
Note that in the example above, the JQ utility was used to extract fields from JSON data.
It is sometimes referred to as “like sed for JSON data”. It is a surprisingly handy tool for working with any JSON data. Here are some syntax examples.
Print firt item of JSON-array:
.items[0] Print all items of JSON-array:
.items[]Print all ‘data’ subitems of first item of JSON-array:
.['items'][0]['data'][]Print all sub-subitems for each item of JSON-array:
.items[].data.technical[]You can read more about JQ here (I recommend paying special attention to data filtering): JQ utility documentation
AI Tools for Writing Code
If you encounter any problems when customising the Netlas Cookbook examples, we recommend that you seek help from AI tools for improving and writing code. For example:
When working with such services, you just need to describe in words the task you want to solve with the help of code.
Code Checkers
When you rework the Netlas Cookbook examples to suit your purposes, you may find that the code will not execute from some errors. Special online tools can help you find and fix them:
ExtendsClass Python Tester Snyk
If you don’t want to copy your code to third-party services, you can check it for errors on your device using the Pylint (static code analyser):
Using Netlas.io for OSINT (Open Source Intelligence)
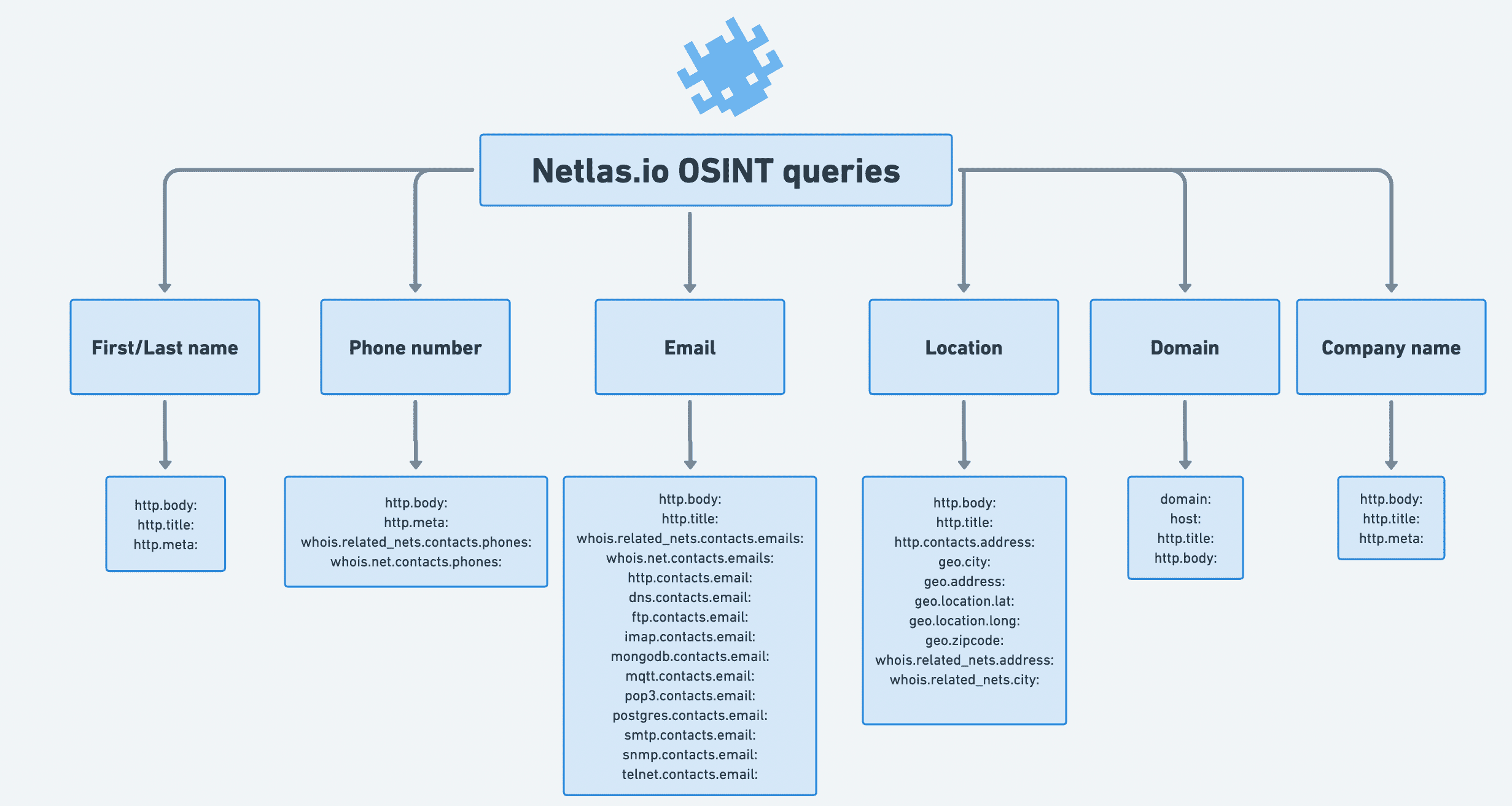
Netlas.io can help you gather data about a domain or company, as well as find mentions of a person (or anyone) in internet.
It can also be used to find old versions of web pages (as an analogue of the Wayback Machine).
Search Person’s Nickname or Email in WHOIS Contacts
Most often WHOIS data contains only the contact information of the company registering the domains. But sometimes there may be personal contacts of persons of interest. This query will help you find them.
This method may require a paid subscription. See the pricing
Search query example
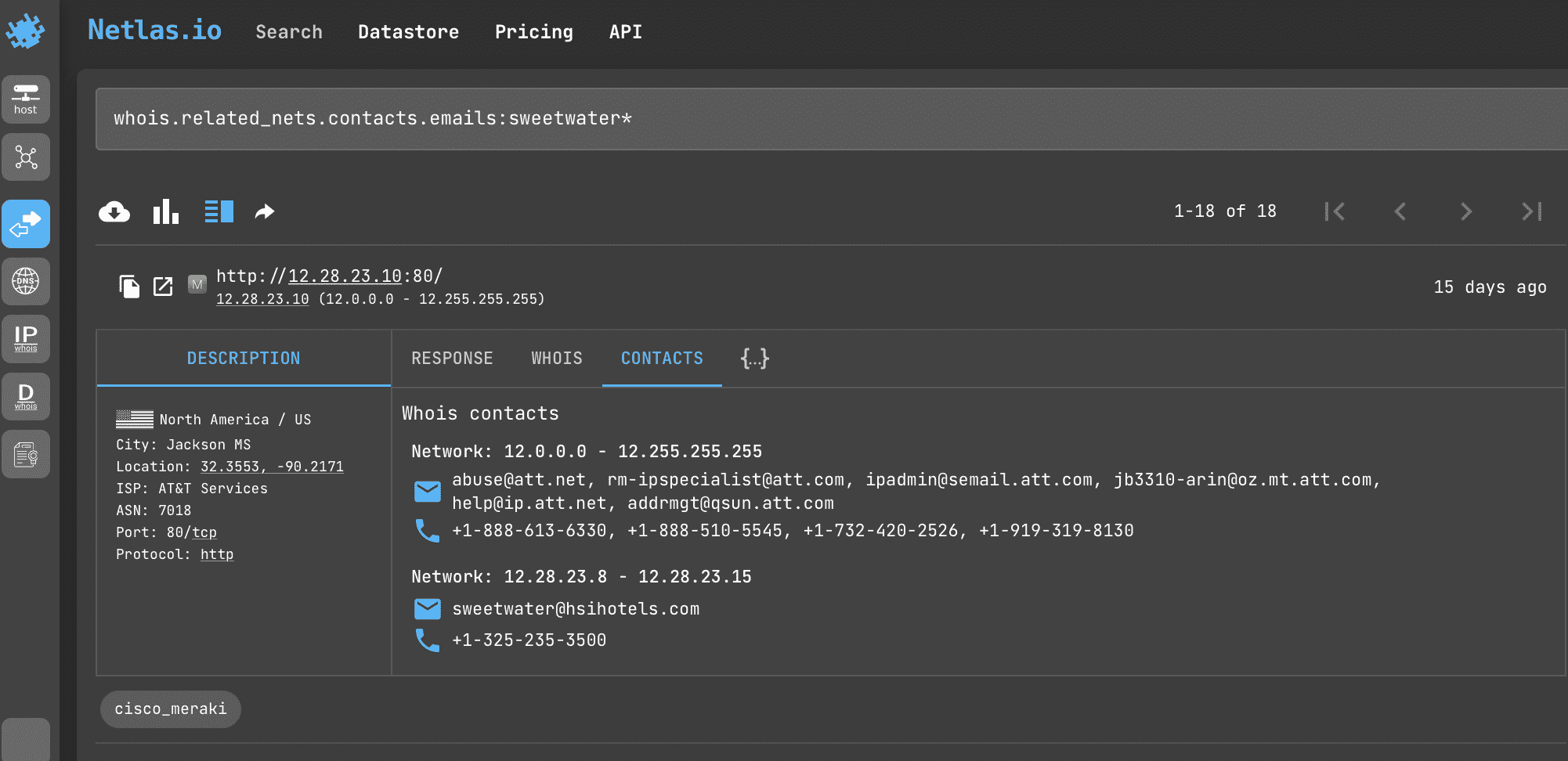
whois.related_nets.contacts.emails:sweetwaterAPI request example
Netlas CLI Tools:
netlas search "whois.related_nets.contacts.emails:sweetwater*" -f jsonCurl:
curl -X 'GET' \
'https://app.netlas.io/api/responses/?q=whois.related_nets.contacts.emails%3Asweetwater*&fields=' \
-H 'accept: application/json' \
-H 'X-API-Key: aqkd8L4MR93Tkcaz2UXDXrRleV8Vlvbv' | jq .items[].data.uriCode example (Netlas Python Library)
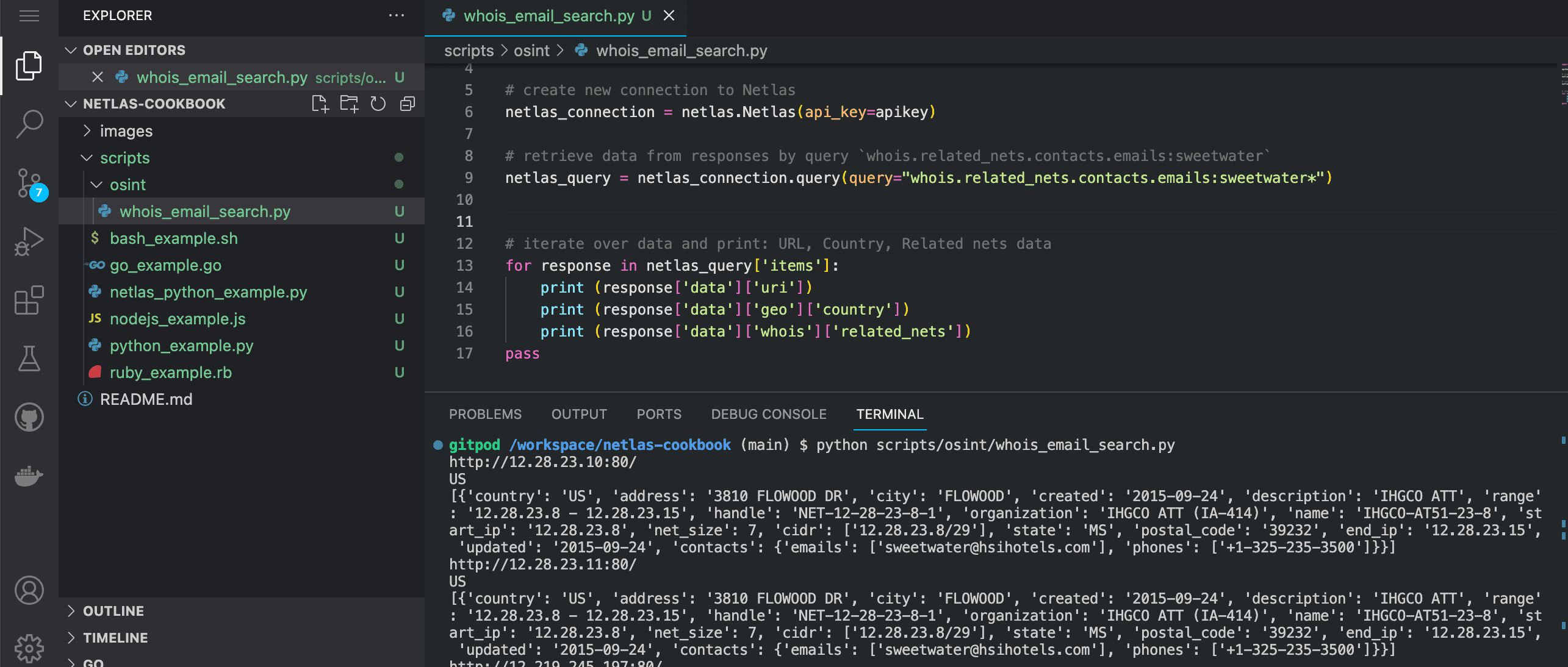
Run in command line:
python scripts/osint/whois_email_search.pySource code of scripts/osint/whois_email_search.py:
import netlas
apikey = "YOUR_API_KEY"
# create new connection to Netlas
netlas_connection = netlas.Netlas(api_key=apikey)
# retrieve data from responses by query `whois.related_nets.contacts.emails:sweetwater`
netlas_query = netlas_connection.query(query="whois.related_nets.contacts.emails:sweetwater*")
# iterate over data and print: URL, Country, Related nets data
for response in netlas_query['items']:
print (response['data']['uri'])
print (response['data']['geo']['country'])
print (response['data']['whois']['related_nets'])Search for Person’s Nickname or Email in Title and Body of Web Page
Netlas allows you to search for mentions of certain words in headings and in the html code of web pages. You can search for words by exact match, by approximate match (see the fuzzy queries section) and replace characters you are not sure of with asterisks.
Search query example
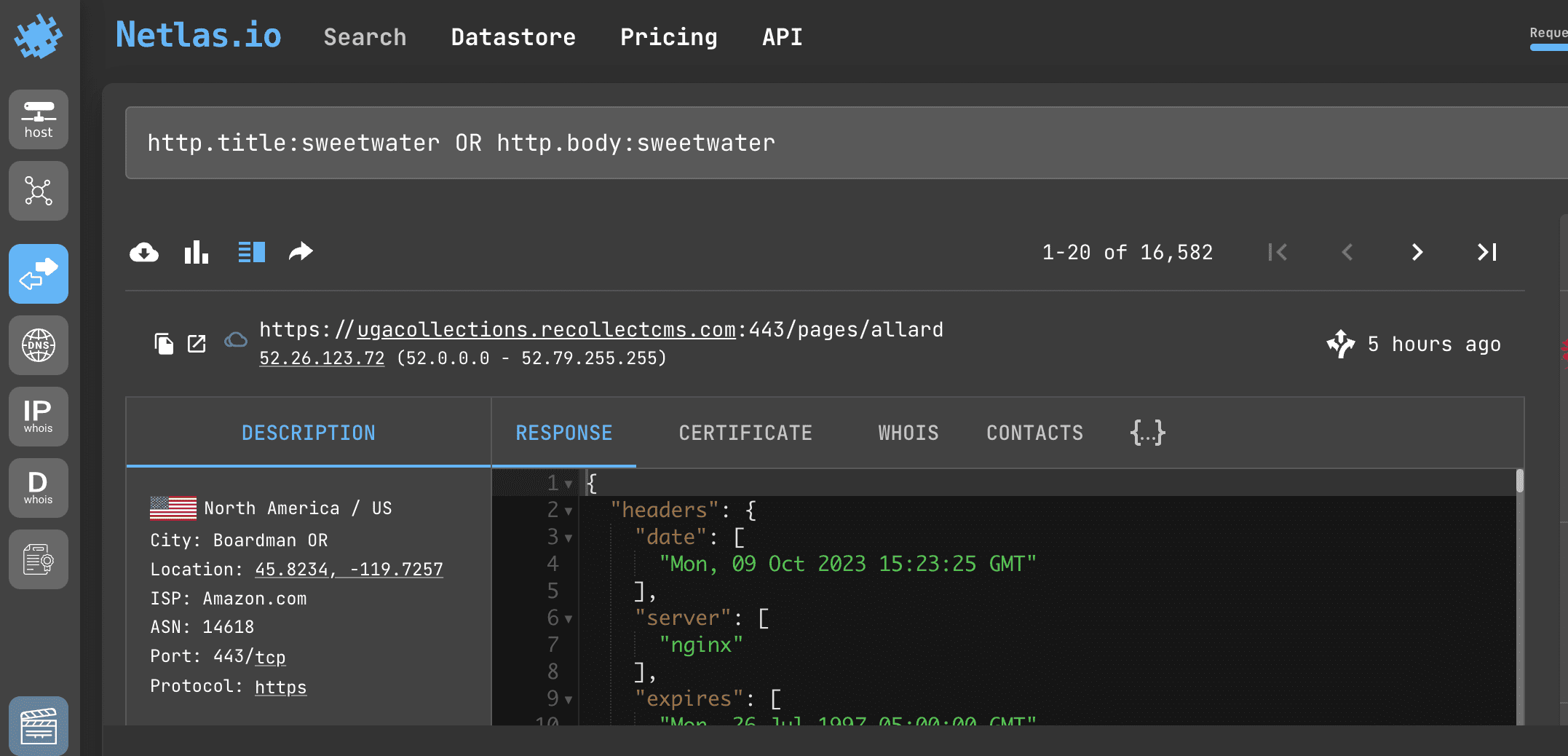
http.title:sweetwater OR http.body:sweetwaterAPI request example
Netlas CLI Tools:
netlas search "http.title:sweetwater OR http.body:sweetwater" -f jsonCurl:
curl -X 'GET' \
'https://app.netlas.io/api/responses/?q=whois.related_nets.contacts.emails%3Asweetwater*&fields=' \
-H 'accept: application/json' \
-H 'X-API-Key: YOUR_API_KEY' | jq .items[].data.uriCode example (Netlas Python Library)
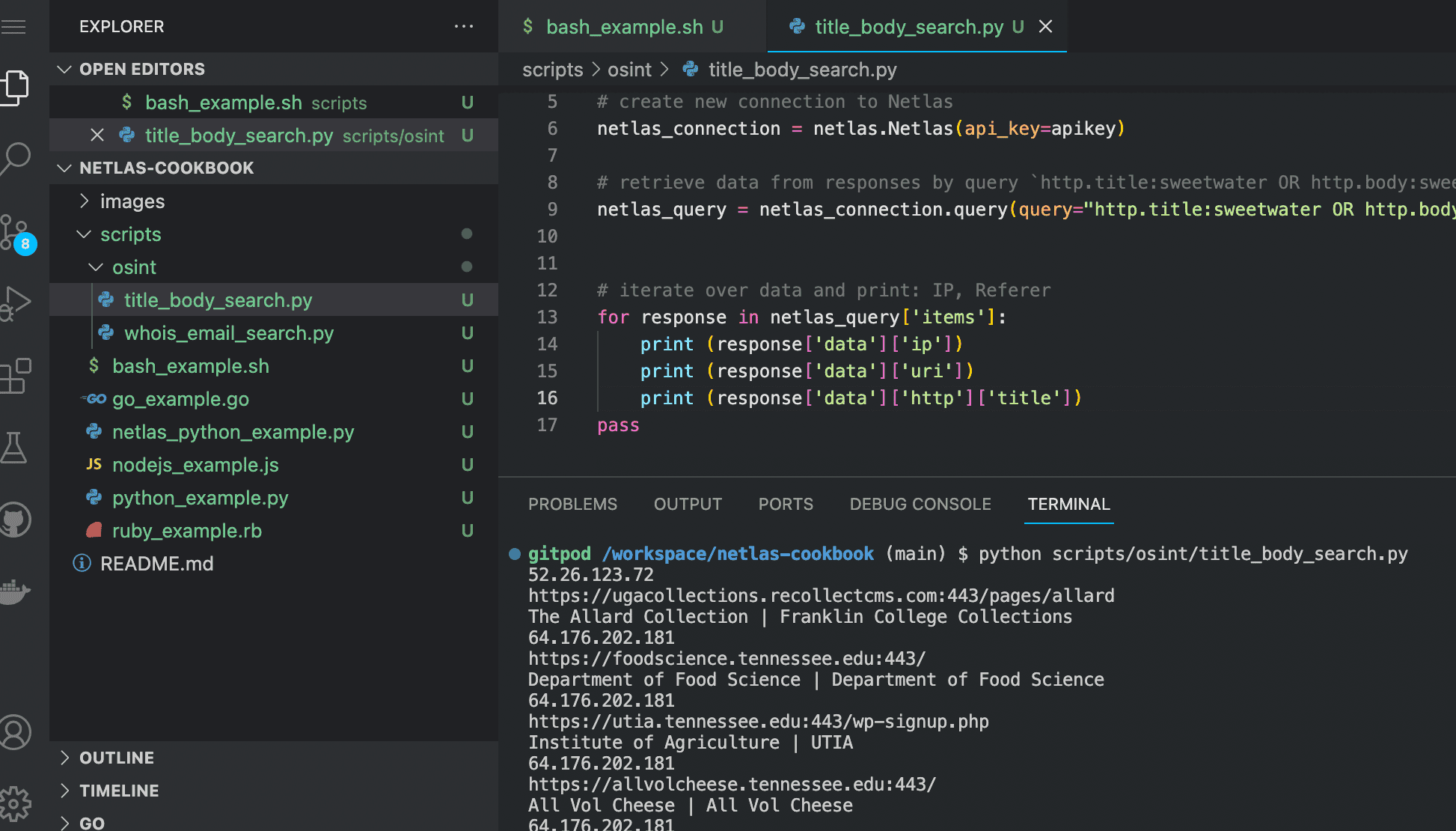
Run in command line:
python scripts/osint/title_body_search.pySource code of scripts/osint/title_body_search.py:
import netlas
apikey = "YOUR_API_KEY"
# create new connection to Netlas
netlas_connection = netlas.Netlas(api_key=apikey)
# retrieve data from responses by query `http.title:sweetwater OR http.body:sweetwater`
netlas_query = netlas_connection.query(query="http.title:sweetwater OR http.body:sweetwater*")
# iterate over data and print: IP,URL,web page title
for response in netlas_query['items']:
print (response['data']['ip'])
print (response['data']['uri'])
print (response['data']['http']['title'])Search for “Juicy Info Files” on Subdomains of the Company’s Website
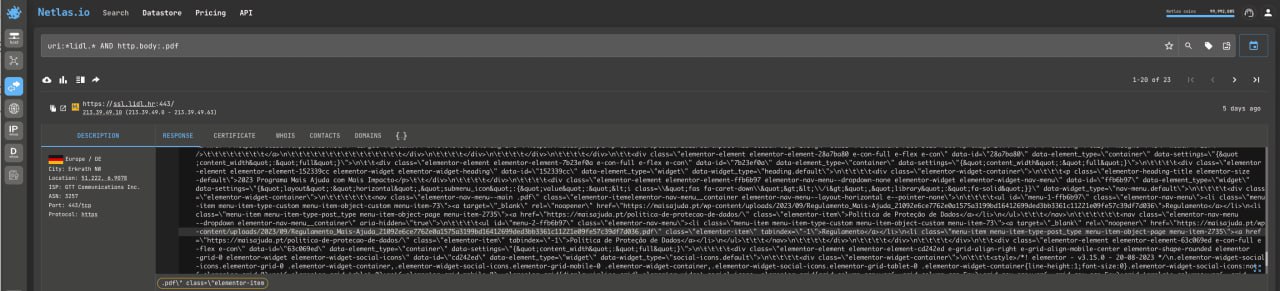
Metagoofil has been a popular tool among OSINT practitioners for many years. It searches Google for document files on a company’s website (pdf, xlsx, docx etc) and analyses their metadata.
And what is not indexed by Google can be found with Netlas and then downloaded to your computer and analysed with the MetaDetective tool.
uri:*lidl.* AND http.body:pdfYou can replace the uri: filter with domain: and host: (I recommend always comparing the results when using these three filters).
You can also search for a wide variety of file extensions, depending on what you want to find. For example:
http.body:xls
http.body:xlsx
http.body:doc
http.body:docx
http.body:ppt
http.body:pptx
http.body:mdb
http.body:csv
http.body:sql
http.body:sqliteAPI request example
Netlas CLI Tools:
netlas search "uri:*lidl.* AND http.body:pdf"Curl:
curl -X 'GET' \
'https://app.netlas.io/api/responses/?q=uri%3A*lidl.*%20AND%20http.body%3Apdf&source_type=include&start=0&fields=*' \
-H 'accept: application/json' \
-H 'X-API-Key: 'YOUR_API_KEY' | jq .items[].data.domainCode example (Netlas Python Library)
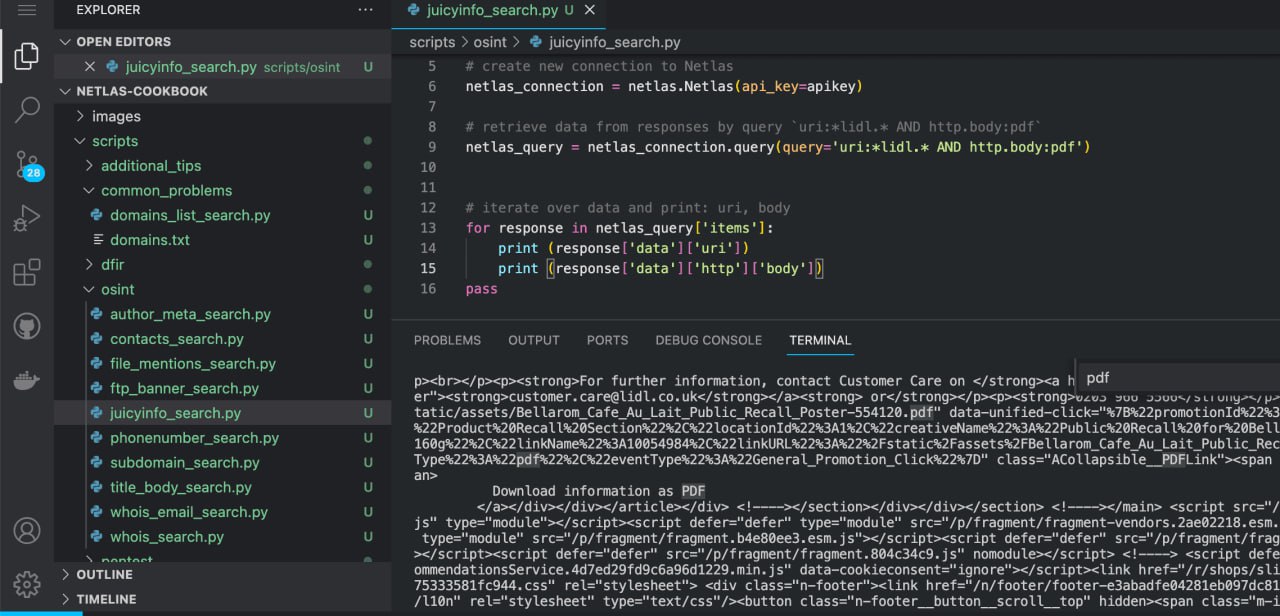
Run in command line:
python scripts/osint/juicyinfo_search.pySource code of scripts/osint/juicyinfo_search.py:
import netlas
apikey = "YOUR_API_KEY"
# create new connection to Netlas
netlas_connection = netlas.Netlas(api_key=apikey)
# retrieve data from responses by query `uri:*lidl.* AND http.body:pdf`
netlas_query = netlas_connection.query(query='uri:*lidl.* AND http.body:pdf')
# iterate over data and print: uri, body
for response in netlas_query['items']:
print (response['data']['uri'])
print (response['data']['http']['body'])In order to automate links to PDF documents from the web page body you can use the Python Re package.
Phone Number Mentions Search
As with nicknames and emails, you can also look for mentions of a phone number in the code of web pages or WHOIS contact information.
We single out this task as a separate example, because searching for a phone number is complicated by the fact that it can be written in different formats.
Search query example
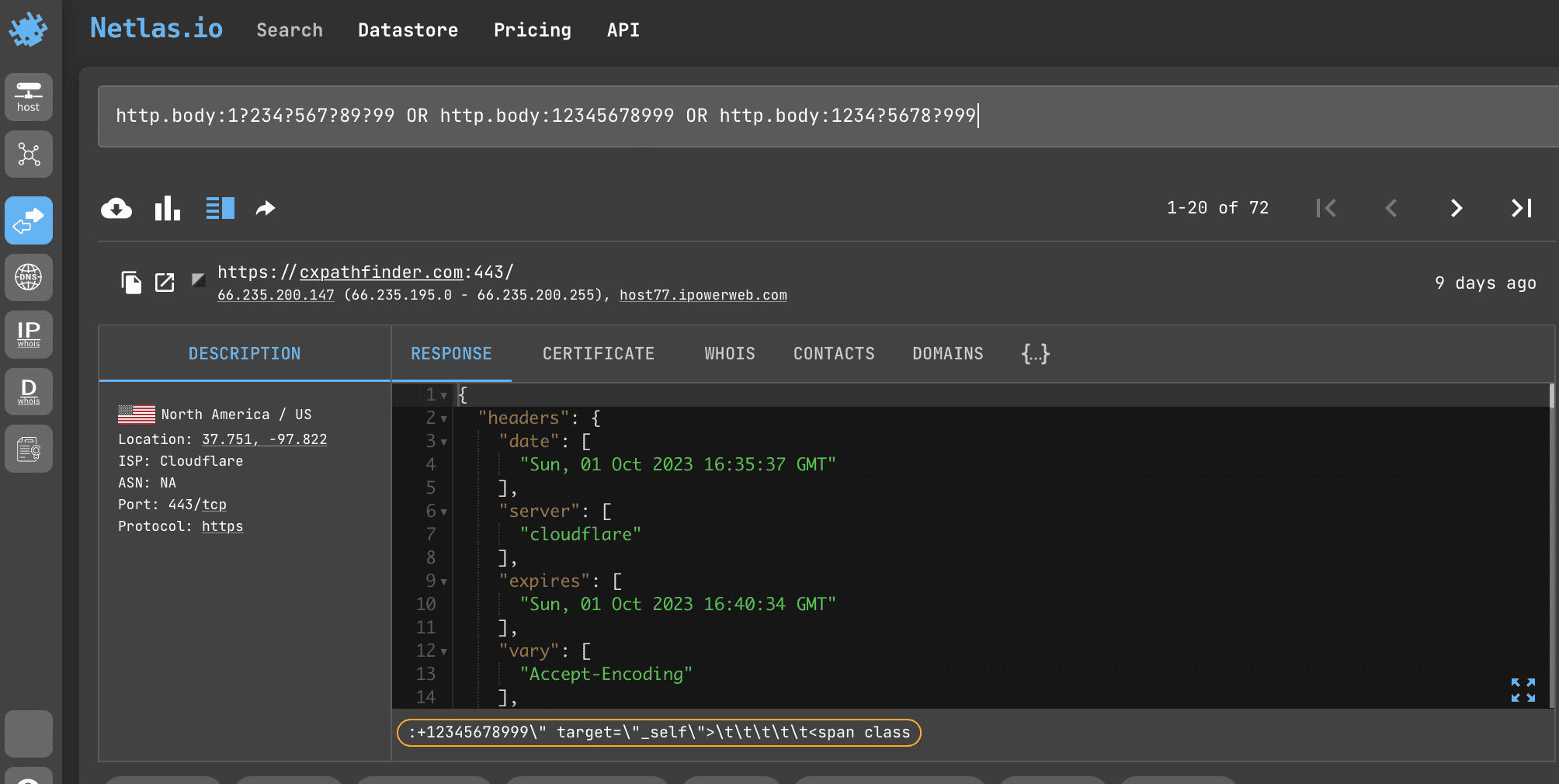
http.body:1?234?567?89?99 OR http.body:12345678999 OR http.body:1234?5678?999When making a request, you should take into account the format of telephone number recording, which is accepted in the country, which owns the phone number you are interested in.
API request example
Netlas CLI Tools:
netlas search "http.body:1?234?567?89?99 OR http.body:12345678999 OR http.body:1234?5678?999" -f jsonDon’t forget that you can search for phone numbers not only in the body of the page, but also in the WHOIS contact information. This can be done using the filter whois.related_nets.contacts.phones:
Curl:
curl -X 'GET' \
'https://app.netlas.io/api/responses/?q=http.body%3A1%3F234%3F567%3F89%3F99%20OR%20http.body%3A12345678999%20OR%20http.body%3A1234%3F5678%3F999&source_type=include&start=0&fields=*' \
-H 'accept: application/json' \
-H 'X-API-Key: YOUR_API_KEY' jq .items[].data.uriCode example (Netlas Python Library)
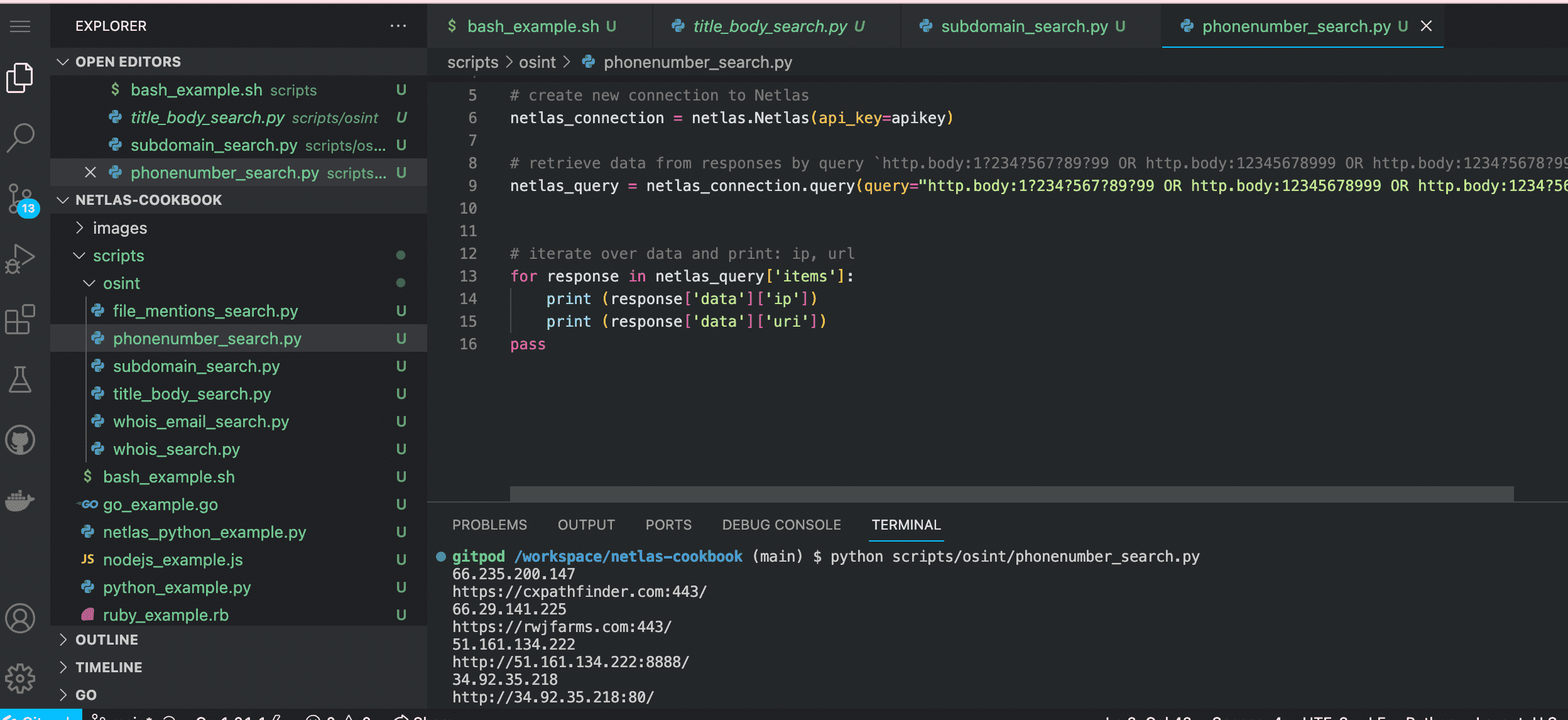
Run in command line:
python scripts/osint/phonenumber_search.pySource code of scripts/osint/phonenumber_search.py:
import netlas
apikey = "YOUR_API_KEY"
# create new connection to Netlas
netlas_connection = netlas.Netlas(api_key=apikey)
# retrieve data from responses by query `http.body:1?234?567?89?99 OR http.body:12345678999 OR http.body:1234?5678?999`
netlas_query = netlas_connection.query(query="http.body:1?234?567?89?99 OR http.body:12345678999 OR http.body:1234?5678?999")
# iterate over data and print: ip, url
for response in netlas_query['items']:
print (response['data']['ip'])
print (response['data']['uri'])Search File Mentions (Looking for Content That May be Infringing on Copyrights)
Let’s imagine that you are a musician and you want to find all the sites where your tracks are posted. You can do this by searching for pages that mention your name and have links to files with the .mp3 extension.
Search query example
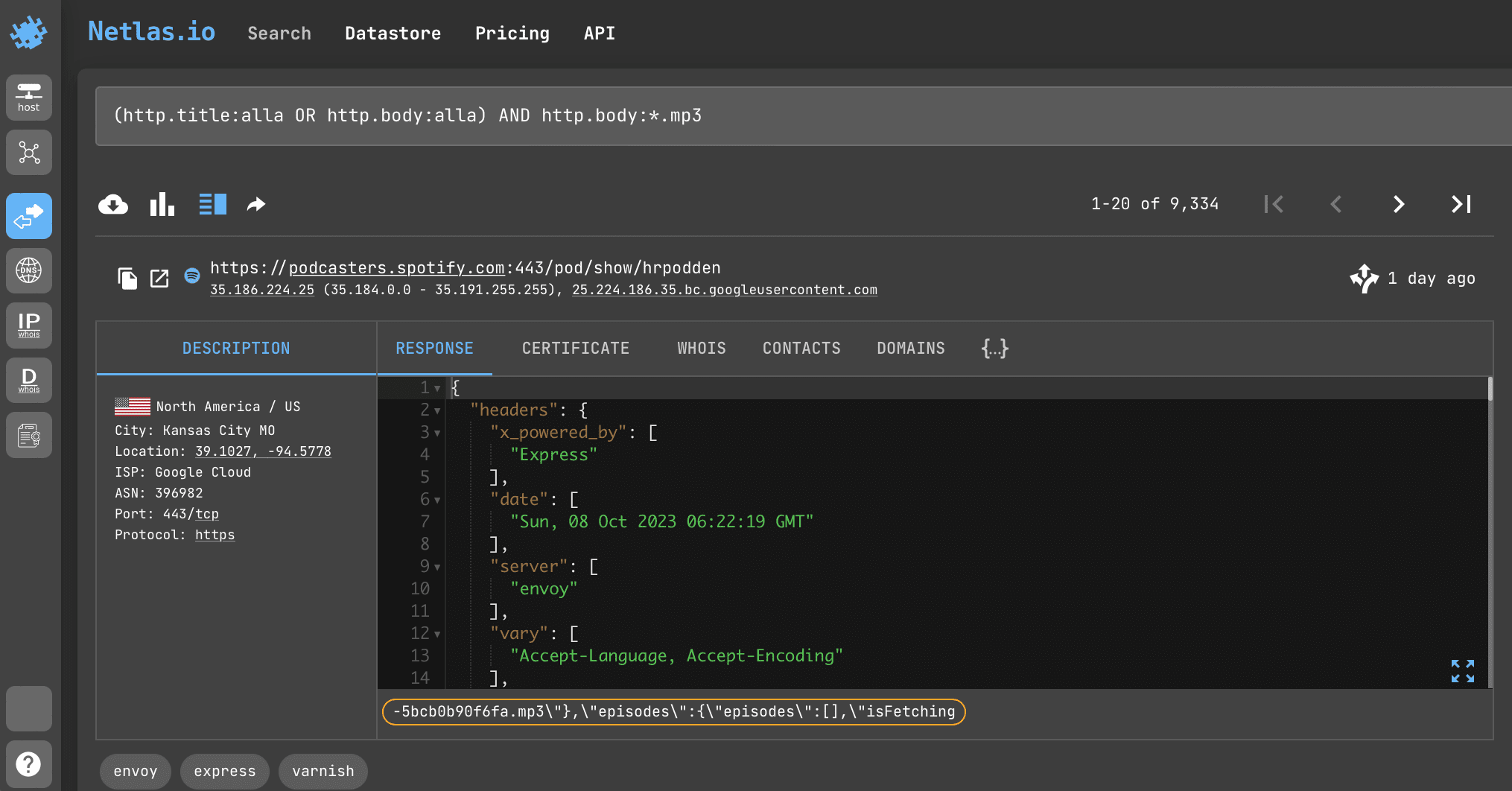
(http.title:alla OR http.body:alla) AND http.body:*.mp3API request example
Netlas CLI Tools:
netlas search "(http.title:alla OR http.body:alla) AND http.body:*.mp3" -f jsonCurl:
curl -X 'GET' \
'https://app.netlas.io/api/responses/?q=(http.title%3Aalla%20OR%20http.body%3Aalla)%20AND%20http.body%3A*.mp3&source_type=include&start=0&fields=*' \
-H 'accept: application/json' \
-H 'X-API-Key: YOUR_API_KEY' | jq .items[].data.http.titleCode example (Netlas Python Library)
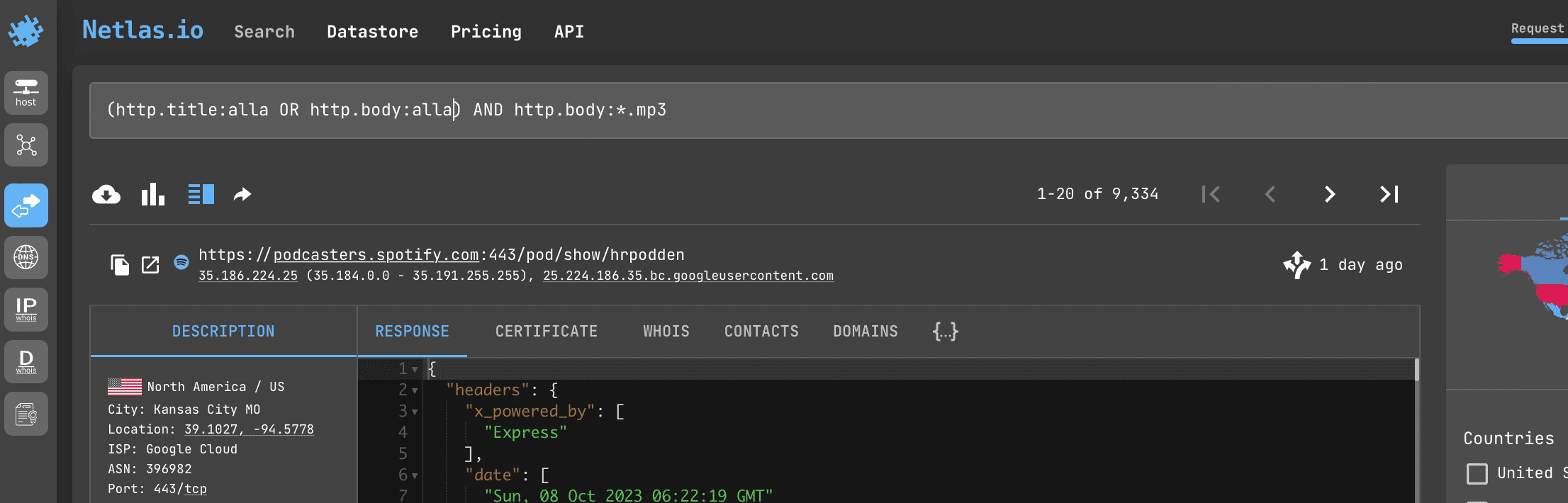
Run in command line:
python scripts/osint/file_mentions_search.pySource code of scripts/osint/file_mentions_search.py:
import netlas
apikey = "YOUR_API_KEY"
# create new connection to Netlas
netlas_connection = netlas.Netlas(api_key=apikey)
# retrieve data from responses by query `(http.title:alla OR http.body:alla) AND http.body:*.mp3`
netlas_query = netlas_connection.query(query="(http.title:alla OR http.body:alla) AND http.body:*.mp3")
# iterate over data and print: IP, URL,web page title
for response in netlas_query['items']:
print (response['data']['ip'])
print (response['data']['uri'])
print (response['data']['http']['title'])Domain WHOIS Information Gathering
WHOIS is a worldwide public database that stores information about all registered domains in the world.
Search query example
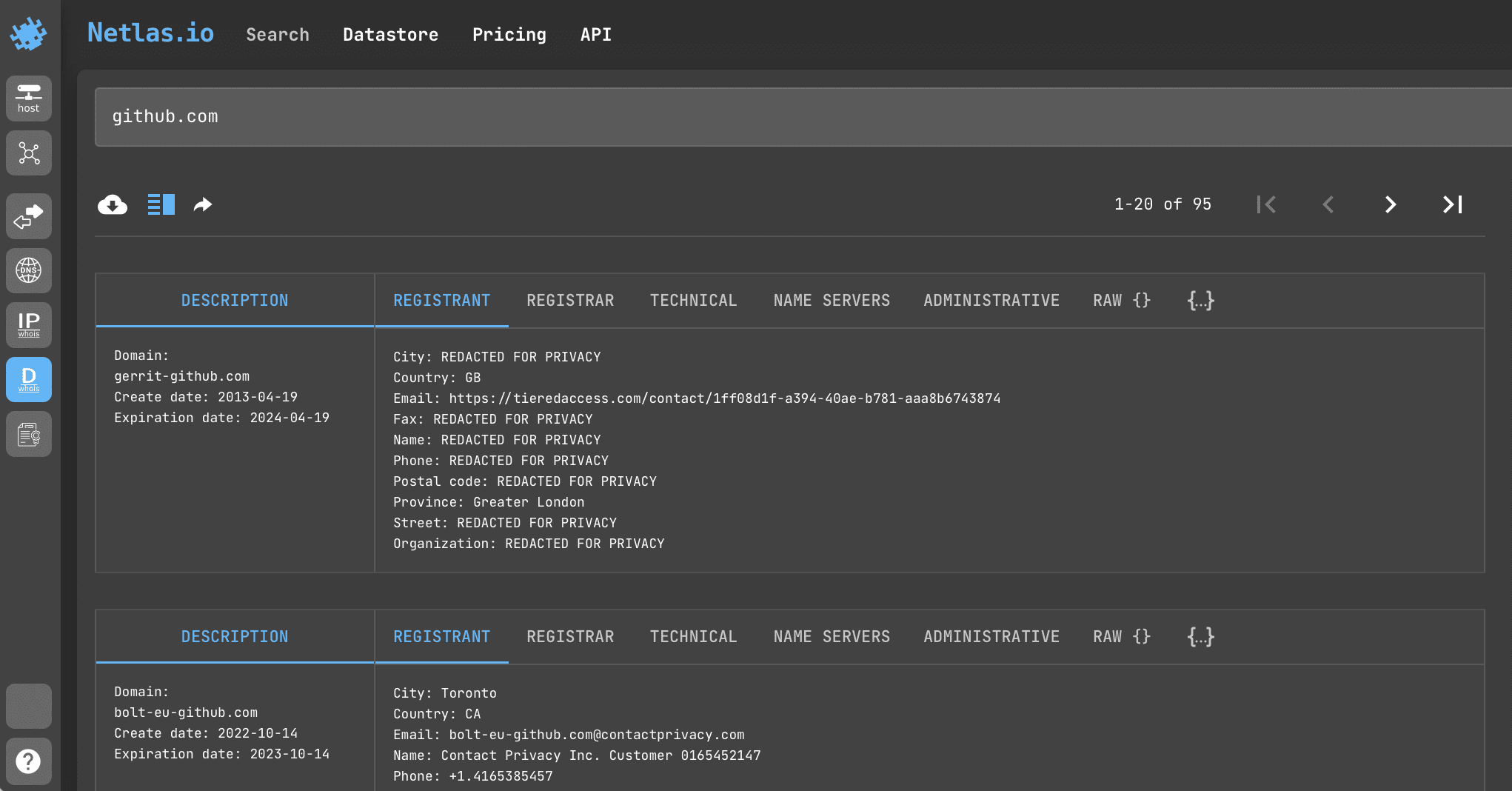
github.comAPI request example
Netlas CLI Tools:
netlas host github.com -f jsonCurl:
curl -X 'GET' \
'https://app.netlas.io/api/whois_domains/?q=github.com&source_type=include&start=0&fields=*' \
-H 'accept: application/json' \
-H 'X-API-Key: YOUR_API_KEY' | jq .items[].data.technical.streetCode example (Netlas Python Library)
Run in command line:
python scripts/osint/whois_search.pySource code of scripts/osint/whois_search.py:
import netlas
apikey = "YOUR_API_KEY"
# create new connection to Netlas
netlas_connection = netlas.Netlas(api_key=apikey)
# retrieve data from whois for google.com domain
netlas_query = netlas_connection.query(query="google.com",datatype="whois-domain")
# iterate over data and print: owner name
for response in netlas_query['items']:
print (response['data']['technical']['name']) Search Location in <address> Tag
<address> tag is located inside the <head> tag of a web page and may contain physical addresses. With a search using this tag, you can find sites associated with a particular street, and sometimes even a particular building.
Search query example
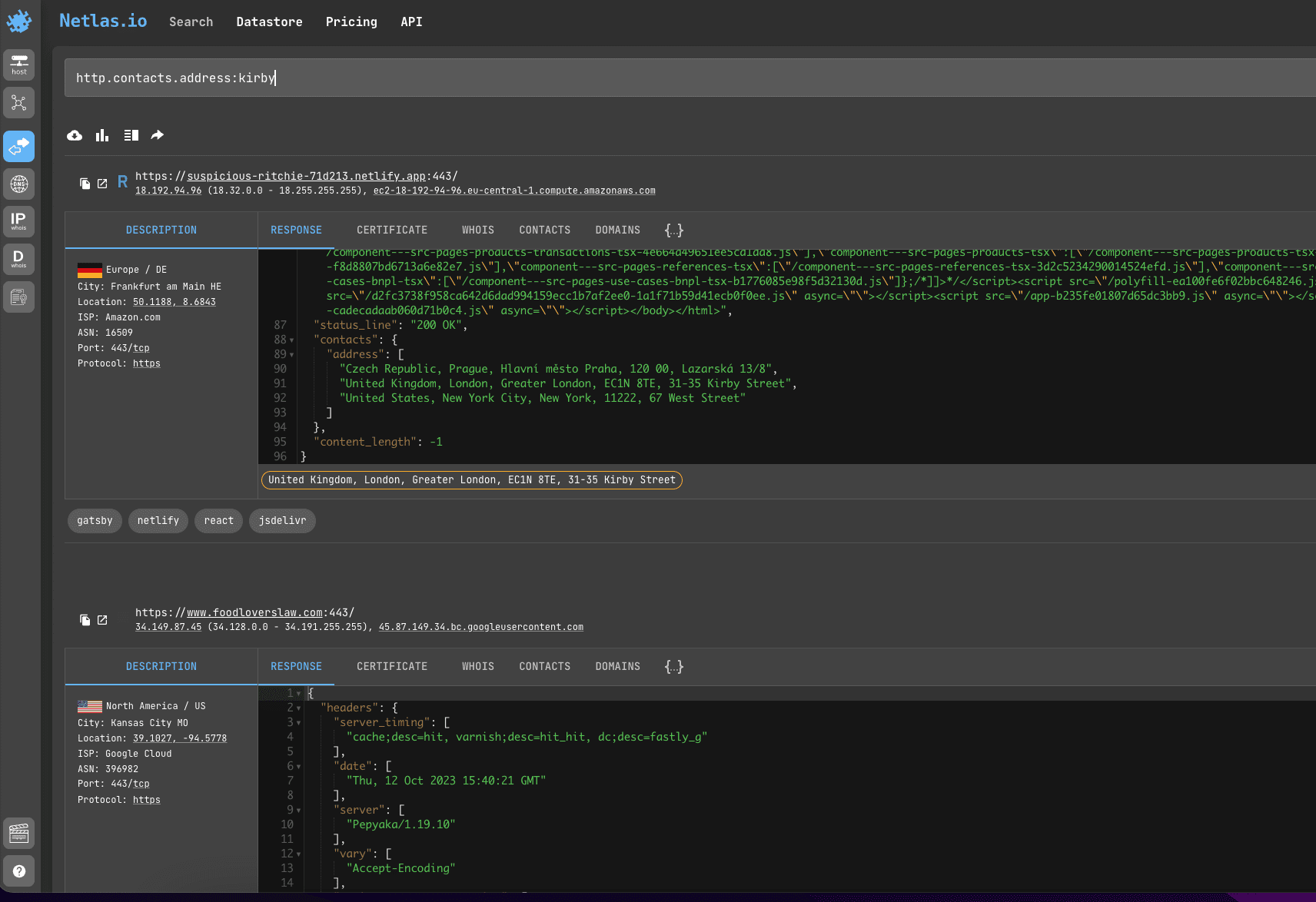
http.contacts.address:kirbyYou can also use http.contacts.email: for email search.
API request example
Netlas CLI Tools:
netlas search "http.contacts.address:kirby" -f jsonCurl:
curl -X 'GET' \
'https://app.netlas.io/api/responses/?q=http.contacts.address%3Akirby&source_type=include&start=0&fields=*' \
-H 'accept: application/json' \
-H 'X-API-Key: 'YOUR_API_KEY' | jq .items[].data.http.contactsCode example (Netlas Python Library)
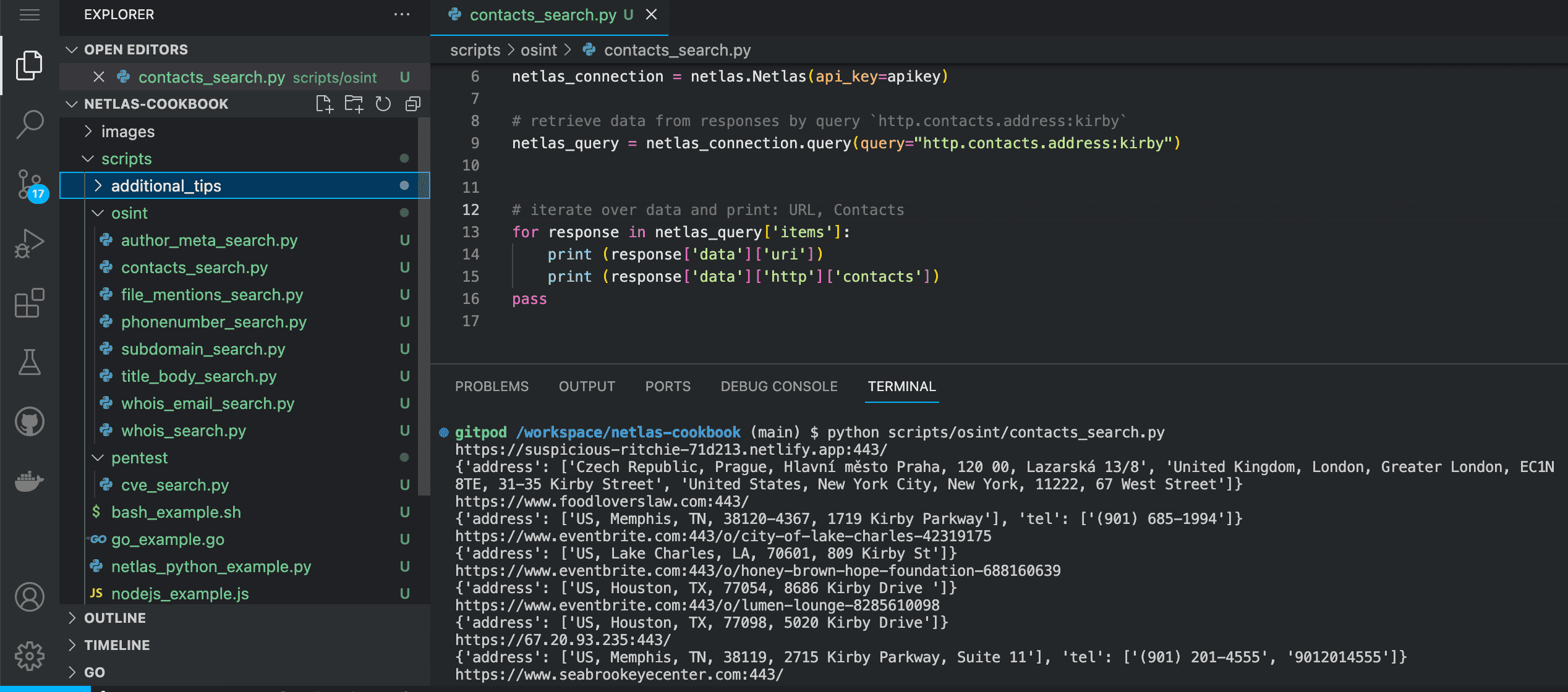
Run in command line:
python scripts/osint/contacts_search.pySource code of scripts/osint/contacts_search.py:
import netlas
apikey = "YOUR_API_KEY"
# create new connection to Netlas
netlas_connection = netlas.Netlas(api_key=apikey)
# retrieve data from responses by query `http.contacts.address:kirby`
netlas_query = netlas_connection.query(query="http.contacts.address:kirby")
# iterate over data and print: URL, Contacts
for response in netlas_query['items']:
print (response['data']['uri'])
print (response['data']['http']['contacts'])Search Author Name in Meta Tags
<meta> tags are located inside the <head> tag of a web page and contain the most important keywords, description, miscellaneous service information and the author’s name.
Searching for nickname and name/surname by meta tags (http.meta) allows you to find sites associated with a particular person faster than searching the entire html code (http.body).
Search query example
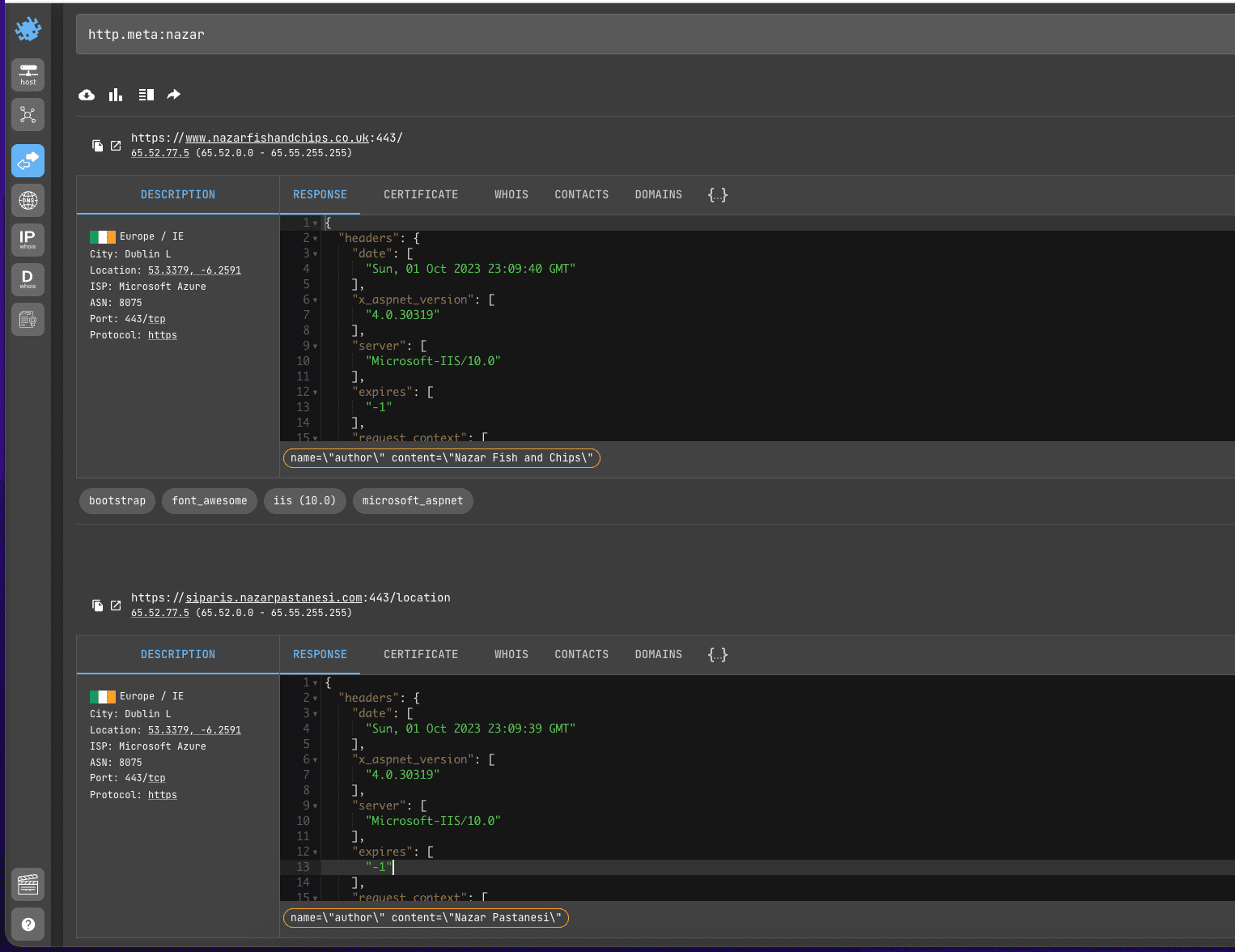
http.meta:nazarAPI request example
Netlas CLI Tools:
netlas search "http.meta:nazar" -f jsonCurl:
curl -X 'GET' \
'https://app.netlas.io/api/responses/?q=http.meta%3Anazar&source_type=include&start=0&fields=*' \
-H 'accept: application/json' \
-H 'X-API-Key: YOUR_API_KEY' | jq .items[].data.http.metaCode example (Netlas Python Library)
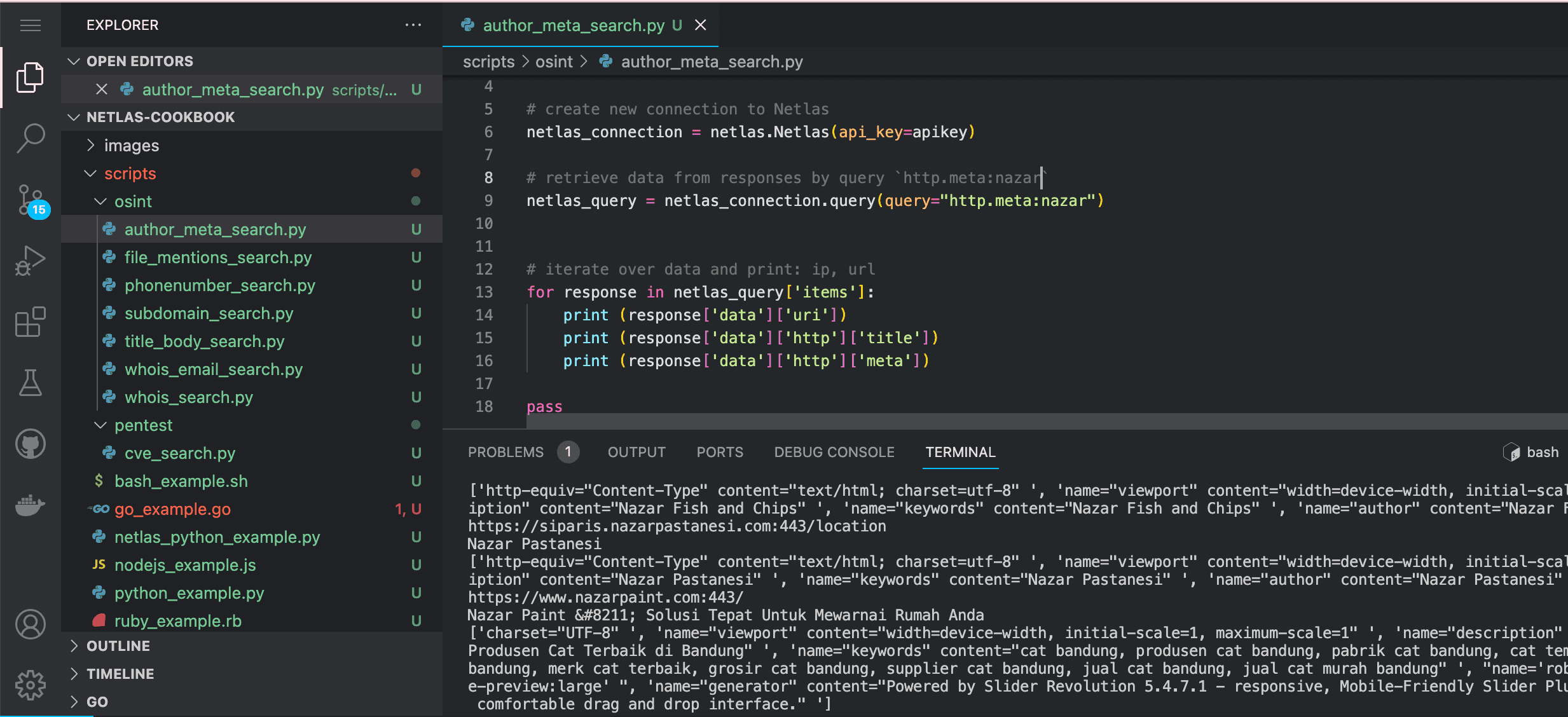
Run in command line:
python scripts/osint/author_meta_search.pySource code of scripts/osint/author_meta_search.py:
import netlas
apikey = "YOUR_API_KEY"
# create new connection to Netlas
netlas_connection = netlas.Netlas(api_key=apikey)
# retrieve data from responses by query `http.meta:nazar`
netlas_query = netlas_connection.query(query="http.meta:nazar")
# iterate over data and print: ip, url
for response in netlas_query['items']:
print (response['data']['uri'])
print (response['data']['http']['title'])
print (response['data']['http']['meta'])What Other Interesting Things Can Be Found in the Meta Tags of HTML Document?
In addition to the author’s name, meta tags can contain a variety of information: encoding, language, permission to index the page by search engine robots, text for link cards in social networks, OpenGraph metadata, and much more. Here are some more examples of meta tags that may contain useful information for investigations:
<meta name="description">- description of web page content.<meta name="keywords">- keywords that describe the content of the web page.<meta name="generator">- name of the tool that was used to generate the page content (useful for searching CMS and hosting platforms)<meta name="copyright">- the name of the person or company who owns the copyright to the content of the web page.
Search by FTP Server’s Banners Text
Another important step in finding information about a person or company is to look for its mention in the text of FTP server banners. It is possible that the IP address of the found servers will be the key to finding other sites related to the person or company you are interested in. And in case of very strong luck to find something interesting in the files posted there (if the FTP server is open).
Search query example
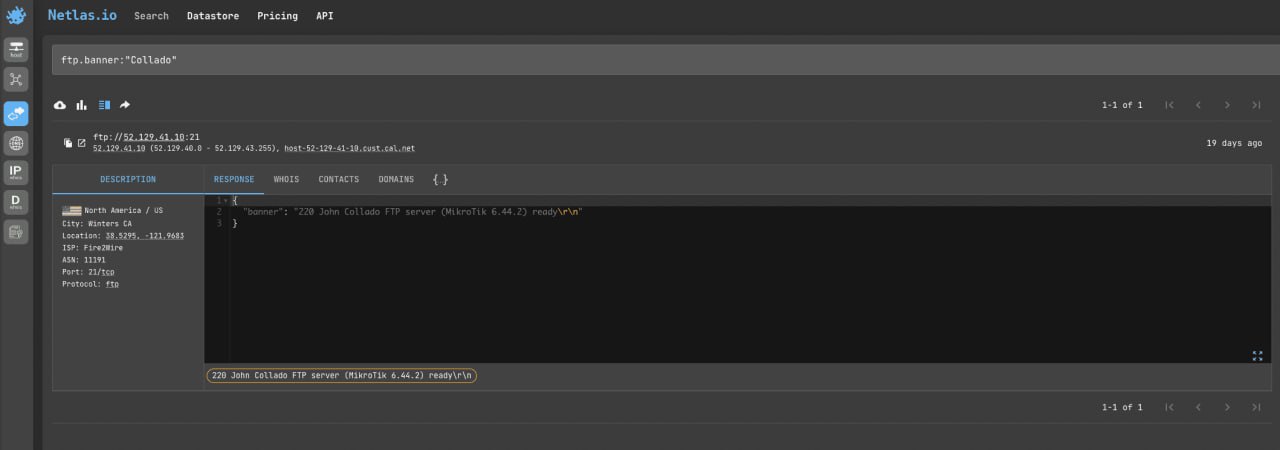
ftp.banner:"Collado" If you need to search for FTP servers by some other parameter (such as city or IP address range), then use the prot7:ftp filter.
API request example
Netlas CLI Tools:
netlas search 'ftp.banner:"Collado"' -f jsonNote that when double quotes are used in queries, the query itself is written inside single quotes.
Curl:
curl -X 'GET' \
'https://app.netlas.io/api/responses/?q=ftp.banner%3A%22Collado%22&source_type=include&start=0&fields=*' \
-H 'accept: application/json' \
-H 'X-API-Key: YOUR_API_KEY' | jq .items[].data.uriCode example (Netlas Python Library)
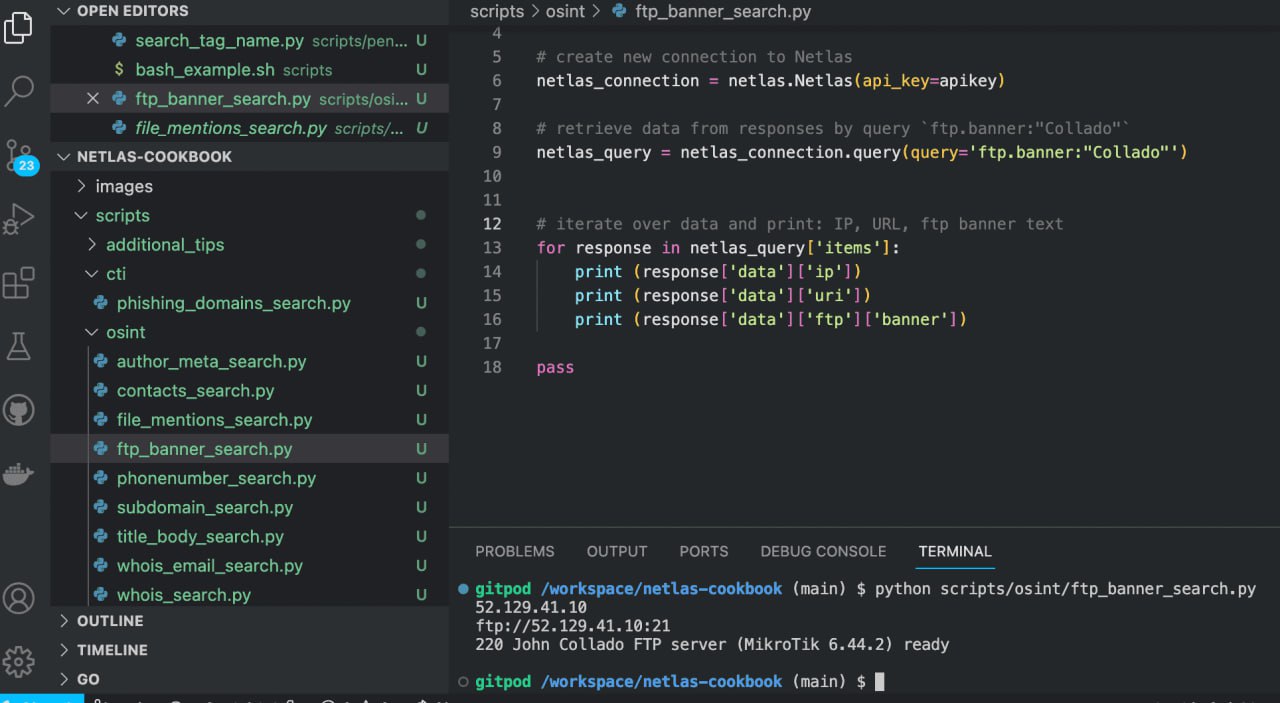
Run in command line:
python scripts/osint/ftp_banner_search.pySource code of scripts/osint/ftp_banner_search.py:
import netlas
apikey = "YOUR_API_KEY"
# create new connection to Netlas
netlas_connection = netlas.Netlas(api_key=apikey)
# retrieve data from responses by query `ftp.banner:"Collado"`
netlas_query = netlas_connection.query(query='ftp.banner:"Collado"')
# iterate over data and print: IP, URL, ftp banner text
for response in netlas_query['items']:
print (response['data']['ip'])
print (response['data']['uri'])
print (response['data']['ftp']['banner'])Search for Contact Information in SSL Certificates
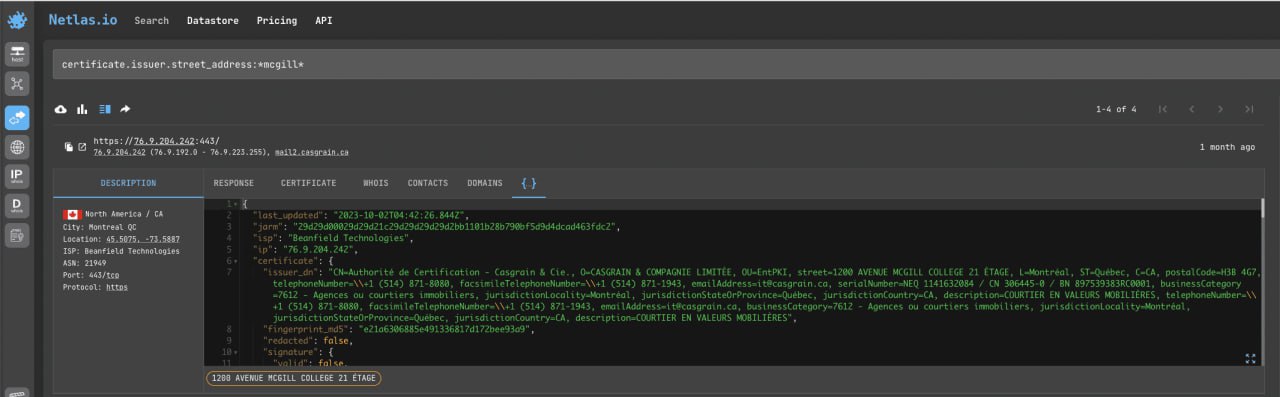
An SSL Certificate is a digital certificate that authenticates a website and allows the use of an encrypted connection. It may contain information about it owner: name of the contact person, name of the organisation, country and sometimes even the address and postcode. You can search this information using the following filters (and many others):
certificate.issuer.email_addresscertificate.issuer.given_namecertificate.issuer.organizationcertificate.issuer.postal_codecertificate.issuer.street_addresscertificate.issuer.surname
Let’s try to find IP addresses that have a certain word in the street address in their certificate:
certificate.issuer.street_address:*mcgill*API request example
Netlas CLI Tools:
netlas search "certificate.issuer.street_address:*mcgill*" -f jsonCurl:
curl -X 'GET' \
'https://app.netlas.io/api/responses/?q=certificate.issuer.street_address%3A*mcgill*&source_type=include&start=0&fields=*' \
-H 'accept: application/json' \
-H 'X-API-Key: YOUR_API_KEY' jq .items[].data.uriCode example (Netlas Python Library)
Run in command line:
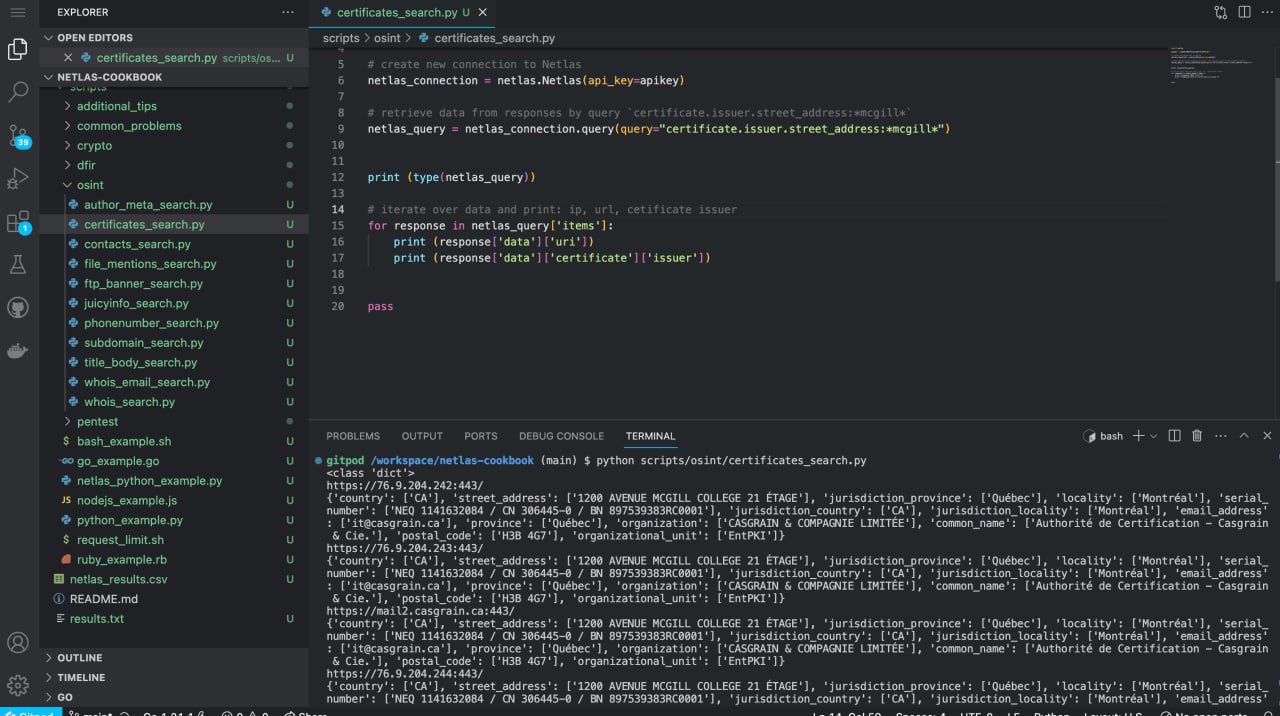
python scripts/osint/certificates_search.pySource code of scripts/osint/certificates_search.py:
import netlas
apikey = "YOUR_API_KEY"
# create new connection to Netlas
netlas_connection = netlas.Netlas(api_key=apikey)
# retrieve data from responses by query `certificate.issuer.street_address:*mcgill*`
netlas_query = netlas_connection.query(query="certificate.issuer.street_address:*mcgill*")
print (type(netlas_query))
# iterate over data and print: ip, url, cetificate issuer
for response in netlas_query['items']:
print (response['data']['uri'])
print (response['data']['certificate']['issuer']) Using Netlas as an Alternative to the WayBack Machine
Archive.org has been used by OSINT specialists to search old versions of websites and social media profiles pages to find now deleted contact and other information.
But, unfortunately, archive.org does not save copies of all sites and does not do it very often (for some sites only a couple of times a year or less).
But Netlas is saving old versions of sites from 2021 too!
Following filters are most often used to search for sites:
http.title:"github.com"domain:github.comhost:github.com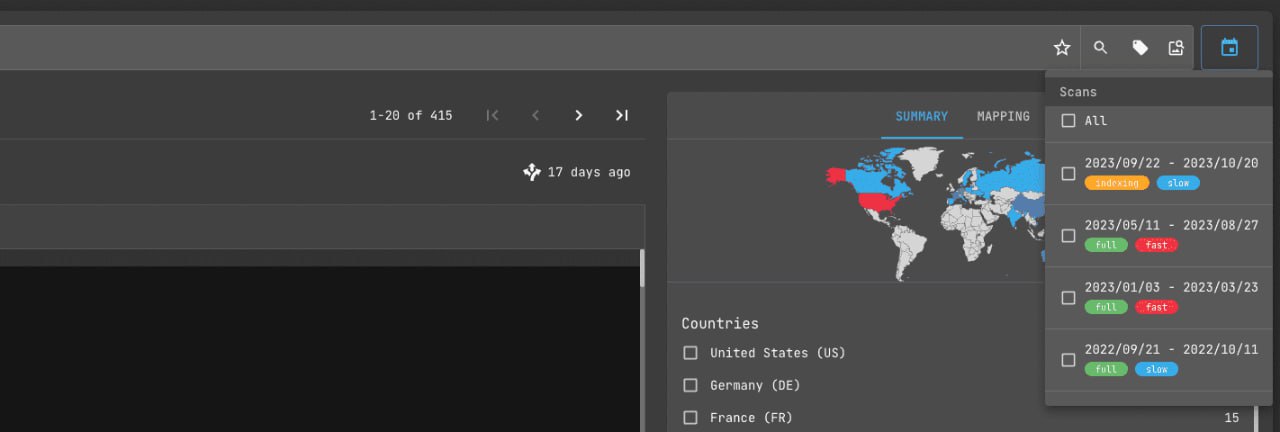
If you click on the outermost icon on the right next to the field for entering search queries, you will see a menu for selecting a scan date. You can use it to filter the html codes of sites saved on a specific date.
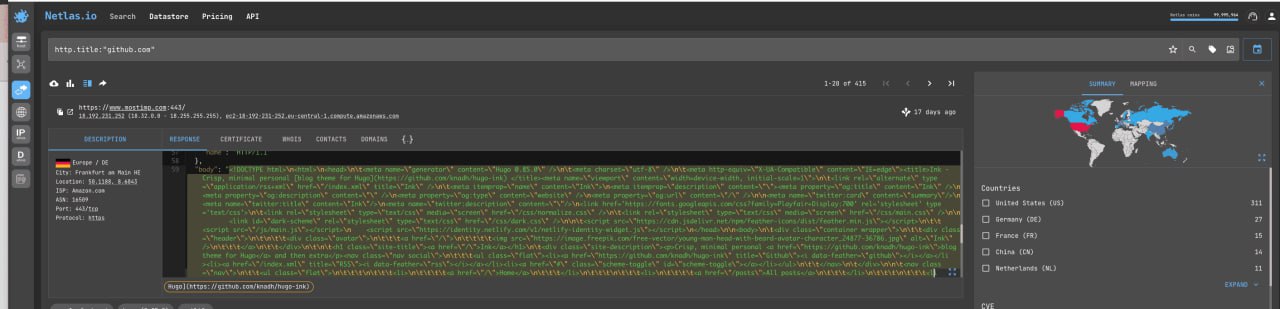
To see how the site looks, copy the contents of the “body” field (response tab) into any text editor and delete the \t\r\n characters from the html code.
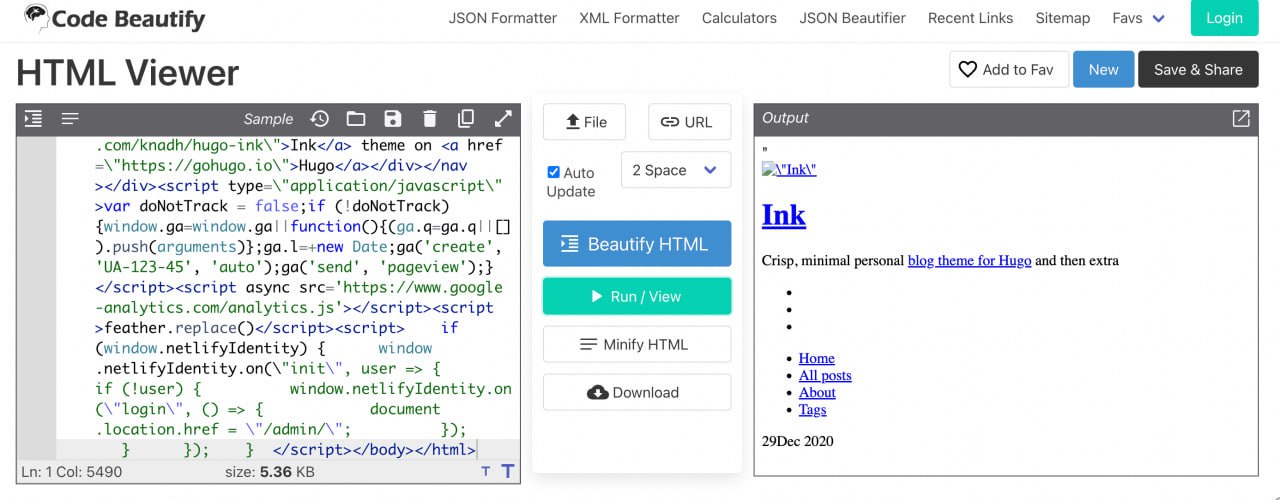
After that, copy the code into one of the online html promoters, such as Code beautify. Or just save the file in html format and then open it in browser.
9 Ways to Search Related Websites
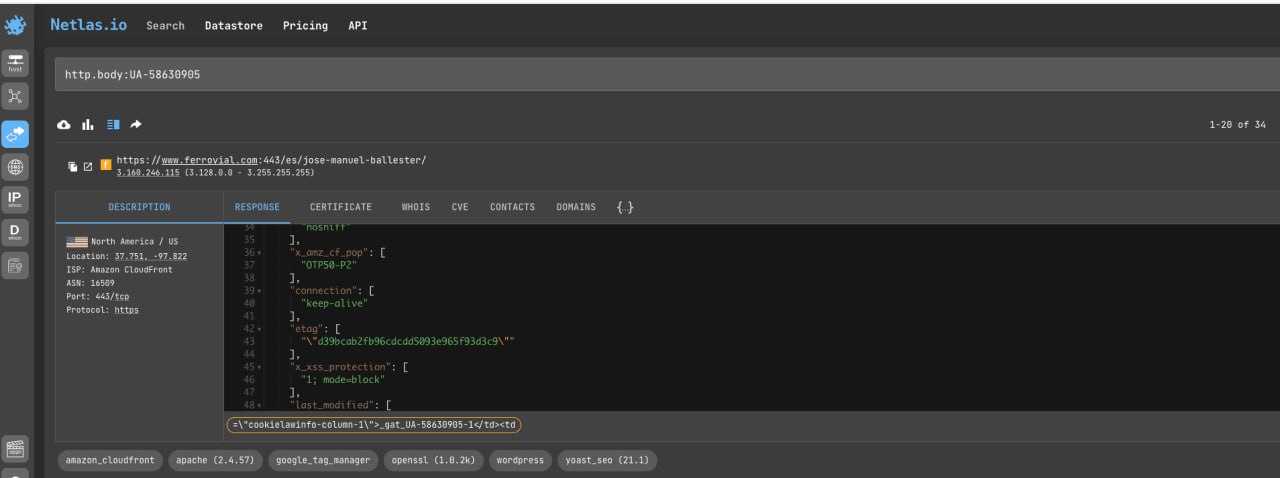
When gathering information about a person or company, it can be important to find as many sites as possible that can be related to them in some way. There are at least 5 ways to do this with Netlas.
- ID for various services (analytics, advertising systems, applications for integration with social networks and publishing systems). Their overlap may indicate that one person or team was involved. Few examples:
Google Analytics:
http.tracker.google_analytics:"G-X82FSVSMTV"Google Tag Manager:
http.tracker.google_analytics:"GTM-N6462KFQ"AddThis:
http.body:"AT-ra-500bcd681b192302"Facebook Pixel:
http.tracker.facebook_pixel:317853189093681Yandex Metrika
http.tracker.yandex_metrica:89723437Amazon Publisher Servies:
http.body:APS-XXXXYes, it’s all found in the code on some sites.
And a host of other indetifiers that can most often be found at the top of the html code (but sometimes all over the code).
- ID of affiliate programmes (also use http.body for search it). You can find them in affiliate links that a person publishes on other sites or in social networks. These can be the following URL parameters (and their like):
aff_fcid=
user_id=
partner_id=
ref_id=- Search by organization name in Domain Whois Netlas search
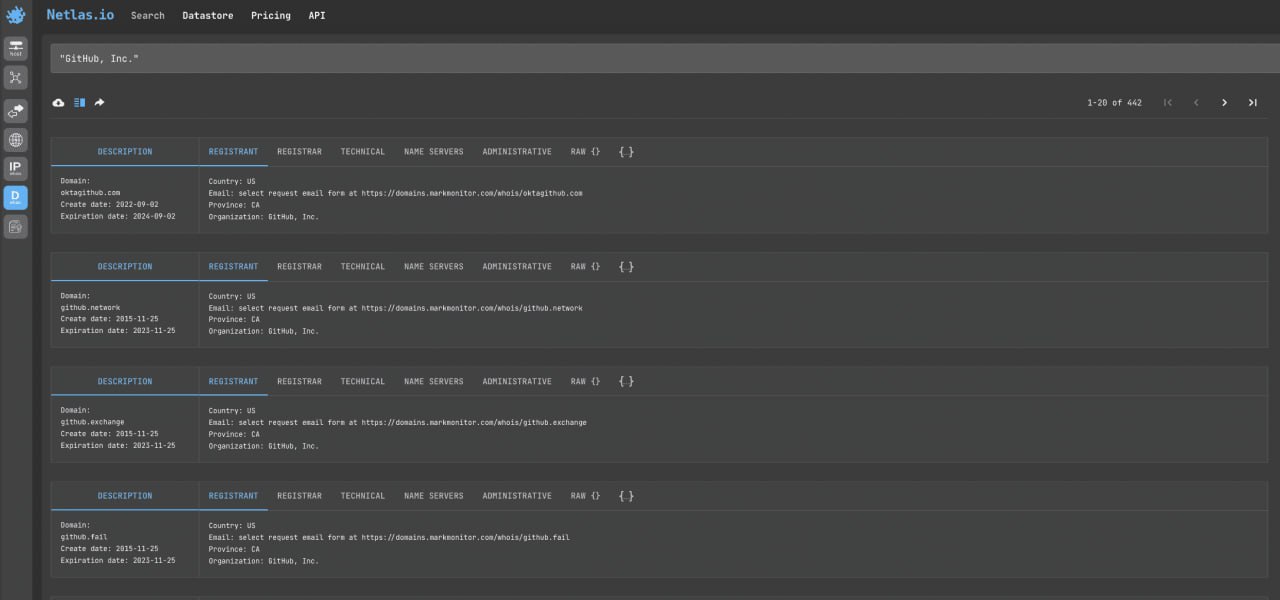
"GitHub, Inc."- Search by mail servers in DNS Netlas search
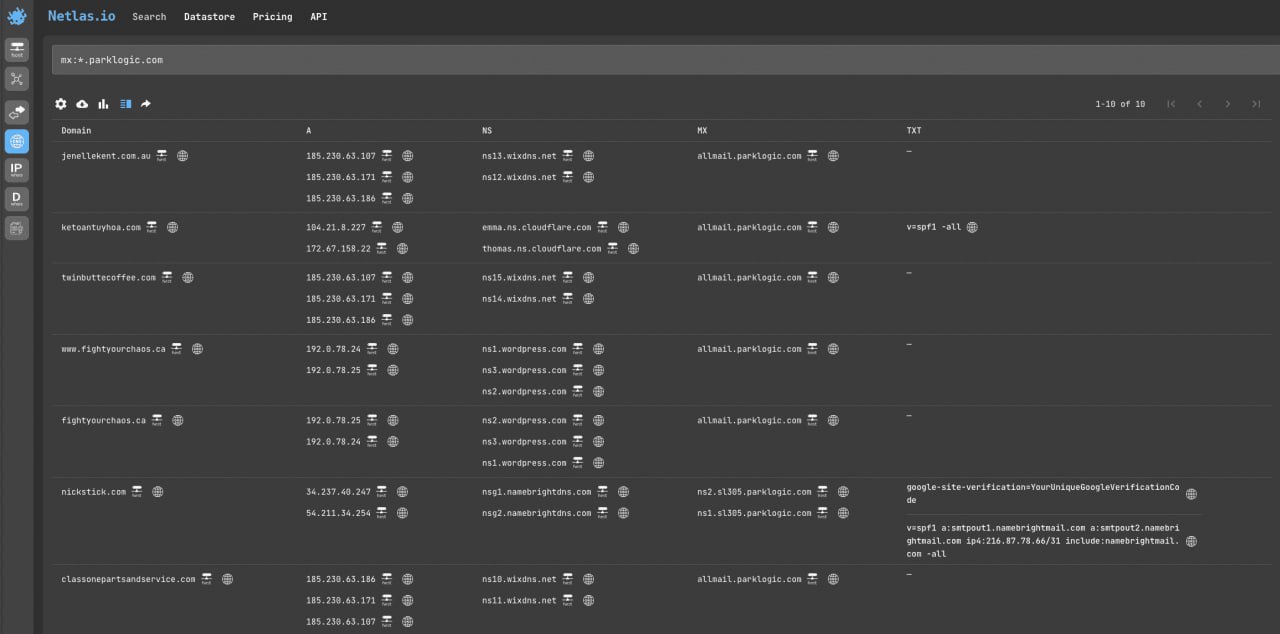
mx:*.parklogic.com- Search by name servers in DNS Netlas search
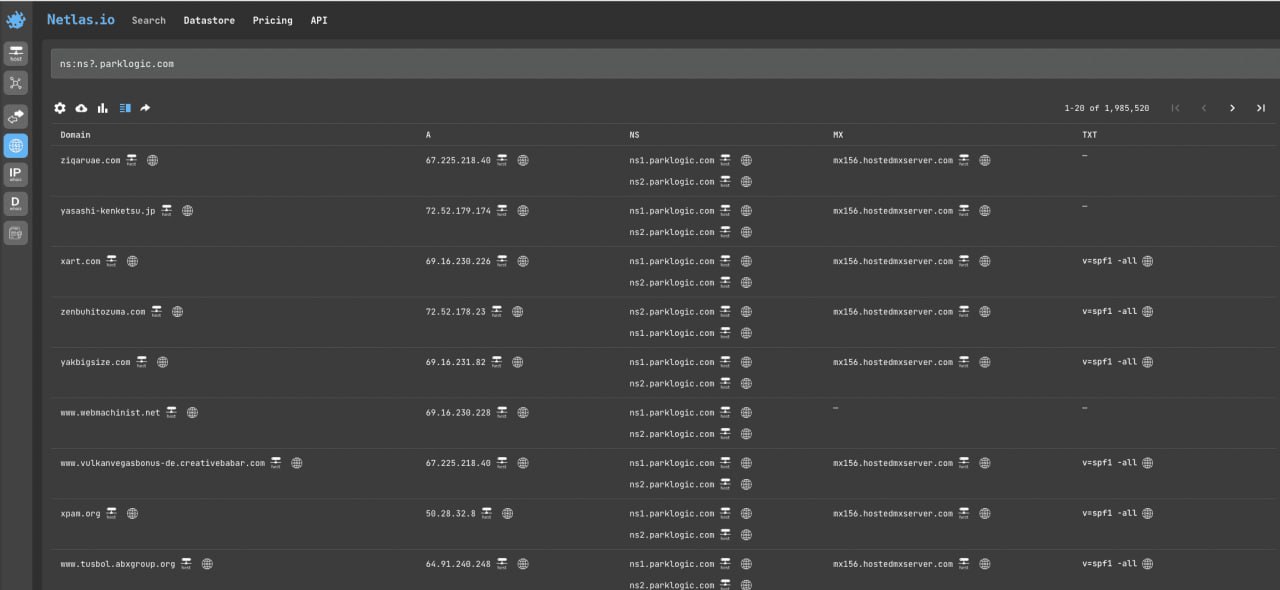
ns:ns?.parklogic.comFiles (primarily user logos and avatars) mentions search ->
Subdomain search ->
Whois contacts search (in Netlas response search) ->
Favicon search ->
Scraping (Extract Data from Web Page Body)
Netlas API is a great tool for collecting contact and other website data. First, it allows you to do it quickly. Second, it does not require the use of proxy. Third, it allows you to collect data from sites that are currently unavailable.
However, there are some disadvantages: Netlas scans only the main pages of sites and some rare sites are not included in its database due to protection. But it can still be of great use.
There are three main approaches to scraping: collecting information from html tags and CSS selectors, extracting data using regular expressions, and AI scraping. Let’s take a closer look at the first two.
Beatifulsoup Package
Beatifulsoup is one of the world’s most popular Python packages for parsing HTML code and XML files. Let’s try using it to extract page titles (from <h1> tags, NOT <title> tages).
First, install package:
pip install beautifulsoup4And Run scripts/osint/scraping_beatifulsoup.py:
python scripts/osint/scraping_beatifulsoup.py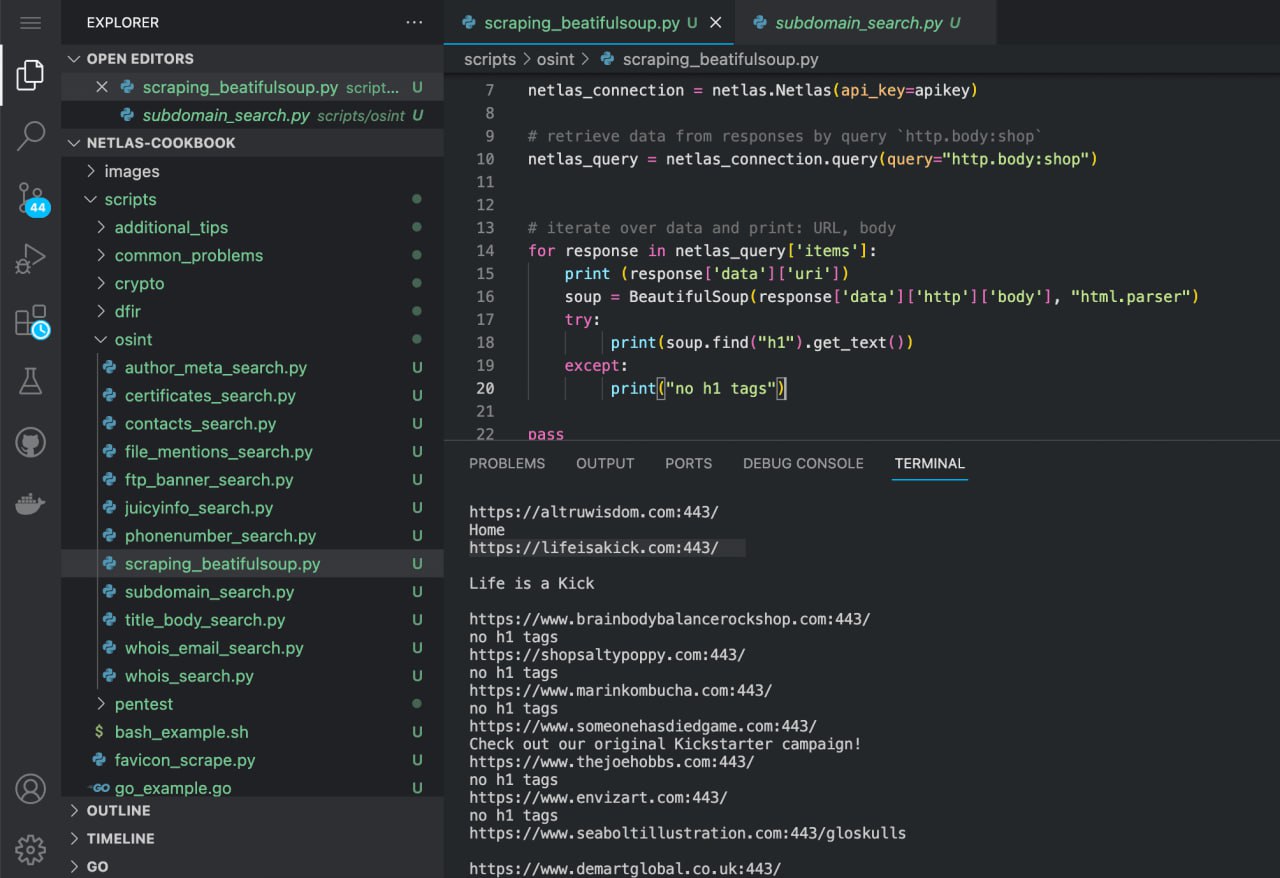
Source code of scripts/osint/scraping_beatifulsoup.py:
import netlas
from bs4 import BeautifulSoup
apikey = "YOUR_API_KEY"
# create new connection to Netlas
netlas_connection = netlas.Netlas(api_key=apikey)
# retrieve data from responses by query `http.body:shop`
netlas_query = netlas_connection.query(query="http.body:shop")
# iterate over data and print: URL, h1 tags from body
for response in netlas_query['items']:
print (response['data']['uri'])
soup = BeautifulSoup(response['data']['http']['body'], "html.parser")
try:
print(soup.find("h1").get_text())
except Exception:
print("no h1 tags")
passYou can extract data from other elements of web pages in a similar way:
soup.find("h3").get_text()
soup.find("id='loginform'").get_text()
soup.find("class='forms'").get_text()
soup.find("href='https://example.com'").get_text()If you want to find all elements of a certain type use the find_all() method.
Re Package
Re is a pre-installed Python package for searching and retrieving data using regular expressions. It is useful for extracting contact information from web pages and many other tasks. Let’s look at an example of how it works.
Run scripts/osint/scraping_re.py:
python scripts/osint/scraping_re.py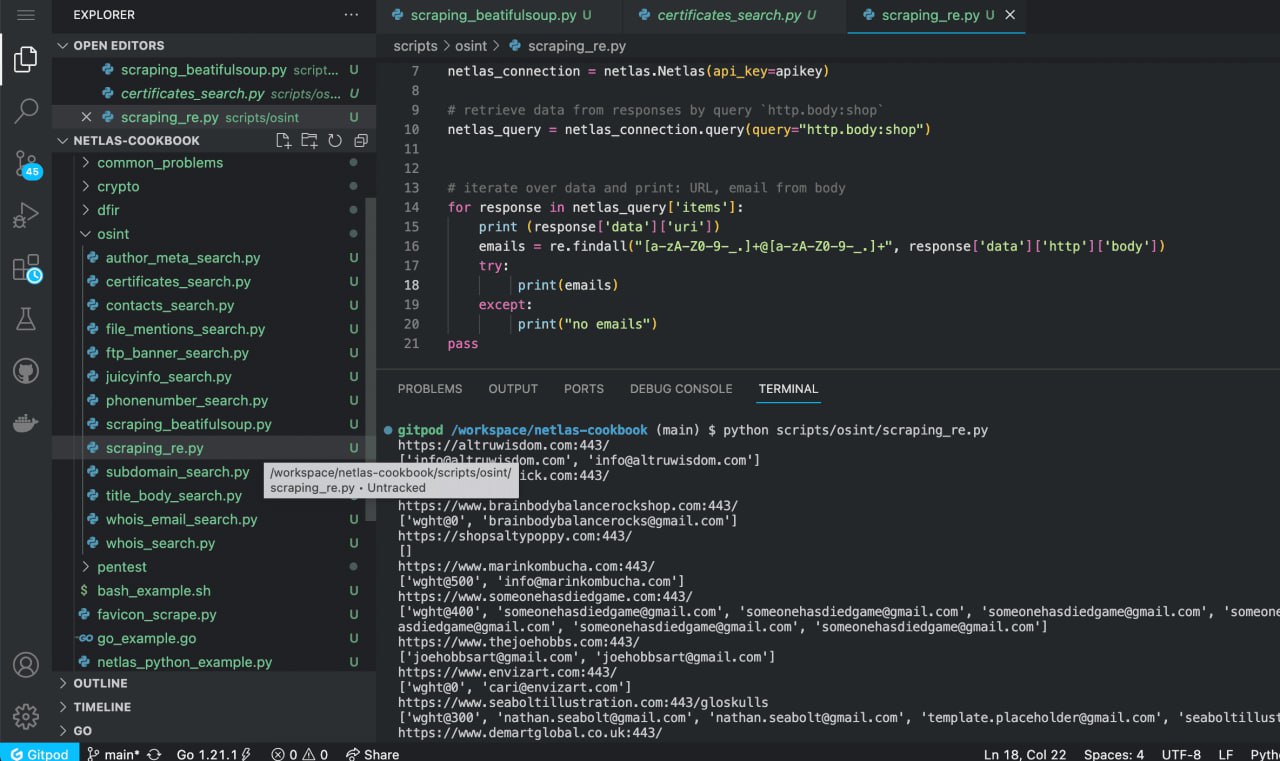
Source code of scripts/osint/scraping_re.py:
import netlas
import re
apikey = "YOUR_API_KEY"
# create new connection to Netlas
netlas_connection = netlas.Netlas(api_key=apikey)
# retrieve data from responses by query `http.body:shop`
netlas_query = netlas_connection.query(query="http.body:shop")
# iterate over data and print: URL, emails from body
for response in netlas_query['items']:
print (response['data']['uri'])
emails = re.findall("[a-zA-Z0-9-_.]+@[a-zA-Z0-9-_.]+", response['data']['http']['body'])
try:
print(emails)
except Exception:
print("no emails")
passSimilarly, you can extract links, phone numbers, cryptocurrency wallet addresses and more. Ready patterns can be found in regular expression libraries:
Regex Lib UI Bakery Regex Library Regex 101
Other Python Packages for Scraping
Beaitiful soup and Re packages are just one of the many tools for scraping data from web pages using Python. Here are some more examples of such packages:
- Scrapy: It is primarily a crawler (a tool for traversing website pages using links found on other pages) and, in addition, it has extensive capabilities for extracting data from web pages.
- Selenium: A tool for automating your browser experience. Allows you to extract data from contentthat is generated by JavaScript.
- Lxml: Tool for scraping and validate XML files.
- PDFtoText - tool for extracting text content from PDF files.
- pyChatGPT - unofficial package for interaction with CHATGP (does not require OpenAI API key), which allows analyzing text information with AI.
Using Netlas.io for Crypto Investigations
Netlas provides a great opportunity for researchers who specialise in cryptocurrency crime. Firstly, it can be used to search for references to wallet addresses and transaction numbers. Second, it can be used to search for vulnerable mining farms, nodes and other servers associated with crypto infrastructure.
Search Mining Farms
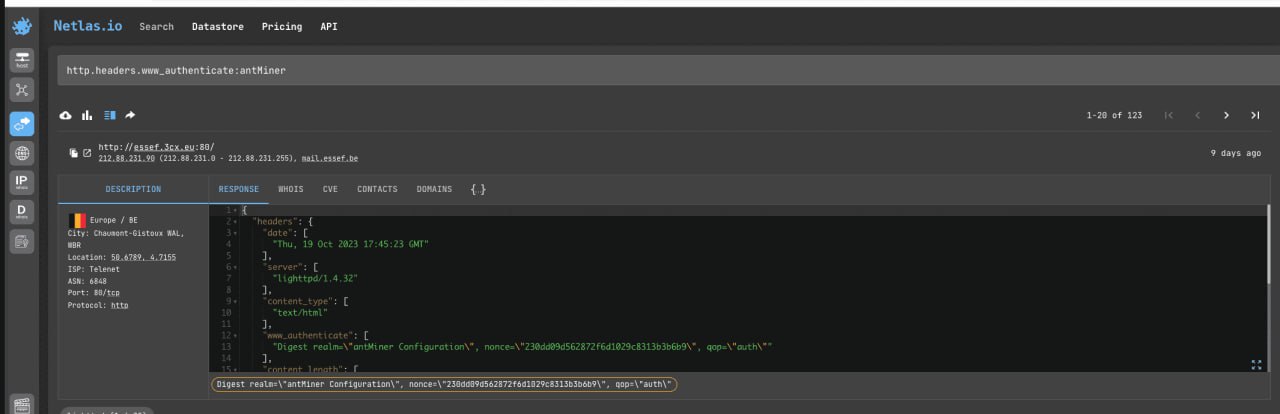
Antminer mining farms, which were first released by Bitmain back in 2013, are one of the most popular line of mining farm models in the world. You can find them by the presence of the word “antMiner” in the www_authenticate header.
http.headers.www_authenticate:antMinerYou can also search for other types of mining farms. For examples:
http.headers.www_authenticate:XMR-Stak-MinerExperiment by combining different filters, the words “miner/mining” and cryptocurrency names.
API request example
Netlas CLI Tools:
netlas search "http.headers.www_authenticate:antMiner"Curl:
curl -X 'GET' \
'https://app.netlas.io/api/responses/?q=http.headers.www_authenticate%3AantMiner&source_type=include&start=0&fields=*' \
-H 'accept: application/json' \
-H 'X-API-Key: 'YOUR_API_KEY' | jq .items[].data.uriCode example (Netlas Python Library)
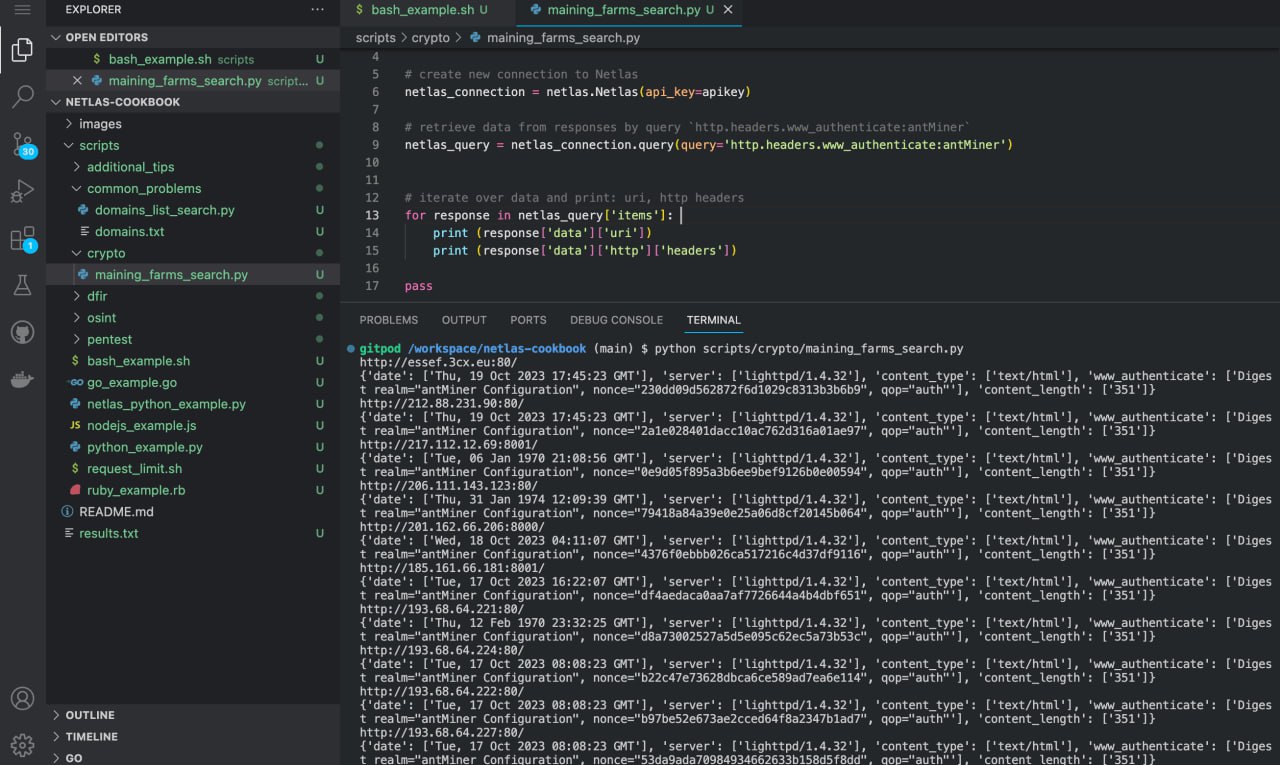
Run in command line:
python scripts/crypto/mining_farms_search.pySource code of scripts/crypto/mining_farms_search.py:
import netlas
apikey = "YOUR_API_KEY"
# create new connection to Netlas
netlas_connection = netlas.Netlas(api_key=apikey)
# retrieve data from responses by query `http.headers.www_authenticate:antMiner`
netlas_query = netlas_connection.query(query='http.headers.www_authenticate:antMiner')
# iterate over data and print: uri, http headers
for response in netlas_query['items']:
print (response['data']['uri'])
print (response['data']['http']['headers'])Search for Websites Infected with Cryptominers
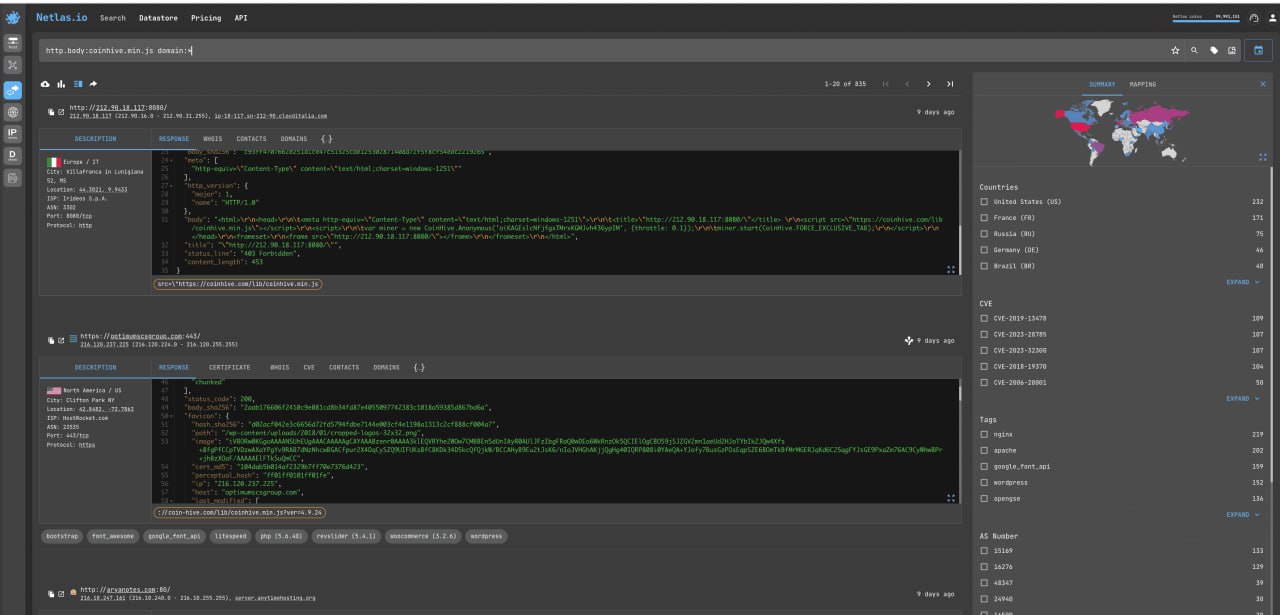
Coinhive, a service that allows websites (mostly hacked) to use their visitor’s computers to mine cryptocurrencies, is shutting down in 2019. But nevertheless, links to it are still embedded in many sites around the world. Let’s try to find them:
http.body:coinhive.min.js domain:*Note that we use the domain:* filter to find sites specifically, not all devices.
Similarly, you can search for sites infected with other cryptominers (as well as other malicious code that executes on the user’s side).
API request example
Netlas CLI Tools:
netlas search "http.body:coinhive.min.js domain:*"Curl:
curl -X 'GET' \
'https://app.netlas.io/api/responses/?q=http.body%3Acoinhive.min.js%20domain%3A*&source_type=include&start=0&fields=*' \
-H 'accept: application/json' \
-H 'X-API-Key: 'YOUR_API_KEY' | jq .items[].data.uriCode example (Netlas Python Library)
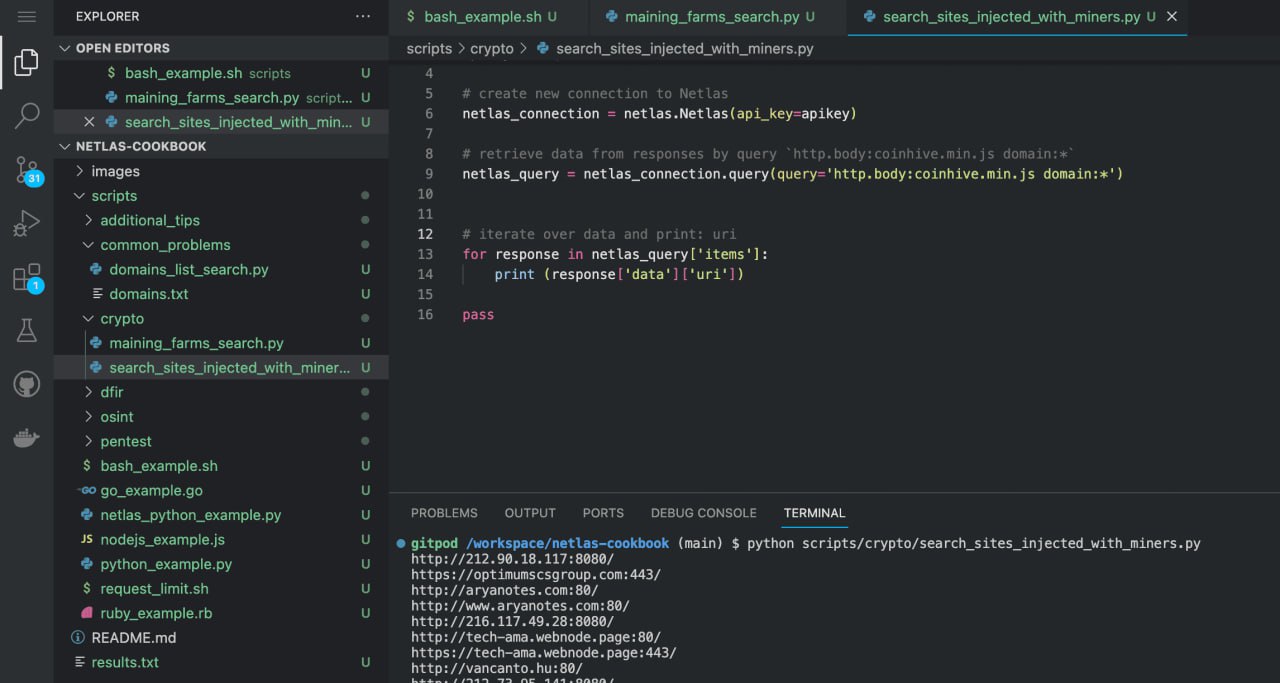
Run in command line:
python scripts/crypto/search_sites_injected_with_miners.pySource code:
import netlas
apikey = "YOUR_API_KEY"
# create new connection to Netlas
netlas_connection = netlas.Netlas(api_key=apikey)
# retrieve data from responses by query `http.body:coinhive.min.js domain:*`
netlas_query = netlas_connection.query(query='http.body:coinhive.min.js domain:*')
# iterate over data and print: uri
for response in netlas_query['items']:
print (response['data']['uri'])Search Vulnerable Bitcoin Nodes
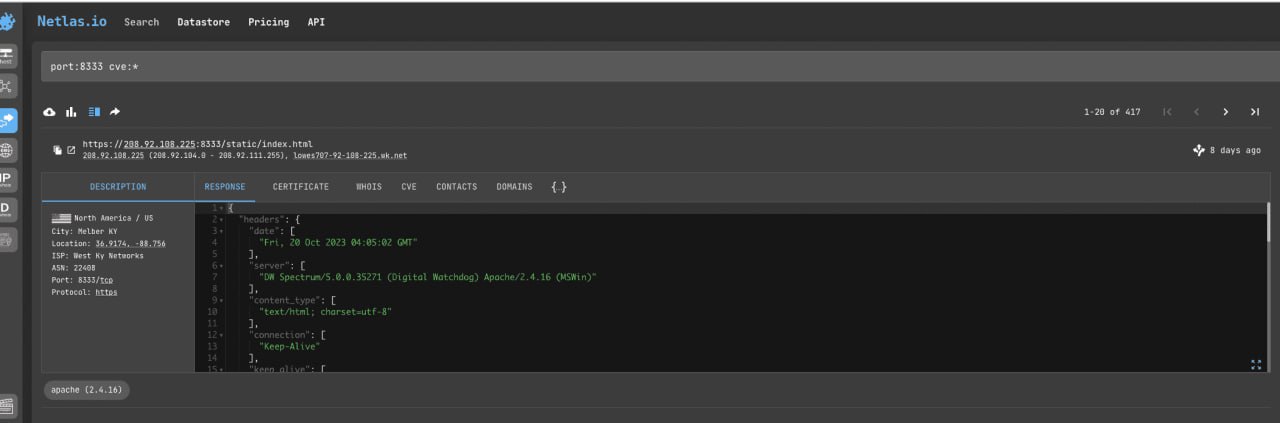
Bitcoin nodes use port 8333 for TCP connection. Therefore, it is easy to find them using the “port:” search filter.
port:8333 cve:*Note that we use the “cve:*” filter to look for servers with vulnerabilities.
API request example
Netlas CLI Tools:
netlas search "port:8333 cve:*"Curl:
curl -X 'GET' \
'https://app.netlas.io/api/responses/?q=port%3A8333%20cve%3A*&source_type=include&start=0&fields=*' \
-H 'accept: application/json' \
-H 'X-API-Key: 'YOUR_API_KEY' | jq .items[].data.uriCode example (Netlas Python Library)
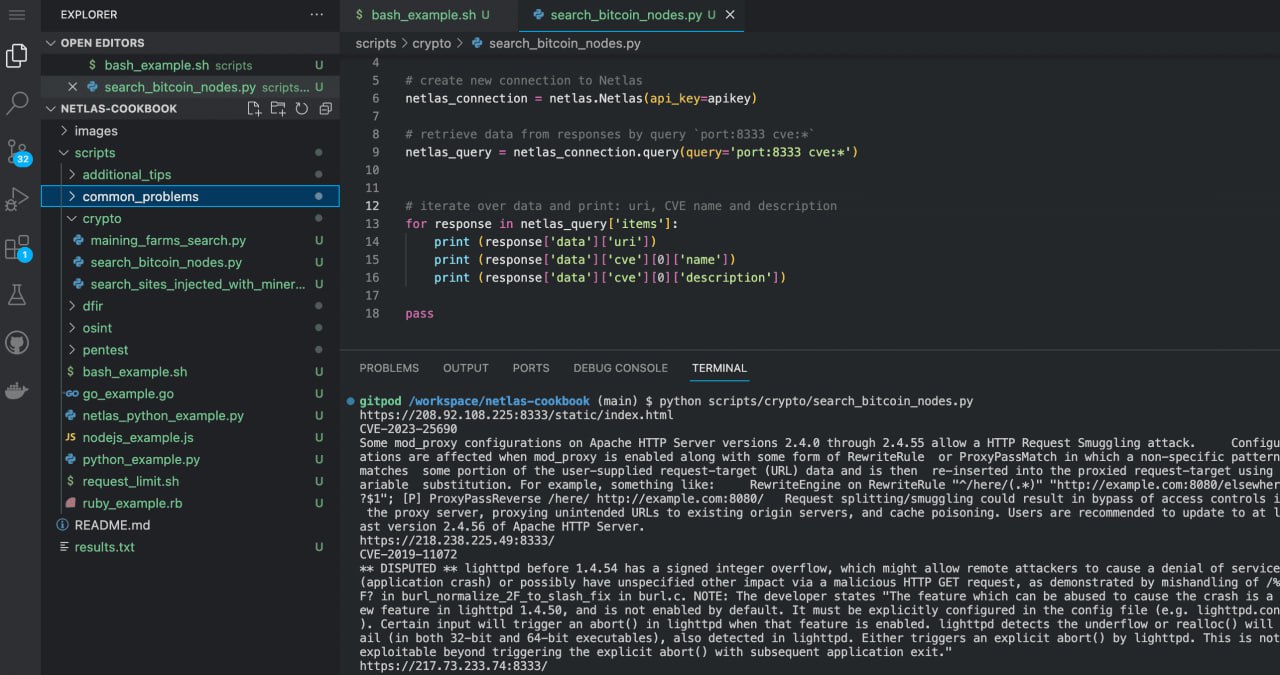
Run in command line:
python scripts/crypto/search_bitcoin_nodes.pySource code of scripts/crypto/search_bitcoin_nodes.py:
import netlas
apikey = "YOUR_API_KEY"
# create new connection to Netlas
netlas_connection = netlas.Netlas(api_key=apikey)
# retrieve data from responses by query `port:8333 cve:*`
netlas_query = netlas_connection.query(query='port:8333 cve:*')
# iterate over data and print: uri, CVE name and description
for response in netlas_query['items']:
print (response['data']['uri'])
print (response['data']['cve'][0]['name'])
print (response['data']['cve'][0]['description'])Using Neltas for Pentest
Netlas.io allows you to search for sites with many different types of vulnerabilities. This can be done by vulnerability number (CVE-…), the name of the software installed on the server, certain words in page headers, and other parameters.
You can track the most recently published CVEs (Common Vulnerabilities and Exposures) on these sites:
We also regularly post most relevant queries to search vulnerable devices and software on our Twitter, Telegram and Discord feeds, as well as Netlas Dorks Github repository.
In this section, we will simply cover the general principles of searching for sites and servers with vulnerabilities.
Subdomain Search
By using asterisks in search queries, you can find all subdomains of different levels (whose name ends with the name of a particular first-level domain (.com) or second-level domain (google.com).
Search query example
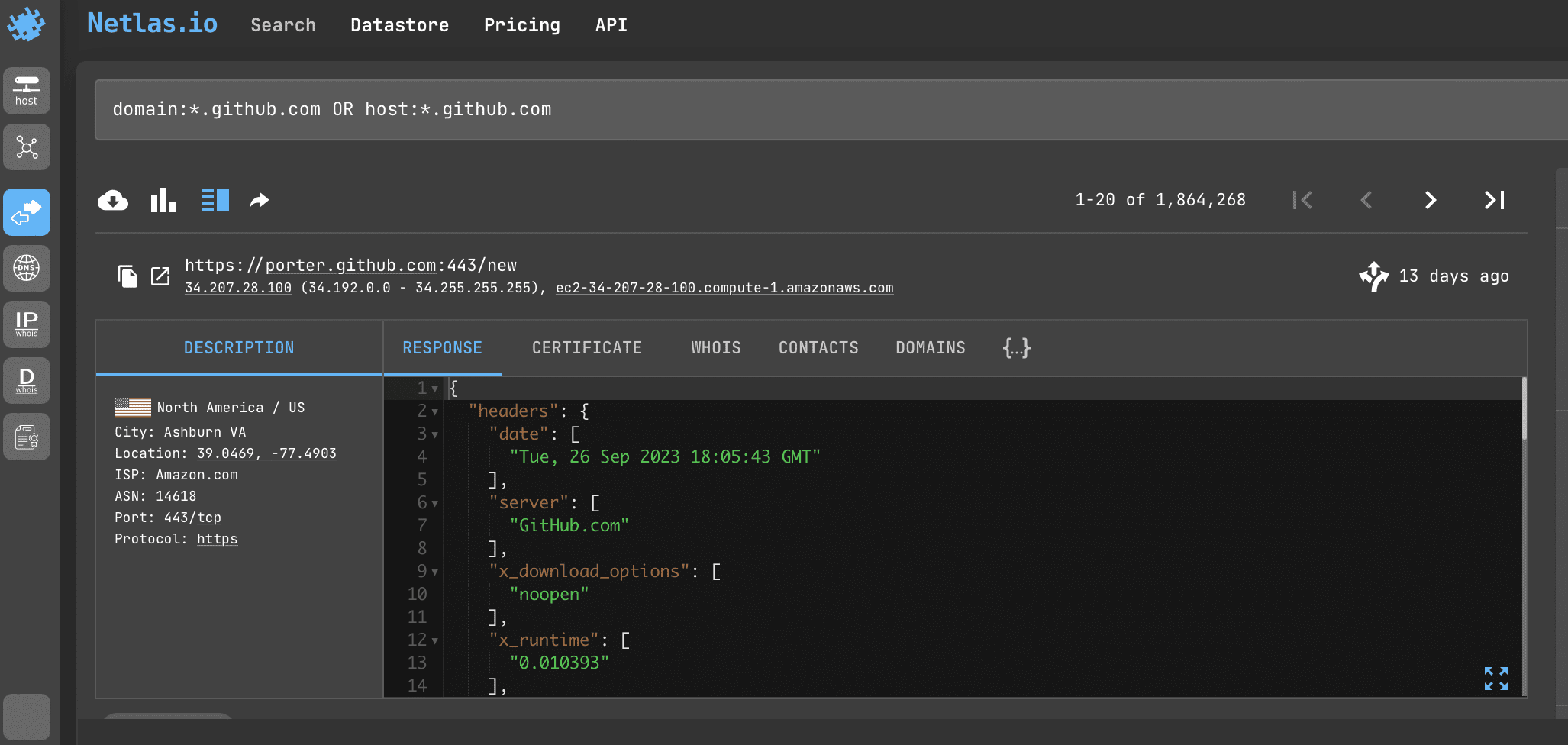
domain:*.github.com OR host:*.github.comAPI request example
Netlas CLI Tools:
netlas search "domain:*.github.com OR host:*.github.com" -f jsonCurl:
curl -X 'GET' \
'https://app.netlas.io/api/responses/?q=domain%3A*.github.com%20OR%20host%3A*.github.com&source_type=include&start=0&fields=*' \
-H 'accept: application/json' \
-H 'X-API-Key: YOUR_API_KEY' | jq .items[].data.uriCode example (Netlas Python Library)
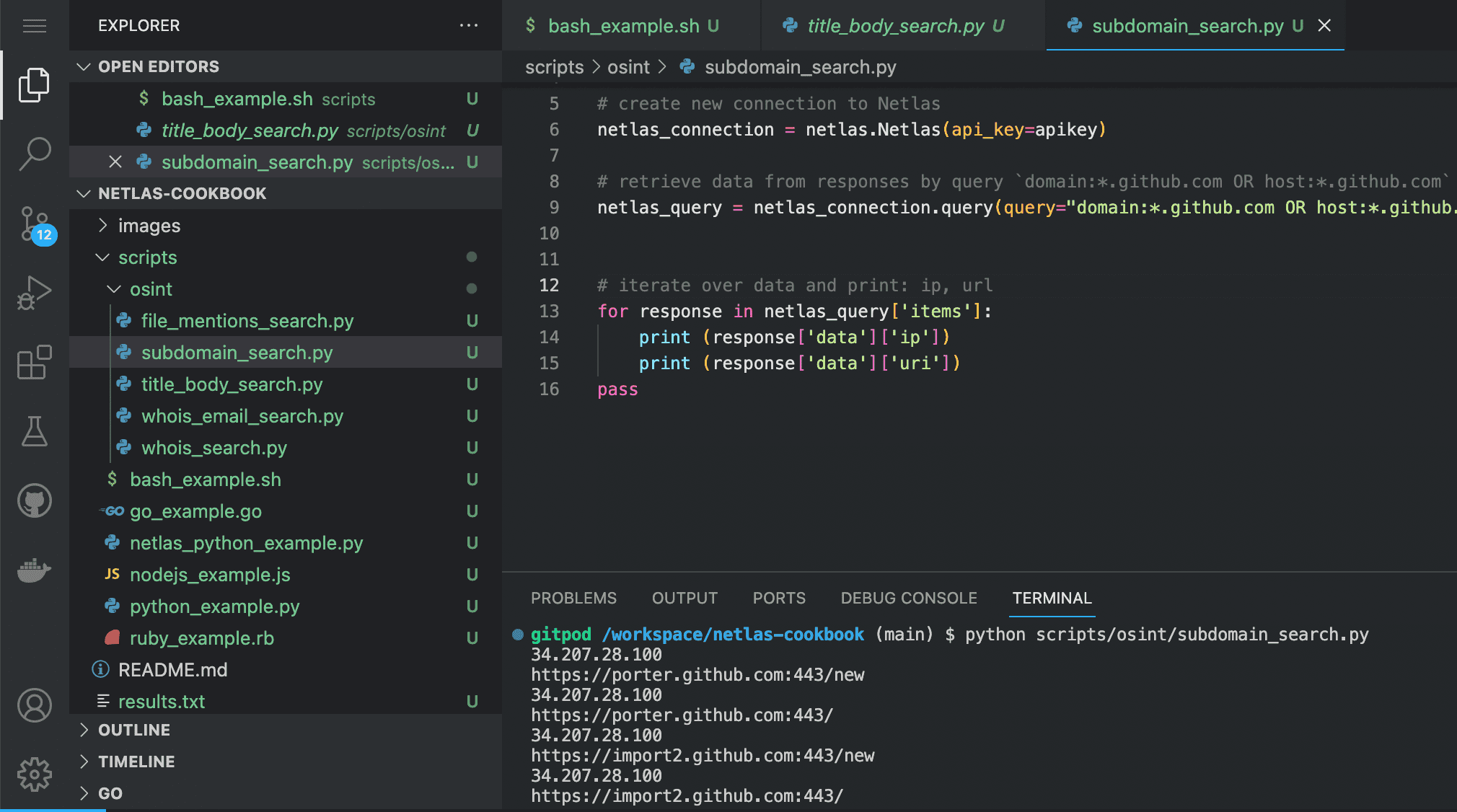
Run in command line:
python scripts/pentest/subdomain_search.pySource code of scripts/pentest/subdomain_search.py:
import netlas
apikey = "YOUR_API_KEY"
# create new connection to Netlas
netlas_connection = netlas.Netlas(api_key=apikey)
# retrieve data from responses by query `domain:*.github.com OR host:*.github.com`
netlas_query = netlas_connection.query(query="domain:*.github.com OR host:*.github.com")
# iterate over data and print: ip, url
for response in netlas_query['items']:
print (response['data']['ip'])
print (response['data']['uri'])Search for Sites with Specific Vulnerabilities
Search query example
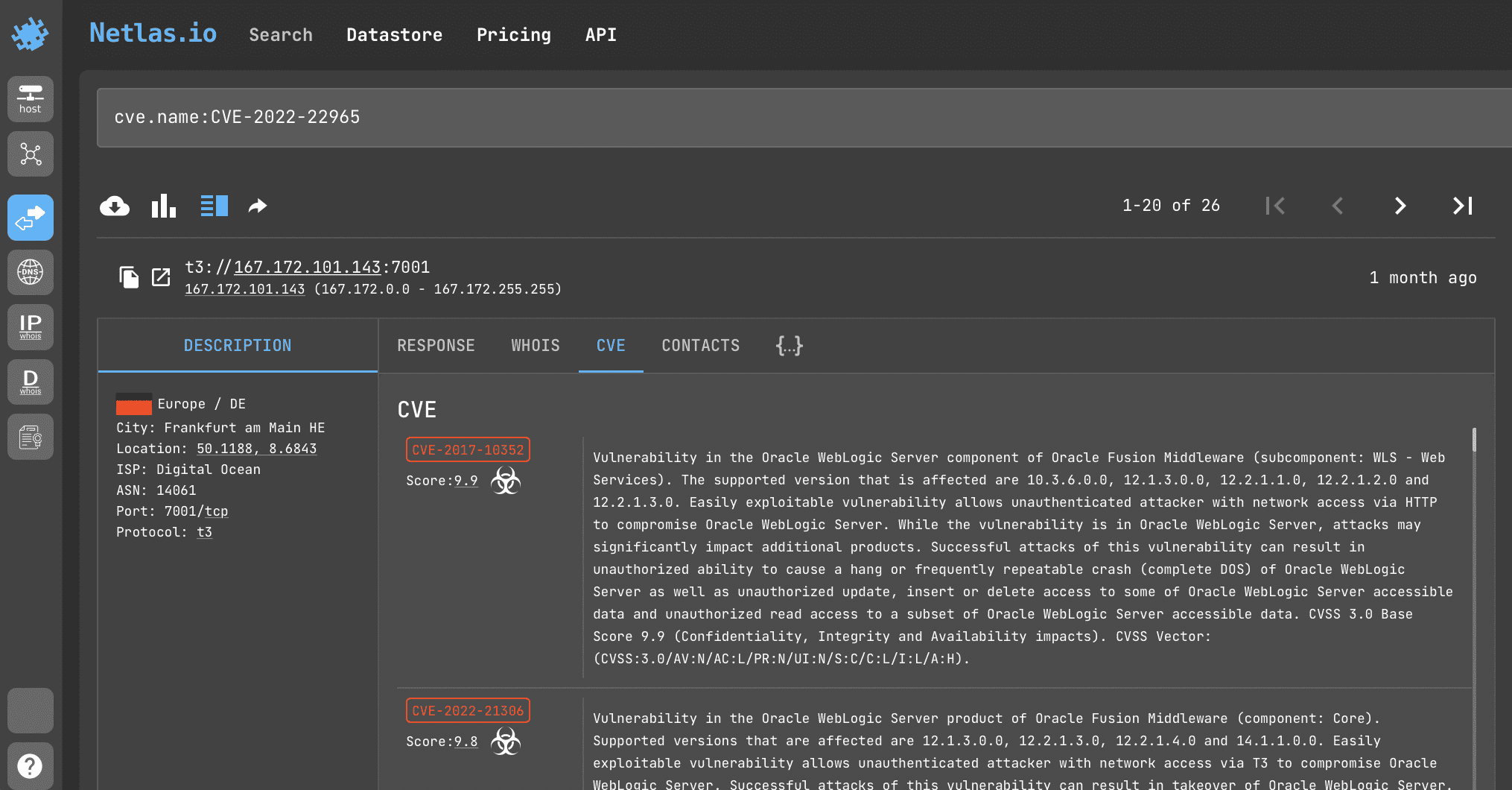
cve.name:CVE-2022-22965API request example
Netlas CLI Tools:
netlas search "cve.name:CVE-2022-22965" -f jsonCVE-2022-22965 - Spring MVC or Spring WebFlux application running on JDK 9+ may be vulnerable to remote code execution (RCE) via data binding. Details
Curl:
curl -X 'GET' \
'https://app.netlas.io/api/responses/?q=http.body%3A1%3F234%3F567%3F89%3F99%20OR%20http.body%3A12345678999%20OR%20http.body%3A1234%3F5678%3F999&source_type=include&start=0&fields=*' \
-H 'accept: application/json' \
-H 'X-API-Key: YOUR_API_KEY' jq .items[].data.uriCode example (Netlas Python Library)
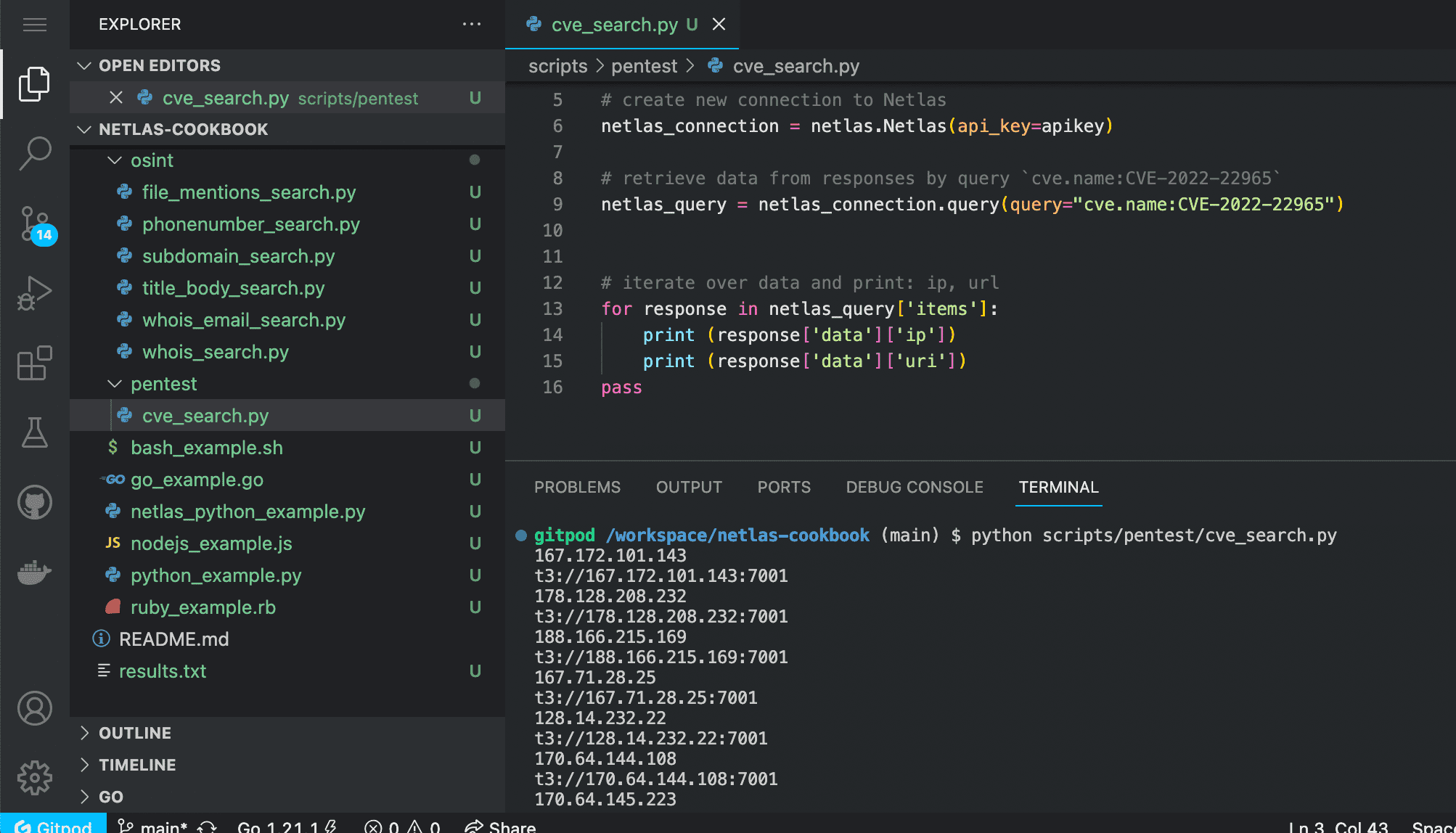
Run in command line:
python scripts/pentest/cve_search.pySource code of scripts/pentest/cve_search.py:
import netlas
apikey = "YOUR_API_KEY"
# create new connection to Netlas
netlas_connection = netlas.Netlas(api_key=apikey)
# retrieve data from responses by query `cve.name:CVE-2022-22965`
netlas_query = netlas_connection.query(query="cve.name:CVE-2022-22965")
# iterate over data and print: ip, url
for response in netlas_query['items']:
print (response['data']['ip'])
print (response['data']['uri'])Search for Sites with Vulnerabilities That Contain a Certain Word in Their Descriptions
If you don’t need to investigate servers with a specific type of vulnerability, but just want to see vulnerable servers in a specific group (such as Oracle WebLogic Server or WordPress sites), you can search for them using keywords and the cve.description: filter.
To filter out sites that have exploits published for vulnerabilities, use cve.has_exploit:true.
Search query example
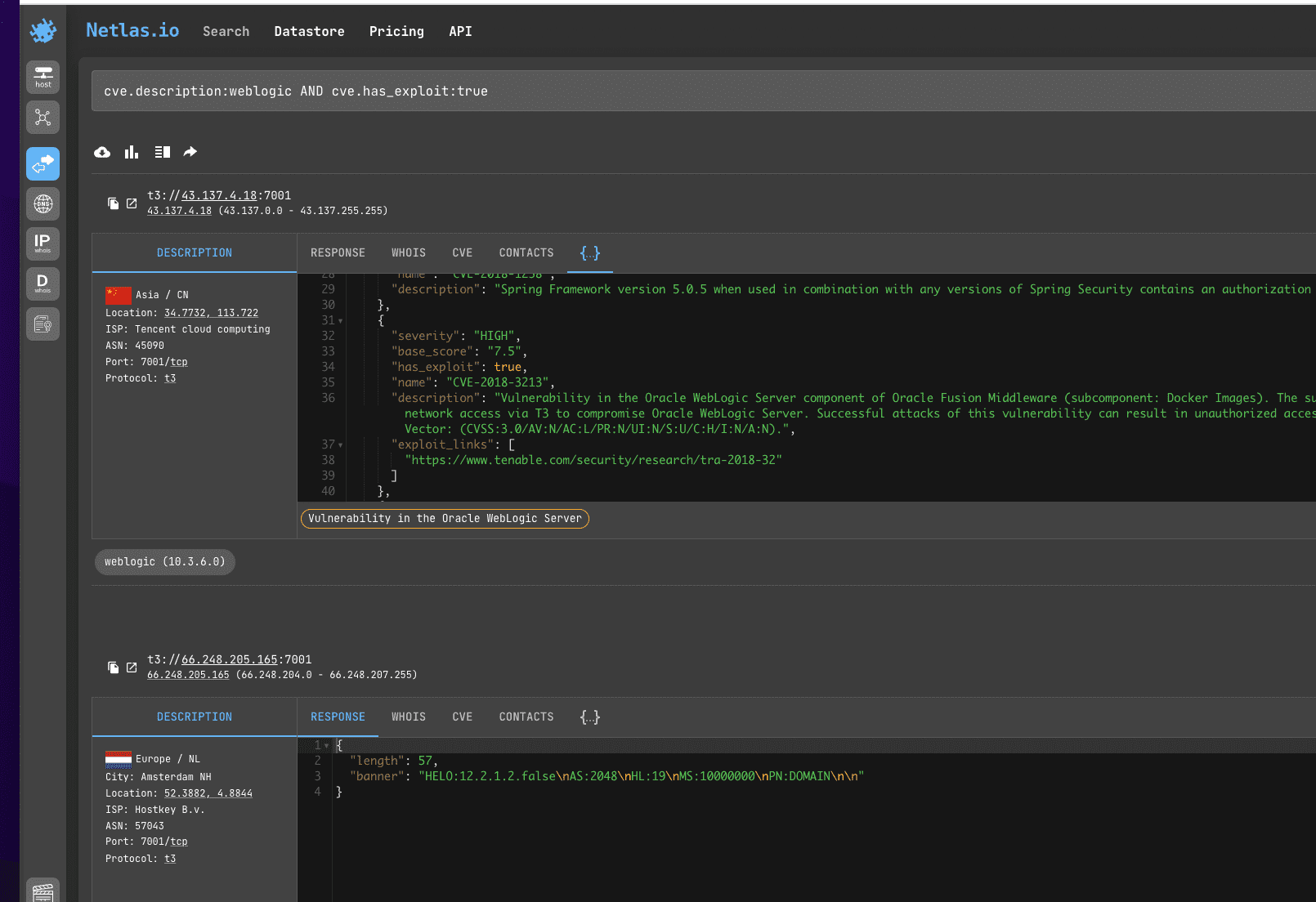
cve.description:weblogic AND cve.has_exploit:trueAPI request example
Netlas CLI Tools:
netlas search "cve.description:weblogic AND cve.has_exploit:true" -f jsonCurl:
curl -X 'GET' \
'https://app.netlas.io/api/responses/?q=cve.description%3Aweblogic%20AND%20cve.has_exploit%3Atrue&source_type=include&start=0&fields=*' \
-H 'accept: application/json' \
-H 'X-API-Key: YOUR_API_KEY | jq .items[].data.uriCode example (Netlas Python Library)
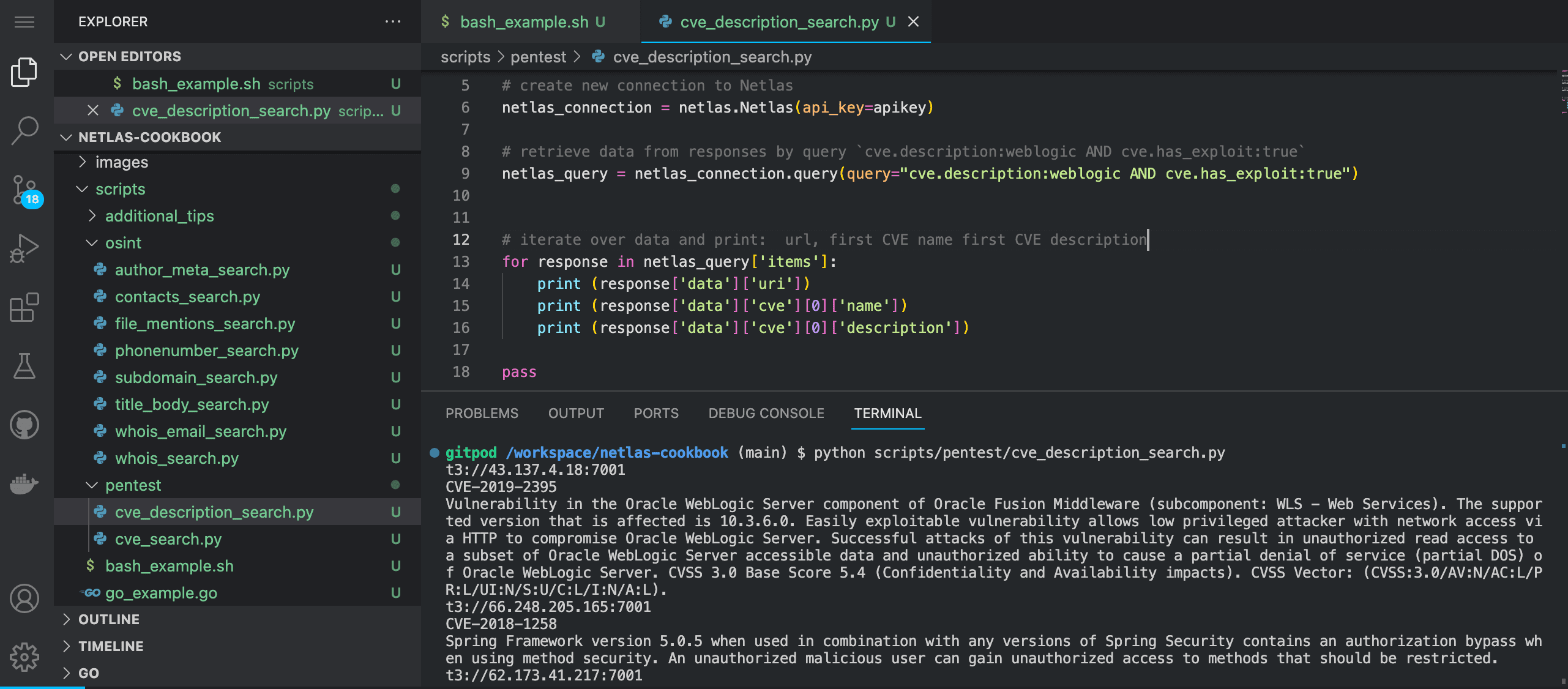
Run in command line:
python scripts/pentest/cve_description_search.pySource code of scripts/pentest/cve_description_search.py:
import netlas
apikey = "YOUR_API_KEY"
# create new connection to Netlas
netlas_connection = netlas.Netlas(api_key=apikey)
# retrieve data from responses by query `cve.description:weblogic AND cve.has_exploit:true`
netlas_query = netlas_connection.query(query="cve.description:weblogic AND cve.has_exploit:true")
# iterate over data and print: url, first CVE name first CVE description
for response in netlas_query['items']:
print (response['data']['uri'])
print (response['data']['cve'][0]['name'])
print (response['data']['cve'][0]['description'])Search by Server HTTP Header
This method allows you to find devices manufactured by a specific company.
Search query example
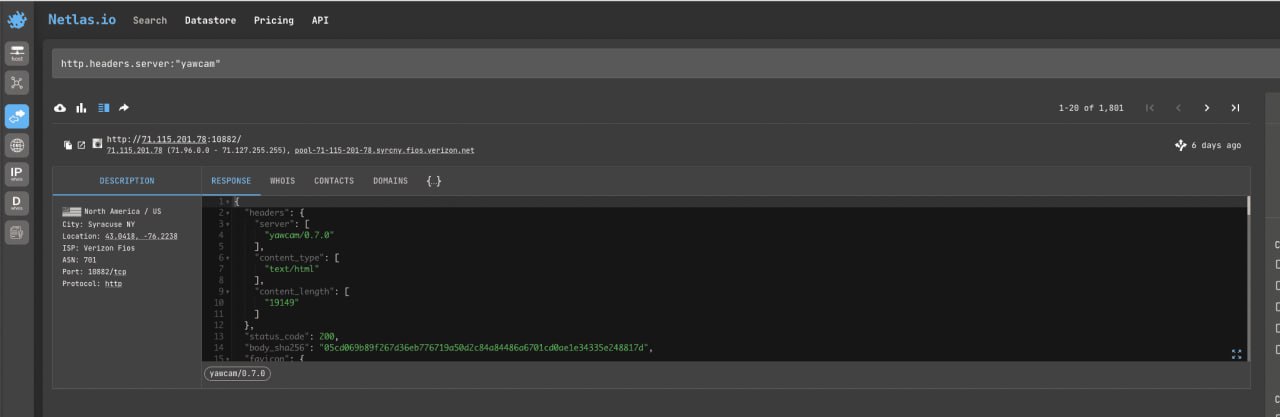
http.headers.server:"yawcam"Search YawCam web cams.
API request example
Netlas CLI Tools:
netlas search 'http.headers.server:"yawcam"' -f jsonNote that when double quotes are used in queries, the query itself is written inside single quotes.
Curl:
curl -X 'GET' \
'https://app.netlas.io/api/responses/?q=http.headers.server%3A%22yawcam%22&source_type=include&start=0&fields=*' \
-H 'accept: application/json' \
-H 'X-API-Key: YOUR_API_KEY' | jq .items[].data.uriCode example (Netlas Python Library)
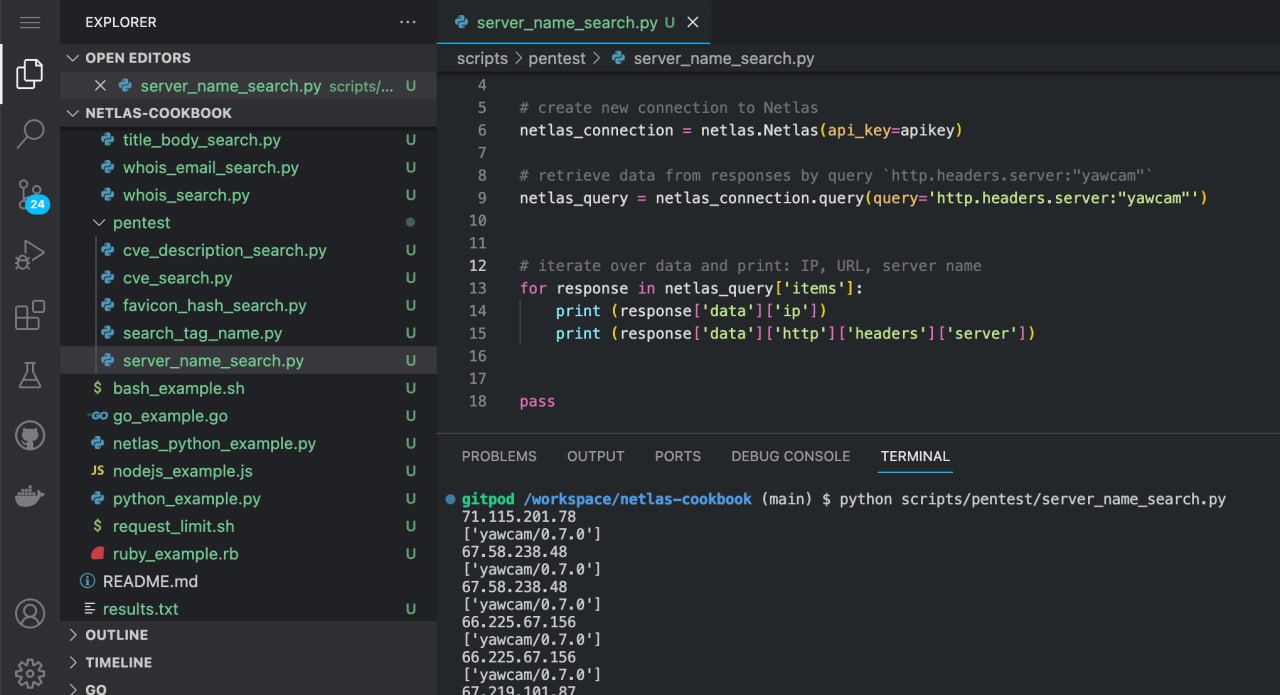
Run in command line:
python scripts/pentest/server_name_search.pySource code of scripts/pentest/server_name_search.py:
import netlas
apikey = "YOUR_API_KEY"
# create new connection to Netlas
netlas_connection = netlas.Netlas(api_key=apikey)
# retrieve data from responses by query `http.headers.server:"yawcam"`
netlas_query = netlas_connection.query(query='http.headers.server:"yawcam"')
# iterate over data and print: IP, URL, server name
for response in netlas_query['items']:
print (response['data']['ip'])
print (response['data']['http']['headers']['server'])Default Logins and Passwords
One practical application of searching by software name in server headers is to search for devices from a particular vendor. This may be necessary both when searching for devices with specific vulnerabilities and for devices with standard logins and passwords.
Standard logins and passwords for different device models can be found in special lists. For example:
- Default Router Login Password For Top Router Models (2023 List)
- Default Username – Password – IP Address for Security Cameras
- The Default Passwords of Nearly Every IP Camera
- List of default passwords from Datarecovery
Remember that using standard logins and passwords to log into other people’s systems violates ethics rules and may be illegal in your country.
Search for Vulnerable Servers by Favicon Hash
One way to find web servers exposed to a particular vulnerability is to search for favicon ico of a particular web server software.
Search query example
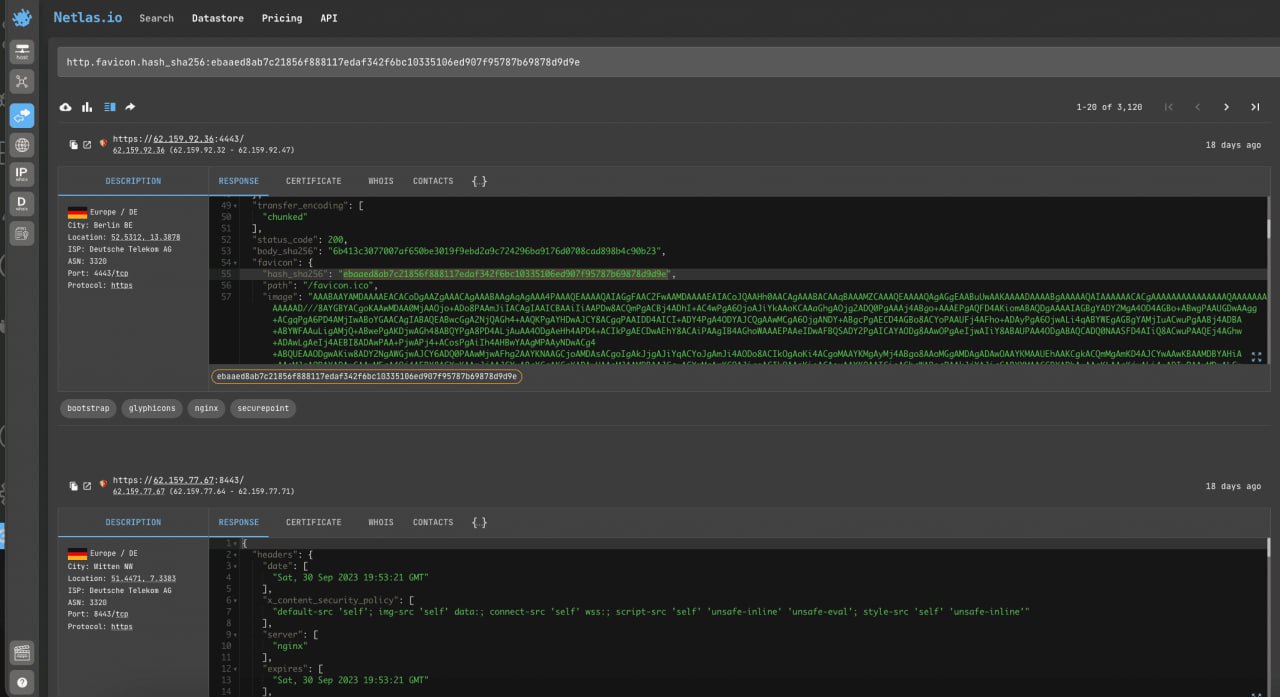
http.favicon.hash_sha256:ebaaed8ab7c21856f888117edaf342f6bc10335106ed907f95787b69878d9d9eThis query search SecurePoint favicon (CVE-2023-22620).
API request example
Netlas CLI Tools:
netlas search "http.favicon.hash_sha256:ebaaed8ab7c21856f888117edaf342f6bc10335106ed907f95787b69878d9d9e" -f jsonCurl:
curl -X 'GET' \
'https://app.netlas.io/api/responses/?q=http.favicon.hash_sha256%3Aebaaed8ab7c21856f888117edaf342f6bc10335106ed907f95787b69878d9d9e&source_type=include&start=0&fields=*' \
-H 'accept: application/json' \
-H 'X-API-Key: YOUR_API_KEY' | jq .items[].data.uriCode example (Netlas Python Library)
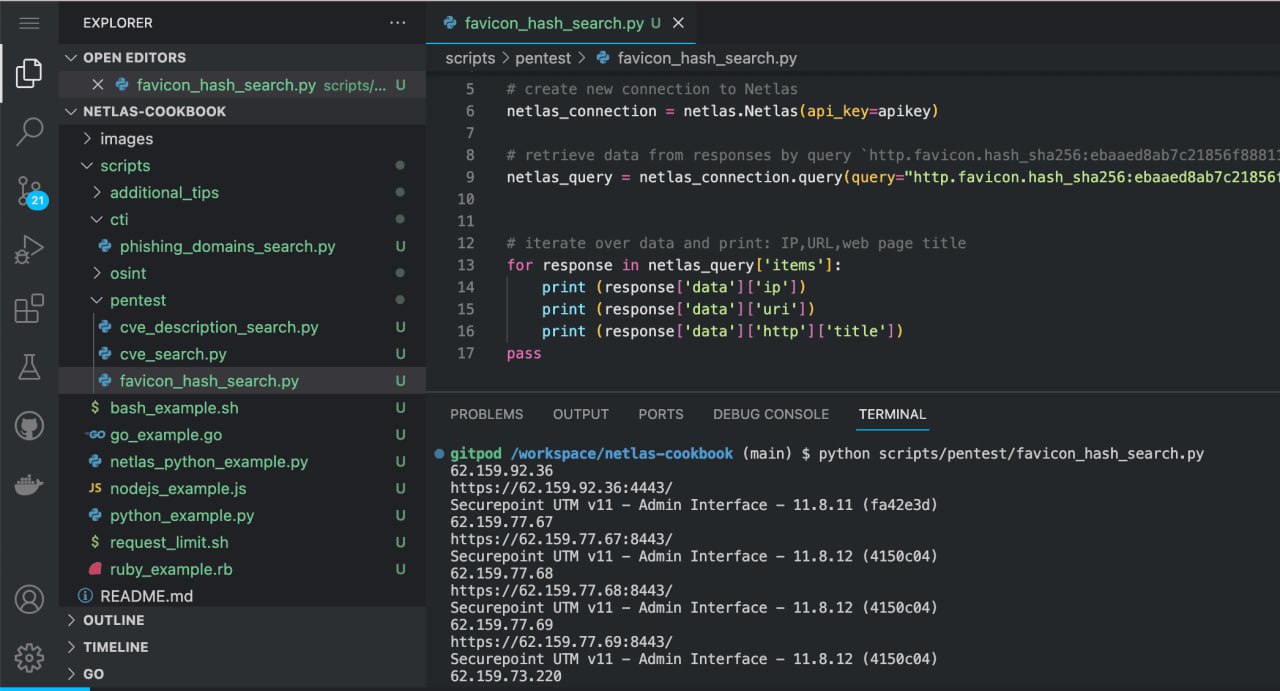
Run in command line:
python scripts/pentest/favicon_hash_search.pySource code of scripts/pentest/favicon_hash_search.py:
import netlas
apikey = "YOUR_API_KEY"
# create new connection to Netlas
netlas_connection = netlas.Netlas(api_key=apikey)
# retrieve data from responses by query `http.favicon.hash_sha256:ebaaed8ab7c21856f888117edaf342f6bc10335106ed907f95787b69878d9d9e`
netlas_query = netlas_connection.query(query="http.favicon.hash_sha256:ebaaed8ab7c21856f888117edaf342f6bc10335106ed907f95787b69878d9d9e")
# iterate over data and print: IP,URL,web page title
for response in netlas_query['items']:
print (response['data']['ip'])
print (response['data']['uri'])
print (response['data']['http']['title'])Search for Vulnerable Servers by Tag Name
To simplify searching across servers running different software, Netlas automatically tags search results with specific tags.
Examples of tags:
- Blogs - medium, wordpress, tumblr
- CDN - google_cloud, cloudflare, keycdn
- CMS - ucoz, joomla, pyrocms
- Ecommerce - opencart, magento, wix
You can search by tags using the “tag.name:” filter. You can also search by tag category using the “tag.category:” filter. A list of all available tags and categories is displayed when you click on the icon to the right of the search query entry box on the Netlas homepage.
Note: Not all pricing plans support the use of tags.
Search query example
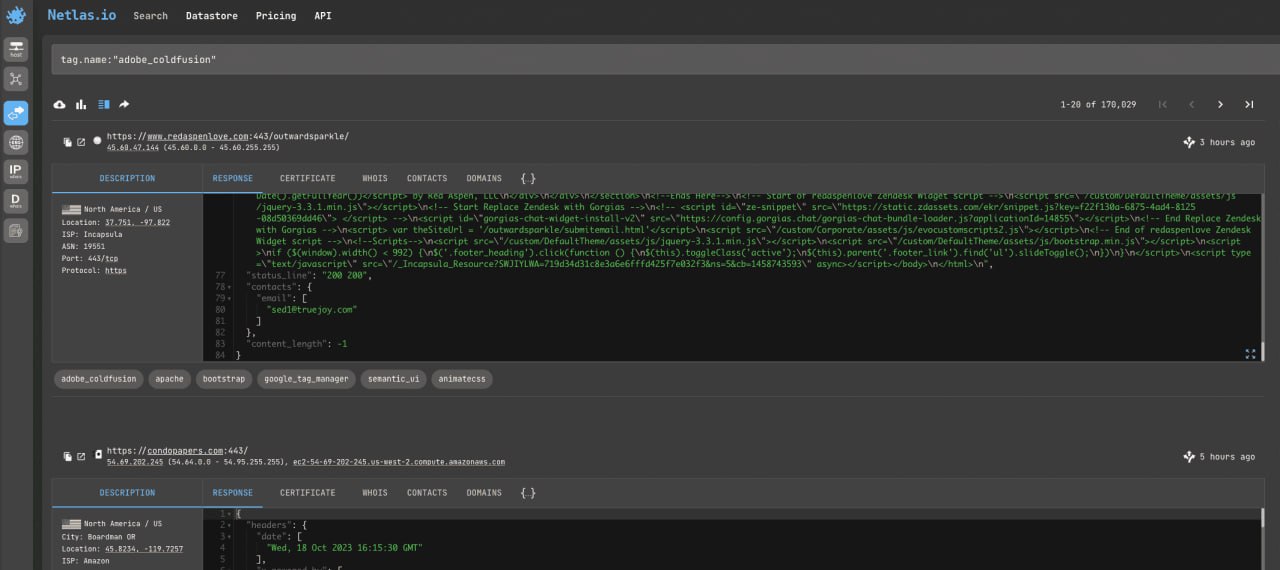
tag.name:"adobe_coldfusion"This query search Adobe ColdFusion (CVE-2023-26359).
API request example
Netlas CLI Tools:
netlas search 'tag.name:"adobe_coldfusion"' -f jsonNote that when double quotes are used in queries, the query itself is written inside single quotes.
Curl:
curl -X 'GET' \
'https://app.netlas.io/api/responses/?q=tag.name%3A%22adobe_coldfusion%22&source_type=include&start=0&fields=*' \
-H 'accept: application/json' \
-H 'X-API-Key: YOUR_API_KEY' | jq .items[].data.uriCode example (Netlas Python Library)
Run in command line:
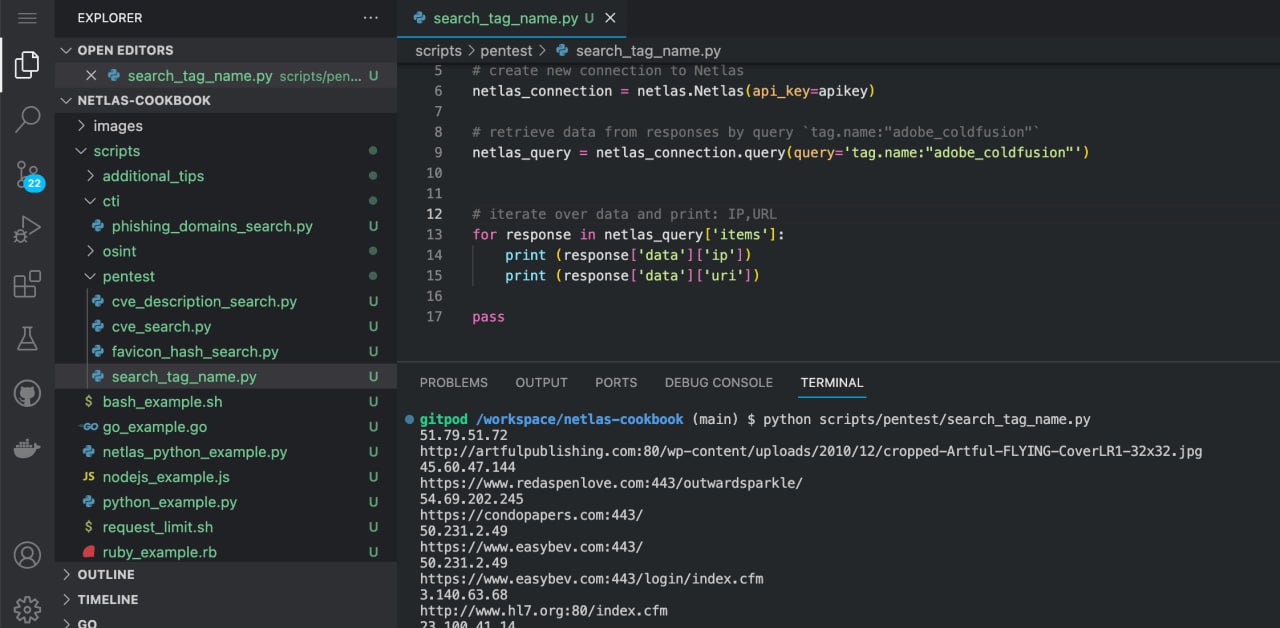
python scripts/pentest/search_tag_name.pySource code of scripts/pentest/search_tag_name.py:
import netlas
apikey = "YOUR_API_KEY"
# create new connection to Netlas
netlas_connection = netlas.Netlas(api_key=apikey)
# retrieve data from responses by query `tag.name:"adobe_coldfusion"`
netlas_query = netlas_connection.query(query='tag.name:"adobe_coldfusion"')
# iterate over data and print: IP,URL
for response in netlas_query['items']:
print (response['data']['ip'])
print (response['data']['uri'])Search for Vulnerable Servers and Devices Near You (or Any Other Location)
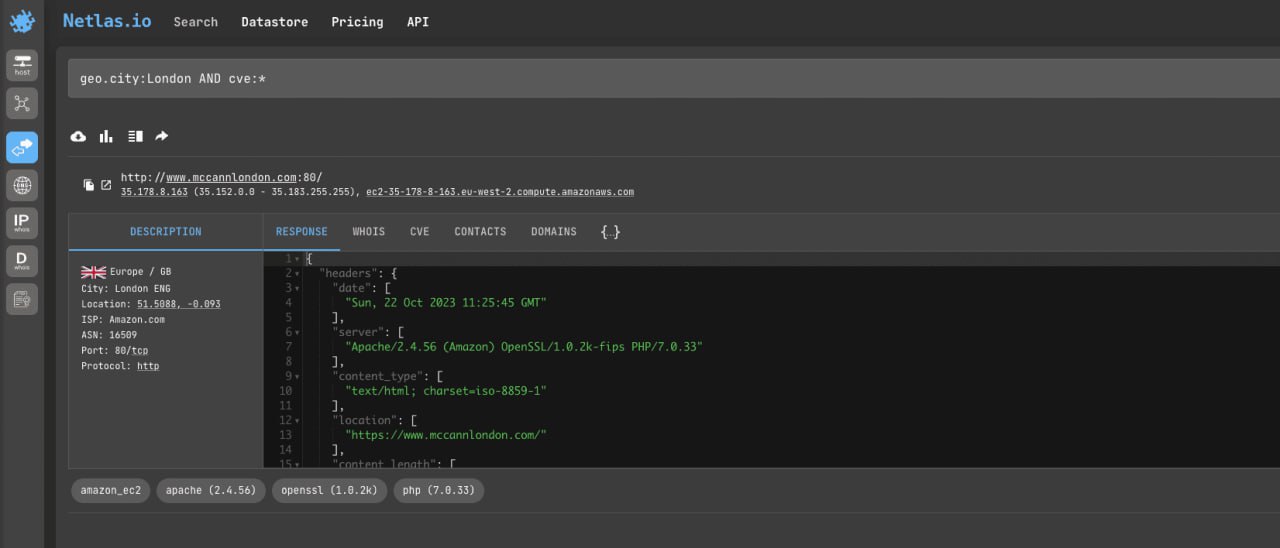
Do you want to know how many vulnerable sites and devices are around you? Simply search for all IP addresses that have the CVE field populated in a specific geolocation.
geo.city:London AND cve:*You can also use other geolocation filters.
geo.continentgeo.countrygeo.location
API request example
Netlas CLI Tools:
geo.city:London AND cve:*Curl:
curl -X 'GET' \
'https://app.netlas.io/api/responses/?q=geo.city%3ALondon%20AND%20cve%3A*&source_type=include&start=0&fields=*' \
-H 'accept: application/json' \
-H 'X-API-Key: 'YOUR_API_KEY' | jq .items[].data.domainCode example (Netlas Python Library)
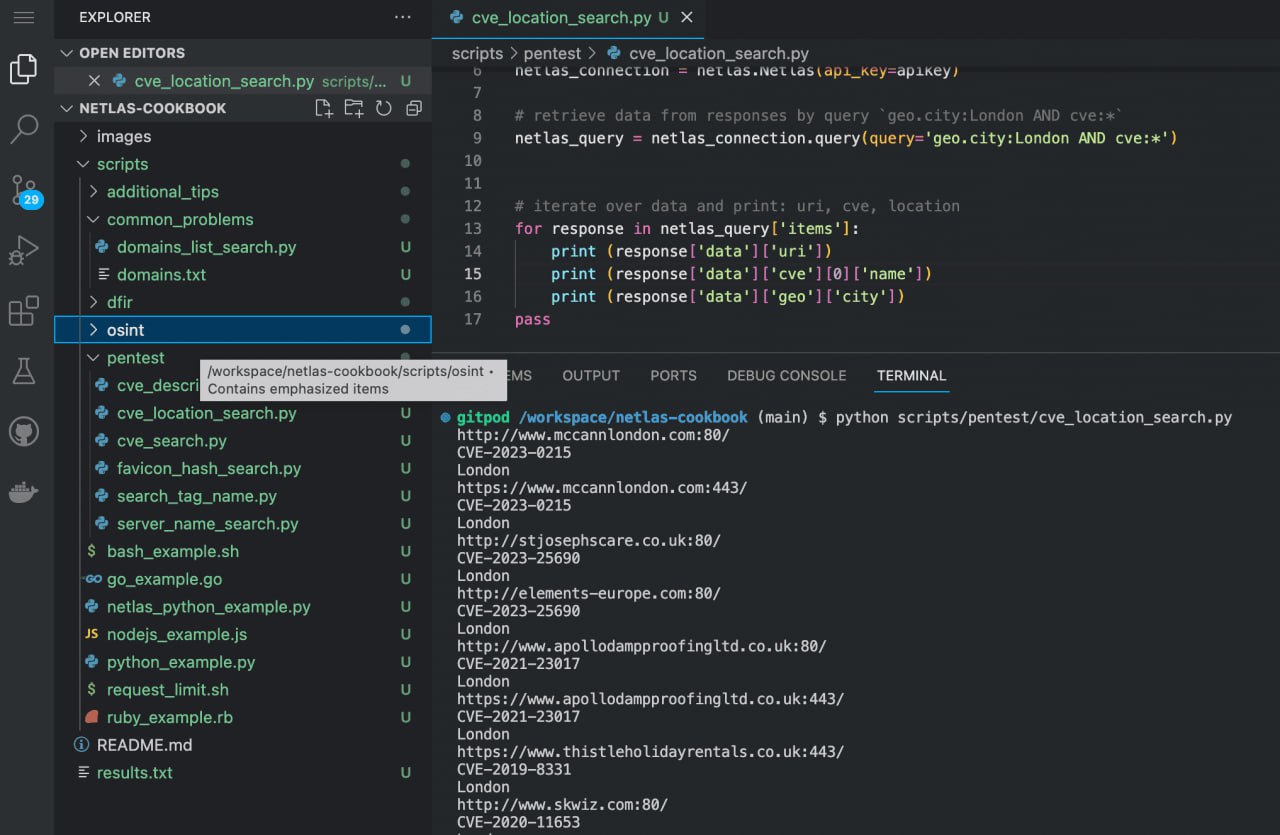
Run in command line:
python scripts/pentest/cve_location_search.pySource code of scripts/pentest/cve_location_search.py:
import netlas
apikey = "YOUR_API_KEY"
# create new connection to Netlas
netlas_connection = netlas.Netlas(api_key=apikey)
# retrieve data from responses by query `geo.city:London AND cve:*`
netlas_query = netlas_connection.query(query='geo.city:London AND cve:*')
# iterate over data and print: uri, cve name, location
for response in netlas_query['items']:
print (response['data']['uri'])
print (response['data']['cve'][0]['name'])
print (response['data']['geo']['city'])Search for Login/Admin Panels
Many sites and servers have login and password web pages that can be used to gain access to full control of the site or server (through the use of default passwords, bruteforce, or vulnerability exploitation).
You can find them by using the uri: or/and http.title filter:
uri:*login.php*
uri:*login.aspx*
uri:*user* http.title:login
uri:*admin* http.title:login
http.title:admin http.title:panelThere are so many combinations. To find only panels of vulnerable servers use filter cve:*.
Also, don’t forget that you can filter servers by installed software using tags. For example:
tag.1c_bitrix:*
tag.Cisco:
tag.amazon_s3:*
tag.drupal:*
tag.wordpress:*Search for Vulnerable Database Admin Panels
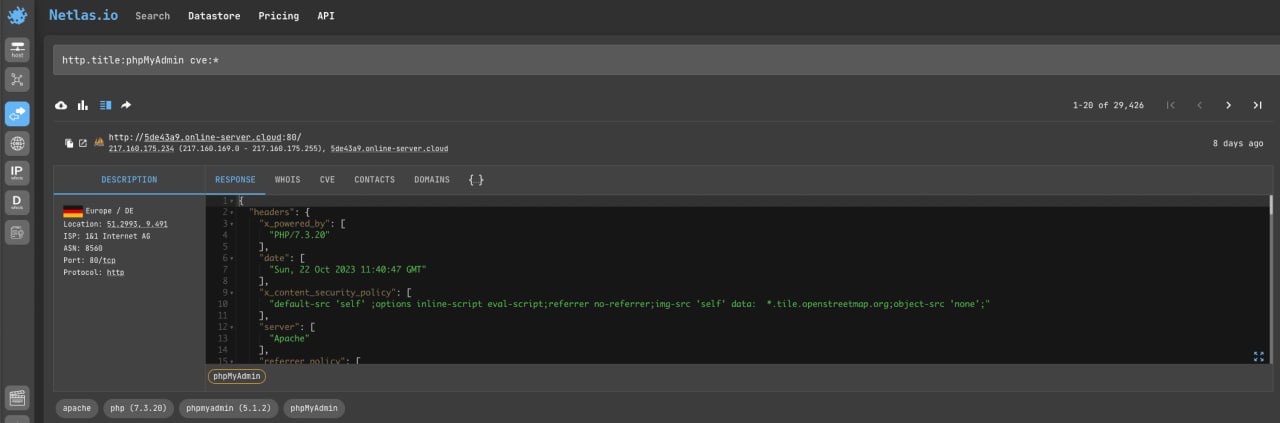
Let’s try to search vulnerable phpMyAdmin admin panel (the one of most popular software for administering MySQL databases):
http.title:phpMyAdmin cve:*And here are some examples for other popular database administration tools:
http.title:adminer http.title:login cve:*http.title:(phpPgAdmin OR pgadmin) cve:*You can also search for servers that have installed software for different databases by using the tags or special filters:
tag.adminer:*
tag.phpMyAdmin:*
tag.elastic:*
mongodb:*
mssql:*
mysql:*
django:*Searching for admin panels for servers found in this way may not be the easiest thing to do, as site administrators often change standard links to more secure ones.
Search for Sites Vulnerable to SQL Injection
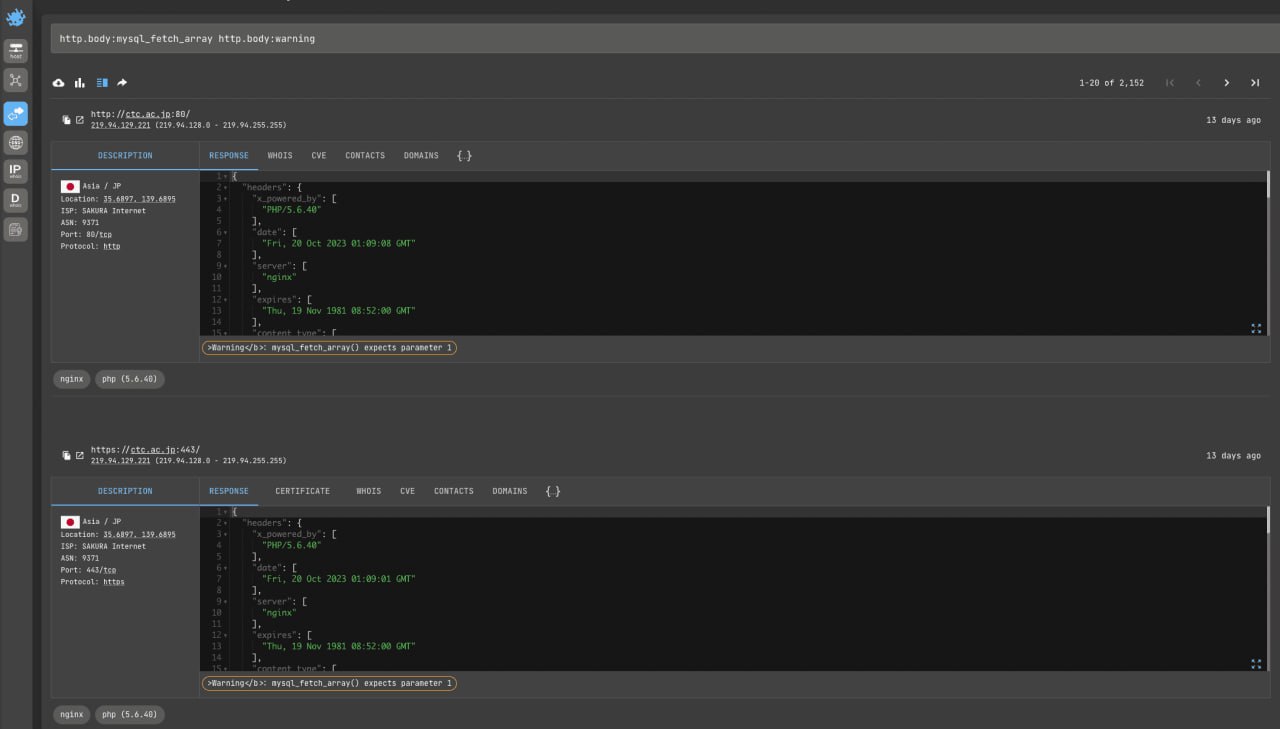
SQL injection is a type of vulnerability that allows database queries to be made by manipulating URL parameters (this can be possible due to misconfigurations and poor quality code).
One of the oldest techniques for finding pages potentially vulnerable to SQL Injection is to search for pages that have enabled error message display in MySQl queries using Google Dorks.
A similar search can be done in Netlas:
http.body:mysql_fetch_array http.body:warningFew other examples:
http.body:mysql_num_rows http.body:warning
http.body:mysql_connect http.body:denied
http.body:mysql_query http.body:warning
http.body:pg_connect http.body:fatalAPI request example
Netlas CLI Tools:
netlas search "http.body:mysql_fetch_array http.body:warning" -f jsonCurl:
curl -X 'GET' \
'https://app.netlas.io/api/responses/?q=http.body%3Amysql_fetch_array%20http.body%3Awarning&source_type=include&start=0&fields=*' \
-H 'accept: application/json' \
-H 'X-API-Key: YOUR_API_KEY' jq .items[].data.uriCode example (Netlas Python Library)
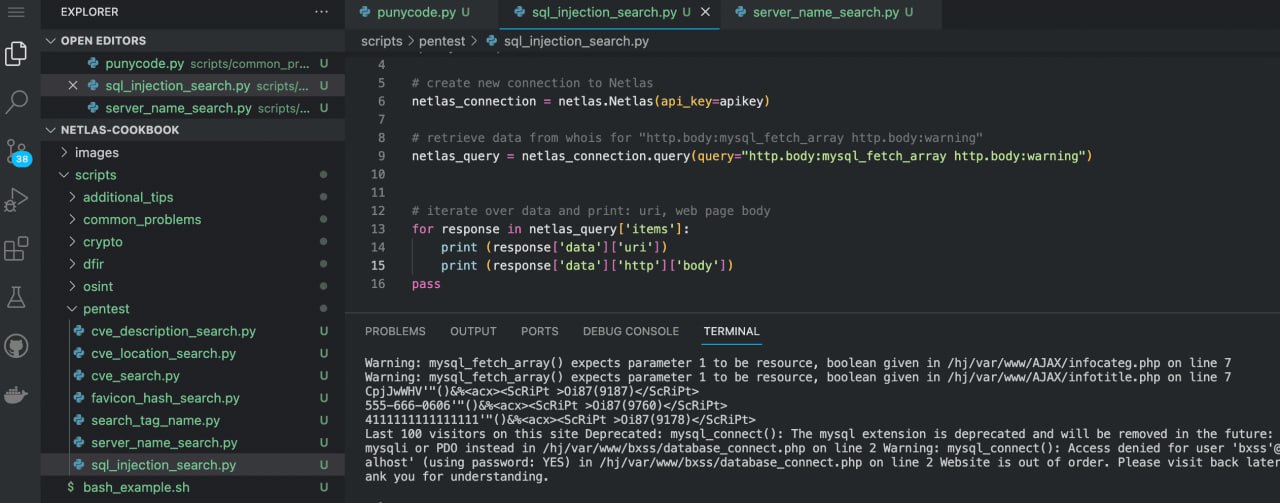
Run in command line:
python scripts/pentest/sql_injection_search.pySource code of scripts/pentest/sql_injection_search.py:
import netlas
apikey = "YOUR_API_KEY"
# create new connection to Netlas
netlas_connection = netlas.Netlas(api_key=apikey)
# search in Netlas "http.body:mysql_fetch_array http.body:warning"
netlas_query = netlas_connection.query(query="http.body:mysql_fetch_array http.body:warning")
# iterate over data and print: uri, web page body
for response in netlas_query['items']:
print (response['data']['uri'])
print (response['data']['http']['body']) You may also use the following filters to search for vulnerable MySQL servers:
mysql.error_codemysql.error_idmysql.error_message
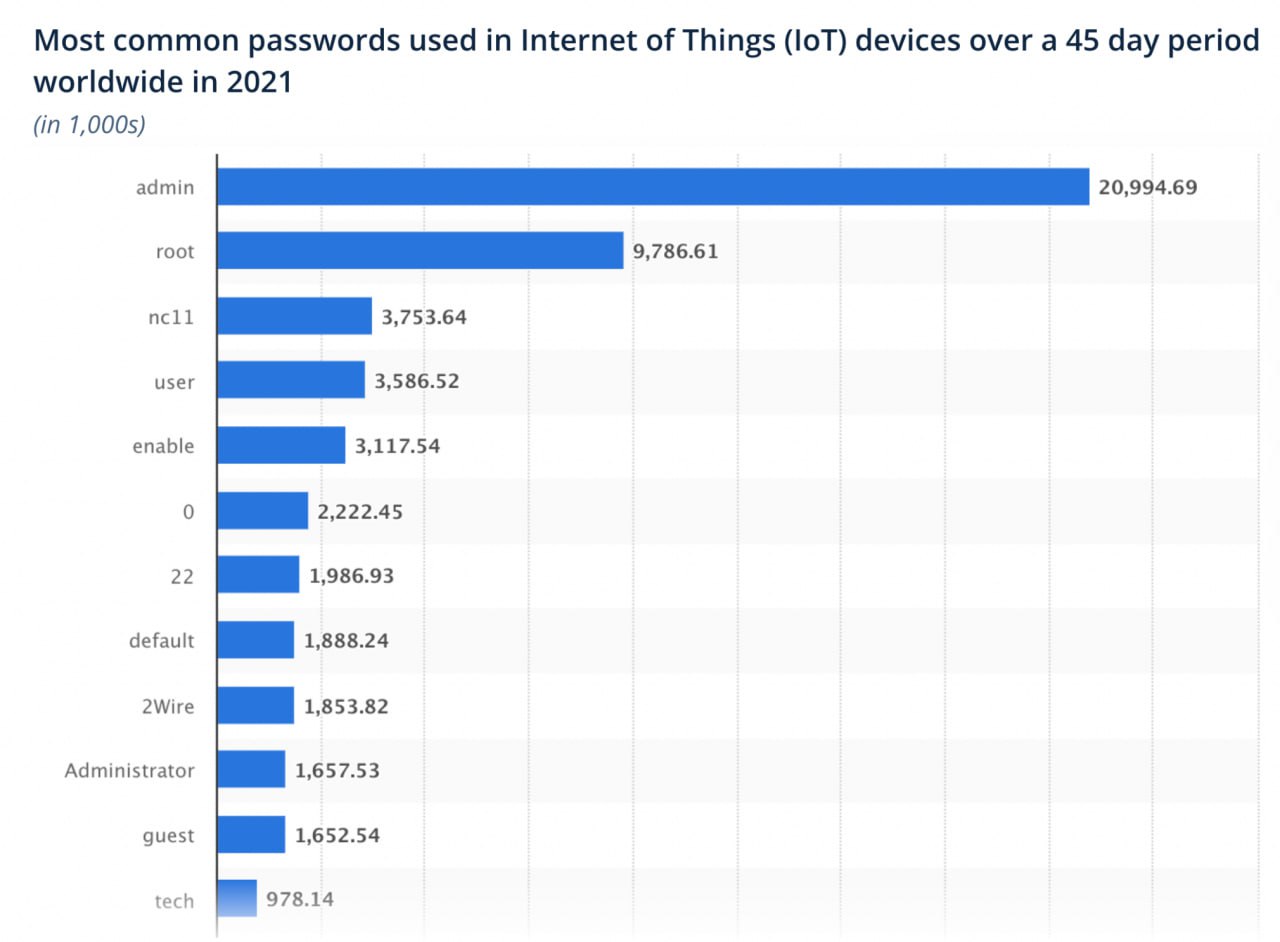
IoT Search: 9 Basic Ways
Netlas searches not only websites and servers, but all devices connected to the Internet: smart home appliances, surveillance cameras, printers, routers, traffic lights, medical equipment, and more.
There are four main ways to find these devices.
Search by Title
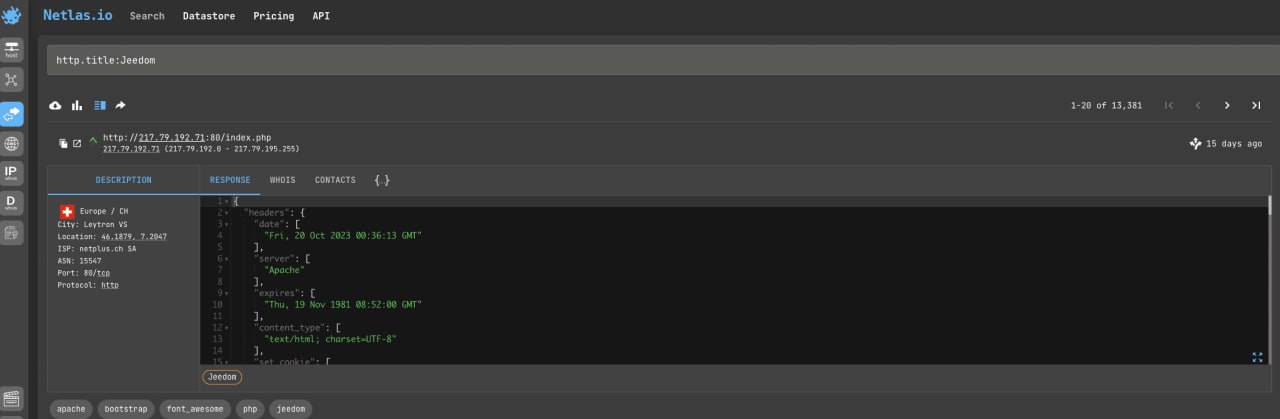
The easiest way is to simply search for the vendor’s name or device type in the http title of the answer.
Try to search Jeedom home automation devices:
http.title:JeedomOr Avigilon webcams:
http.title:"Avigilon"There are two disadvantages to this method. The first is the large number of inappropriate results (just websites with relevant words in the title). But when using quotation marks and additional search filters like port:, there are fewer of them.
The second is that a lot of IoT devices don’t have any information in the http title by which they can be identified. So, other search filters can be useful too.
Search Inside Body
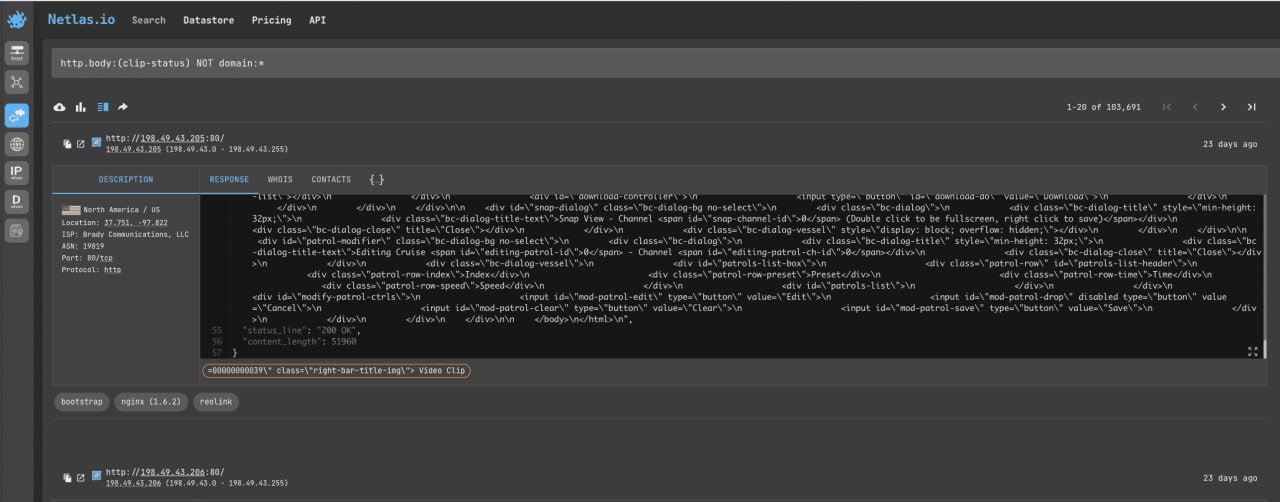
Similarly, you can try searching for keywords in the body of the http response. To filter out at least some of the common websites, use the NOT domain:* filter. Let’s try to search Reolink cameras:
http.body:(clip-status) NOT domain:*The example isn’t quite right, so these cameras can be found using tags (more on that below).
Search by Port Number
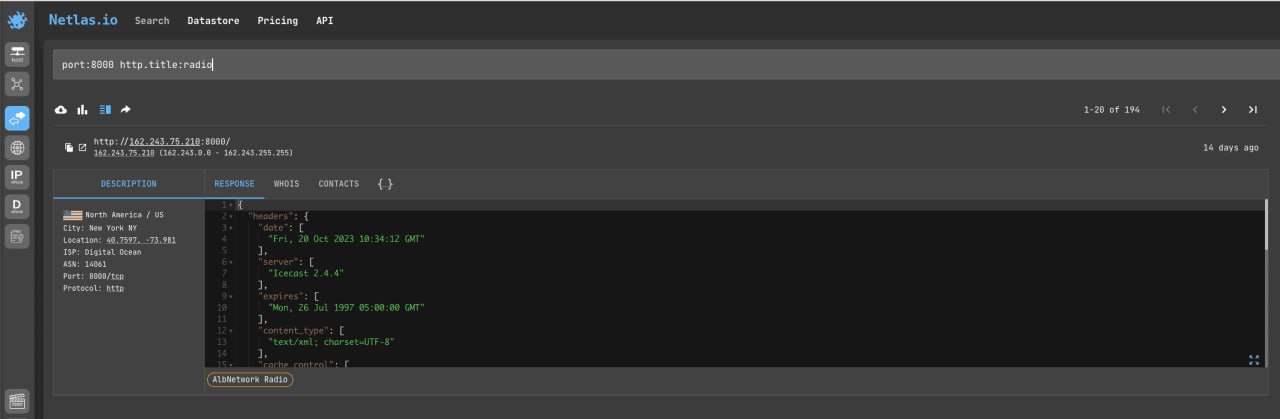
Different IoT devices use different ports for communication. And by the open port number, you can hypothetically assume that the IP address belongs to a certain type of device (often the assumption is correct, but there can be inaccuracies and coincidences).
Try to search Internet radio (port 8000):
port:8000 http.title:radioOr all devices with opened port 7547 (it’s used to remotely manage routers via CWMP):
port:7547Search by Banner
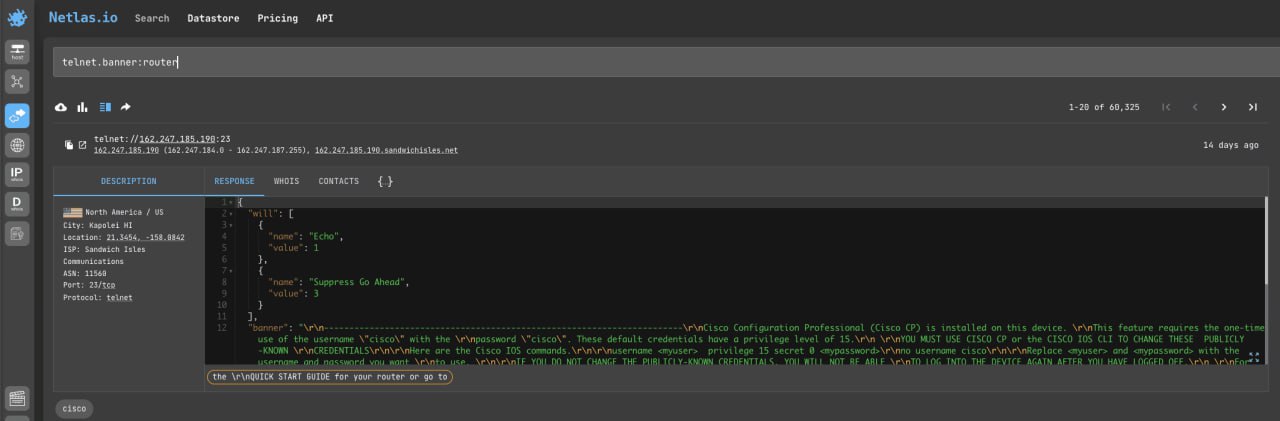
Let’s look for routers that use the Telnet protocol (you could also filter them with port:23):
telnet.banner:routerOr search banners for all protocols:
\*.banner:routerSearch by Favicon
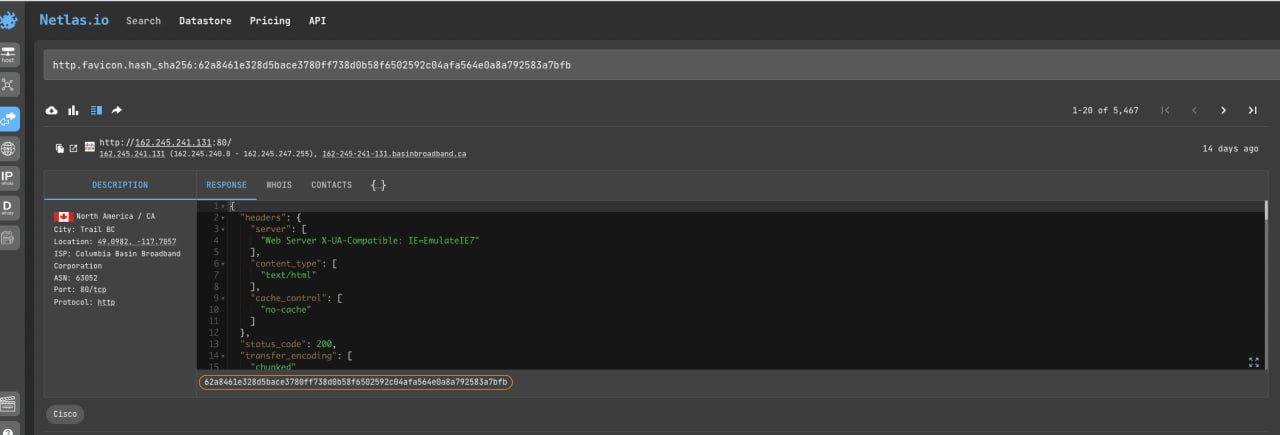
One of the easiest ways to find devices that have certain software installed is to search by favicon. Let’s try to find where different Cisco products are used:
http.favicon.hash_sha256:62a8461e328d5bace3780ff738d0b58f6502592c04afa564e0a8a792583a7bfbThere are three main ways to search by favicon in Netlas:
- Click on the icon to the left of the search result.
- Click on the favicon search button to the right of the search bar and paste the favicon link into the pop-up window.
- Click on the favicon search button to the right of the search bar and upload the favicon file.
Search by Server Headers
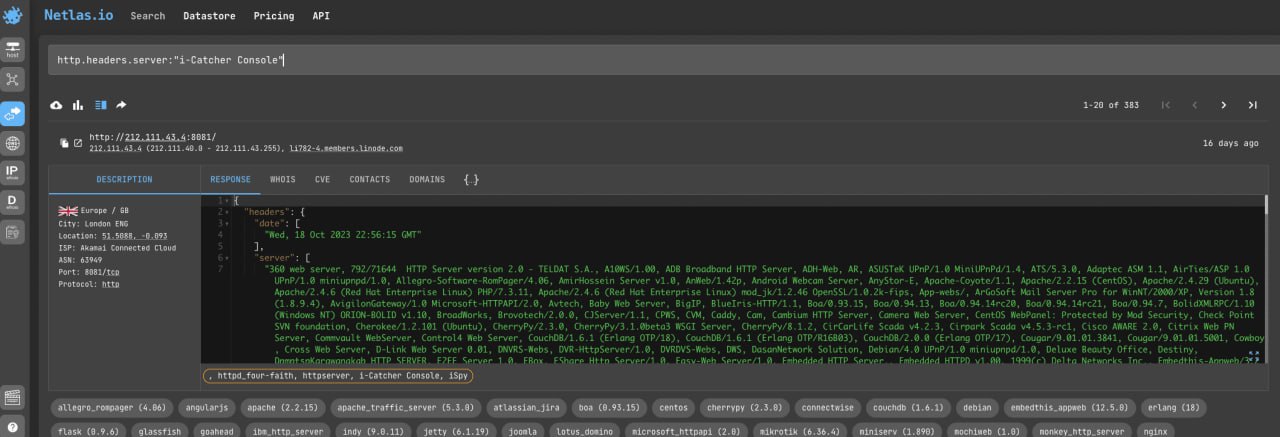
Sometimes it happens that there is no identifying dev information in the http title, but it may be in other headers. For example, in http.server.header:
http.headers.server:"i-Catcher Console"Netlas supports searching across several dozen header types. Try different variants.
Search by Cookies
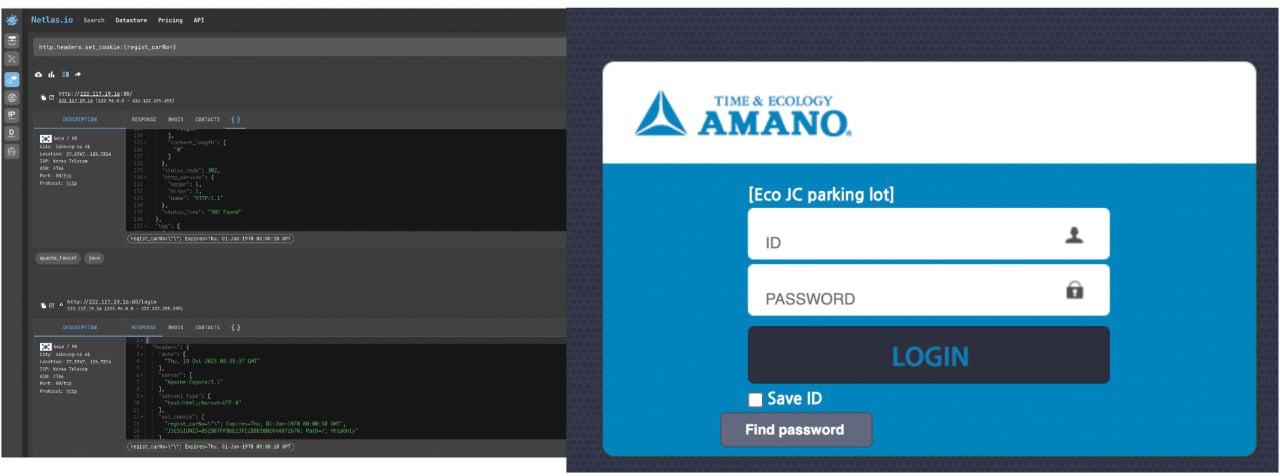
Search Eco JS Parking lots:
http.headers.set_cookie:(regist_carNo=)Search by Tag
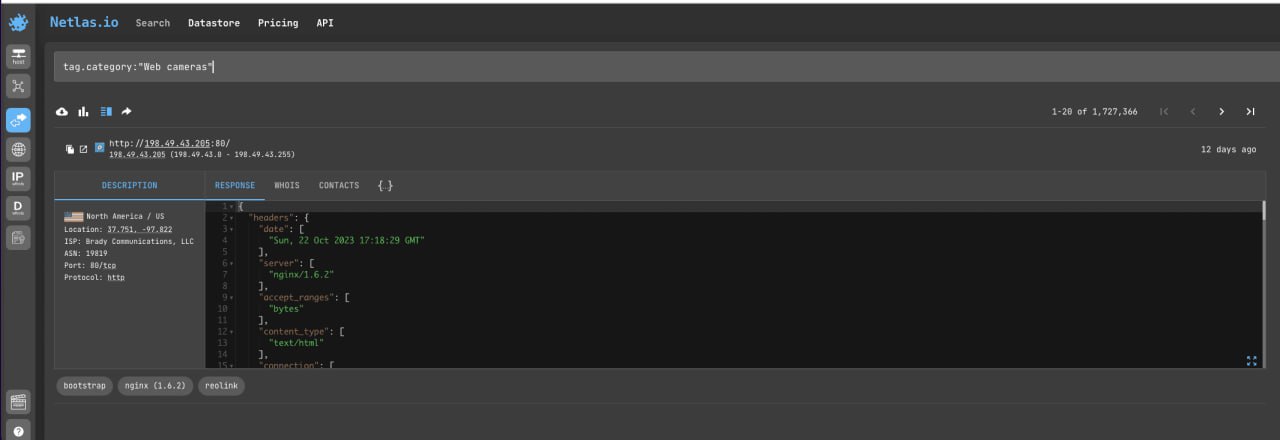
This method may require a paid subscription. See the pricing
You can also try searching for devices by tags (categories).
tag.category:"IoT"
tag.category:"Web cameras"Just remember that tags are assigned automatically and some suitable devices may not be included in the corresponding category.
Additional Search Filters
It’s can search for IoT devices located in specific geolocations:
geo.citygeo.countrygeo.continent
Filter devices by IP address range:
ip:[162.245.241.131 TO 162.245.241.133]Or devices with “fresh” vulnerabilities:
cve.name:*2023*More examples of queries to search for IoT devices can be found here:
Using Netlas.io for Darknet Research
One of the main advantages of Netlas is that you can use it to search for things that are not indexed by Google. This is what can be conventionally called DeepWeb. For example, FTP servers or Telnet servers:
ftp.banner:*telnet.banner:*But unfortunately Netlas does not index the Darknet (.onion, .i2p etc) as it only scans global IP addresses. But it can still be used to explore alternative network infrastructure and find links to .onion sites.
Tor Exit Nodes Search
Tor exit node is the point whrerer web traffic leaves the Tor network and is forwarded to destination. An up-to-date list of IP addresses of active Tor entry nodes is always available on the TorProject website:
Tor Project’s list of exit nodes
Let’s see how you can collect information about all active Tor exit nodes at once using Netlas. This example will be useful for all other tasks for which you need to collect information about a list of domains or IP addresses.
Run scripts/darknet/tor_nodes.py:
python scripts/darknet/tor_nodes.py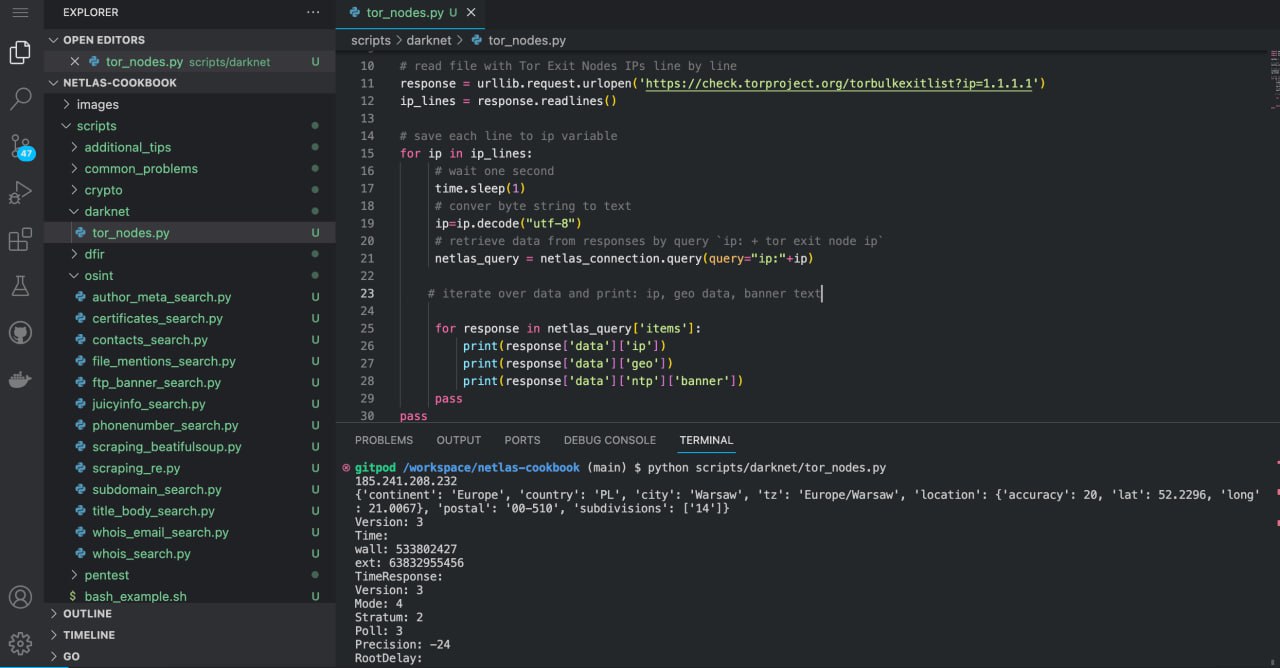
Source code of scripts/darknet/tor_nodes.py:
import netlas
import urllib
import time
apikey = 'YOUR_API_KEY'
# create new connection to Netlas
netlas_connection = netlas.Netlas(api_key=apikey)
# read file with Tor Exit Nodes IPs line by line
response = urllib.request.urlopen('https://check.torproject.org/torbulkexitlist?ip=1.1.1.1')
ip_lines = response.readlines()
# save each line to ip variable
for ip in ip_lines:
# wait one second
time.sleep(1)
# conver byte string to text
ip=ip.decode("utf-8")
# retrieve data from responses by query `ip: + tor exit node ip`
netlas_query = netlas_connection.query(query="ip:"+ip)
# iterate over data and print: ip, geo data, banner text
for response in netlas_query['items']:
print(response['data']['ip'])
print(response['data']['geo'])
print(response['data']['ntp']['banner'])
pass
passUsing time package and sleep method is good only for simple examples. Best solutions is using rate limit package.
Collecting Links to .onion Sites
As mentioned above, Netlas only scans global domains, so it is not possible to search for .onion domains. But you can search for references to .onion domains in the text of web pages. Here is an example of a simple python script (with regular expression) that does this:
Run scripts/darknet/onion_links.py:
python scripts/darknet/onion_links.py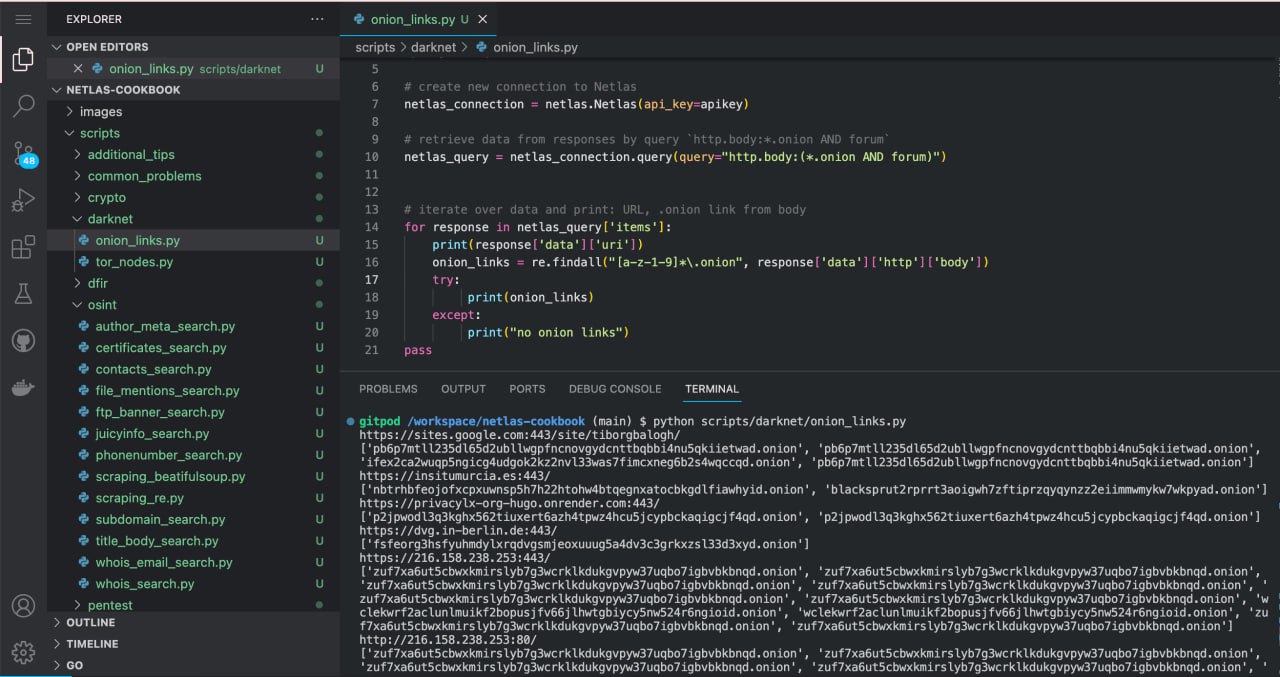
Source code of scripts/darknet/onion_links.py:
import netlas
import re
apikey = "YOUR_API_KEY"
# create new connection to Netlas
netlas_connection = netlas.Netlas(api_key=apikey)
# retrieve data from responses by query `http.body:*.onion AND forum`
netlas_query = netlas_connection.query(query="http.body:(*.onion AND forum)")
# iterate over data and print: URL, .onion link from body
for response in netlas_query['items']:
print(response['data']['uri'])
onion_links = re.findall("[a-z-1-9]*\.onion", response['data']['http']['body'])
try:
print(onion_links)
except:
print("no onion links")
passYou can collect links for other networks like I2Pin the same way:
http.body:*.i2pFiles, Backups and Logs Directories Search
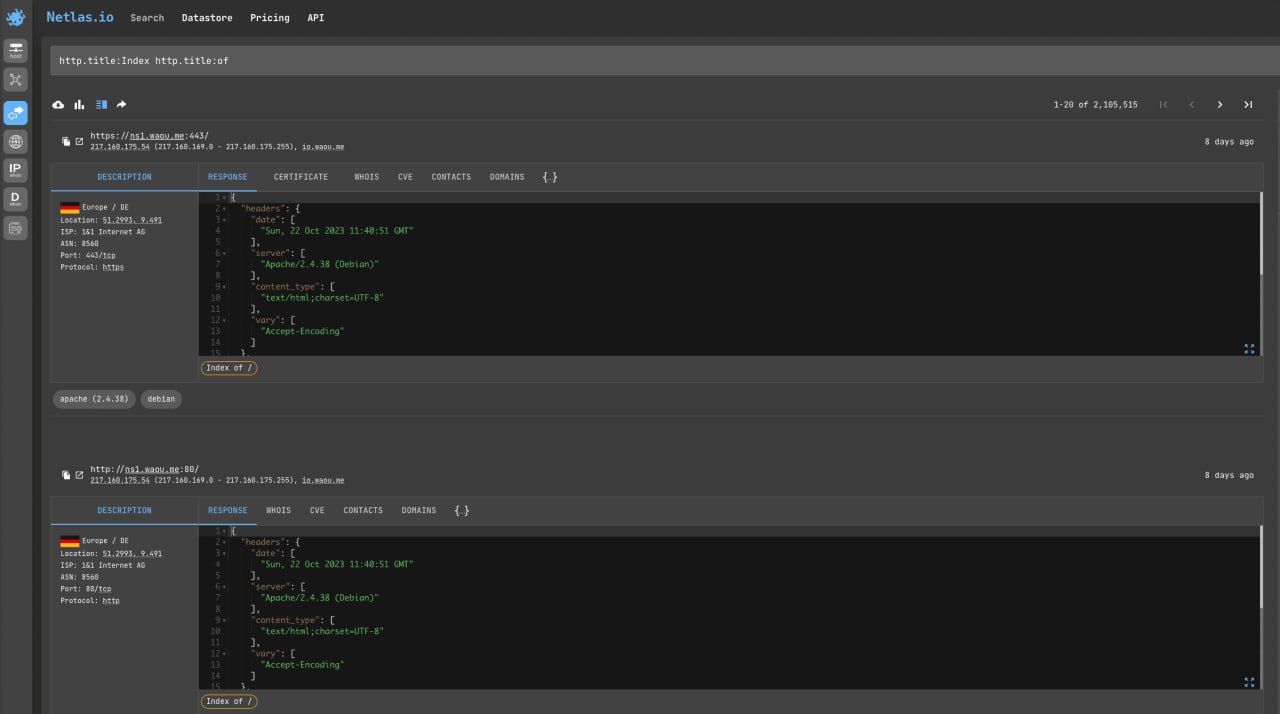
There are a huge number of sites and servers that leave their file directories open due to a configuration error (and sometimes deliberately). Here are some examples of queries that will help you find them.
Search for any files directories:
http.title:Index http.title:ofSearch for directories with log files:
http.title:Index http.title:of http.body:logsSearch for directories with database dumps:
http.title:Index http.title:of http.body:sqlSearch for directories with archived backups:
http.title:Index http.title:of http.body:backup?zipSearch for directories with SSH access info:
http.title:Index http.title:of http.body:("ssh_config" OR "ssh_known_hosts" OR "authorized_keys" OR "id_rsa" OR "id_dsa")Search for directories with files with other authorisation information:
http.title:Index http.title:of http.body:("pass" OR "logins" OR "config" OR "password")Search for directories with files downloaded by users:
http.title:index http.title:of http.body:downloadsSearch for directories with Docker configuration files:
http.title:index http.title:of http.body:docker-composeYou can think of hundreds of other such requests. Experiment with different file names and extensions.
Using Netlas.io for Digital Forensics and Incident Response
This section is very difficult to separate from the Netlas for OSINT section, as the queries listed therein will also be useful to those involved in digital forensics.
In this section, we describe more “technical” queries that can help, for example, gather information about the technical infrastructure of networks or investigate phishing attacks.
SMTP Servers Information Gathering
SMTP (Simple Mail Transfer Protocol) is a communication protocol that enables to send and receive emails. In most email clients, when viewing emails, the “Show Original” function is available, which allows you to view the address of the SMTP server from which the email was sent.
Netlas allows you to get information about an SMTP server as well as about any other IP or domain, as well as to search the text of SMPT banners, which allows you to find servers associated with a particular domain, company or hosting provider.
Search query example
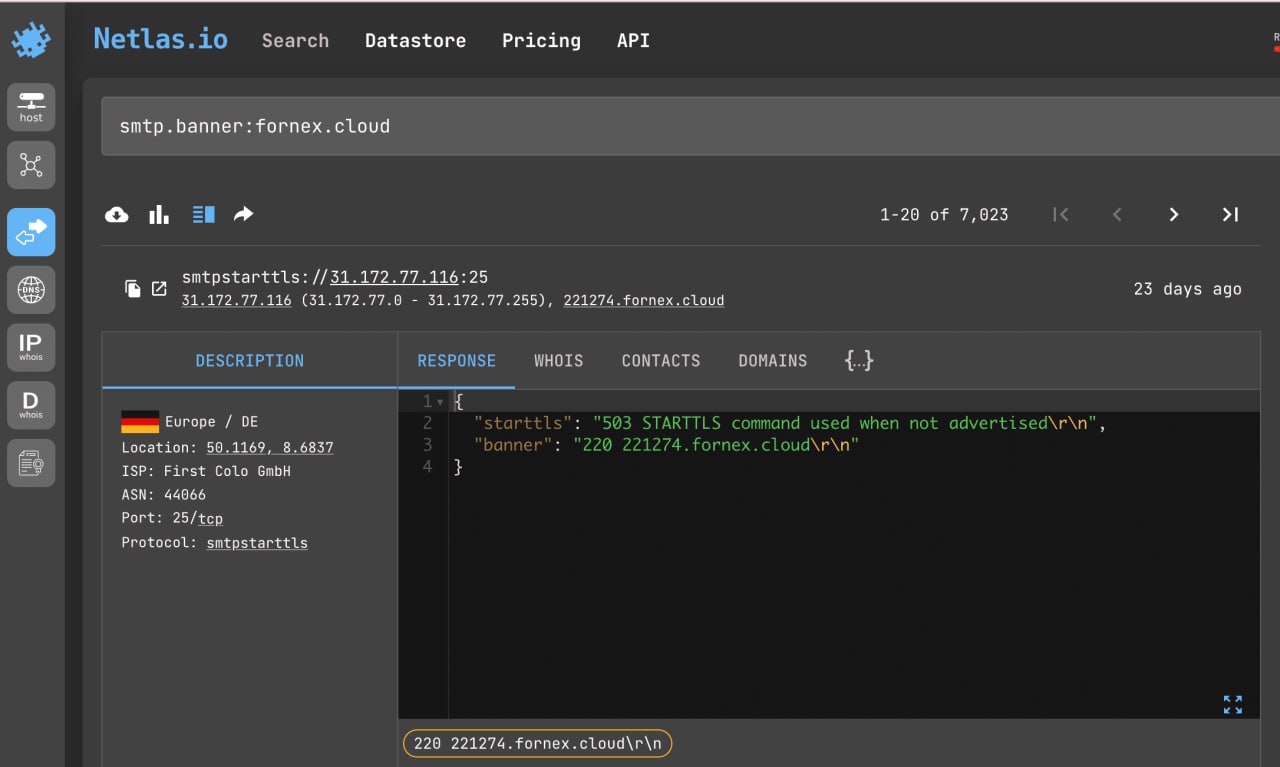
smtp.banner:fornex.cloudNetlas CLI Tools:
netlas search "smtp.banner:fornex.cloud" -f jsonCurl:
curl -X 'GET' \
'https://app.netlas.io/api/responses/?q=smtp.banner%3Afornex.cloud&source_type=include&start=0&fields=*' \
-H 'accept: application/json' \
-H 'X-API-Key: 'YOUR_API_KEY' | jq .items[].data.smtp.bannerCode example (Netlas Python Library)
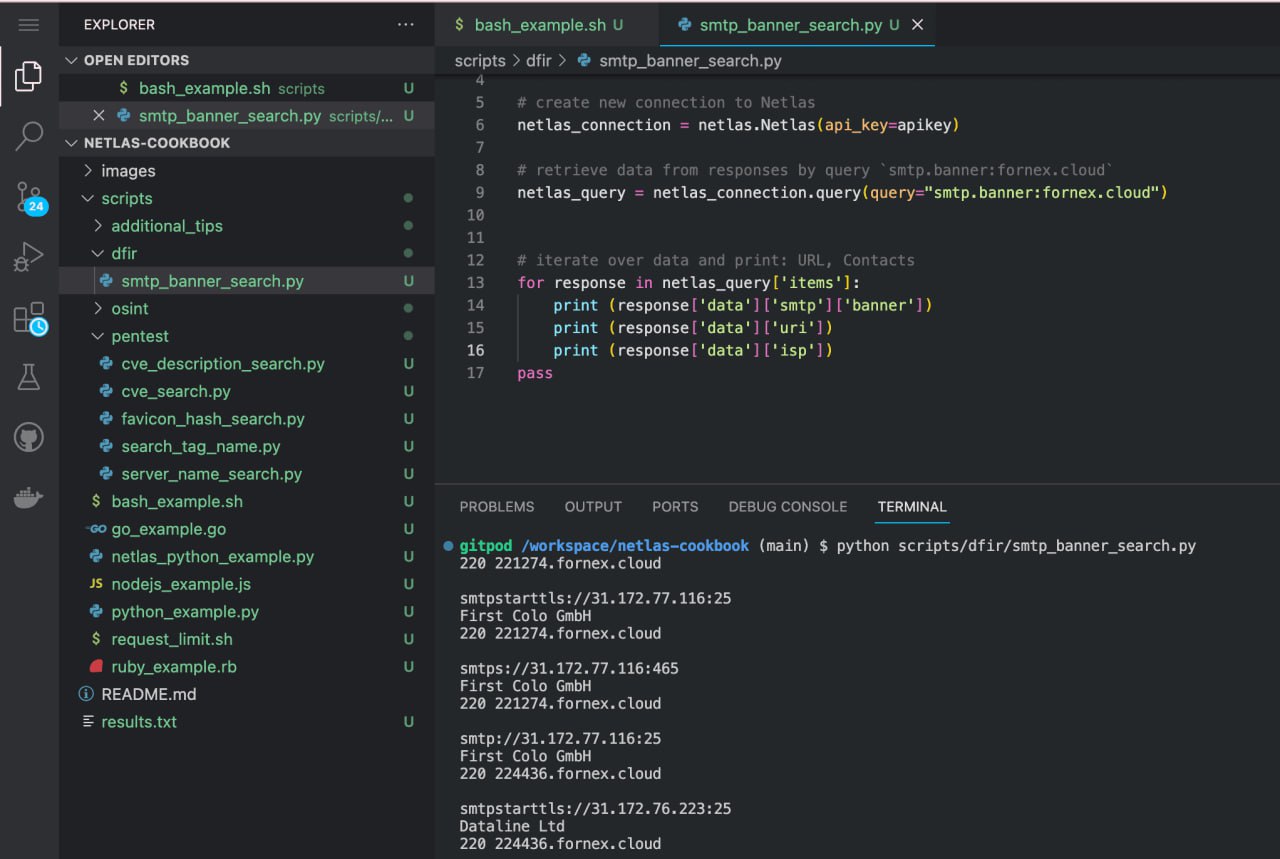
Run in command line:
python scripts/dfir/smtp_banner_search.pySource code of scripts/dfir/smtp_banner_search.py:
import netlas
apikey = "YOUR_API_KEY"
# create new connection to Netlas
netlas_connection = netlas.Netlas(api_key=apikey)
# retrieve data from responses by query `smtp.banner:fornex.cloud`
netlas_query = netlas_connection.query(query="smtp.banner:fornex.cloud")
# iterate over data and print: SMTP banner, URL, ISP
for response in netlas_query['items']:
print (response['data']['smtp']['banner'])
print (response['data']['uri'])
print (response['data']['isp'])Search for Domains That Could Potentially Be Used for Phishing
One of the popular methods of scammers is to use domains that are very similar in spelling to the domains of well-known companies.
You can find such domains for a certain company using Netlas and fuzzy search.
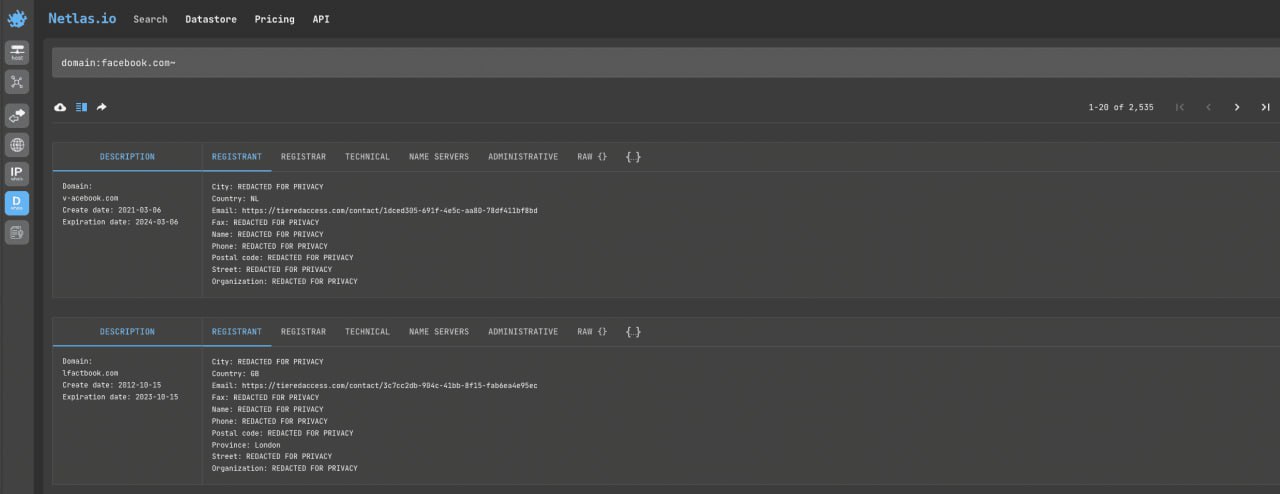
Open Whois domain search and enter company domain name + ~. For example:
domain:facebook.com~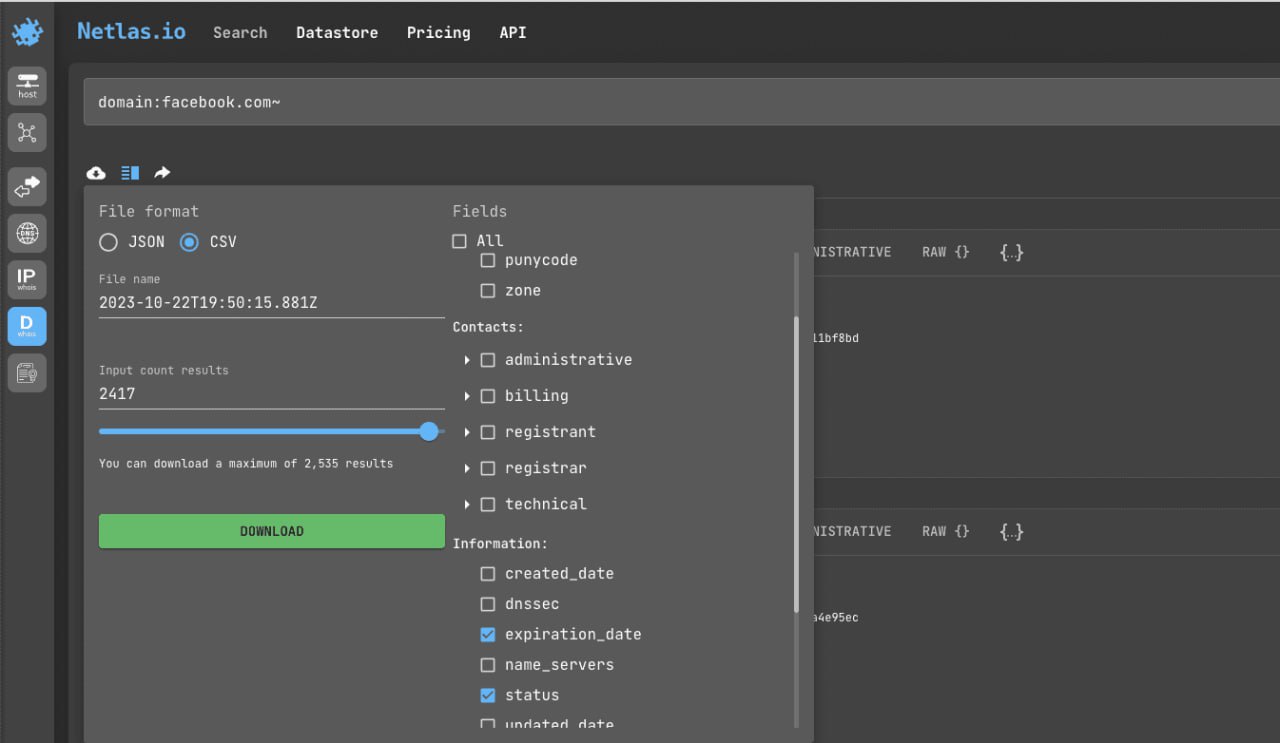
After that click on the left icon, select the export file type, file names and the fields you want to save to the file. Click “Download” and wait for a while.
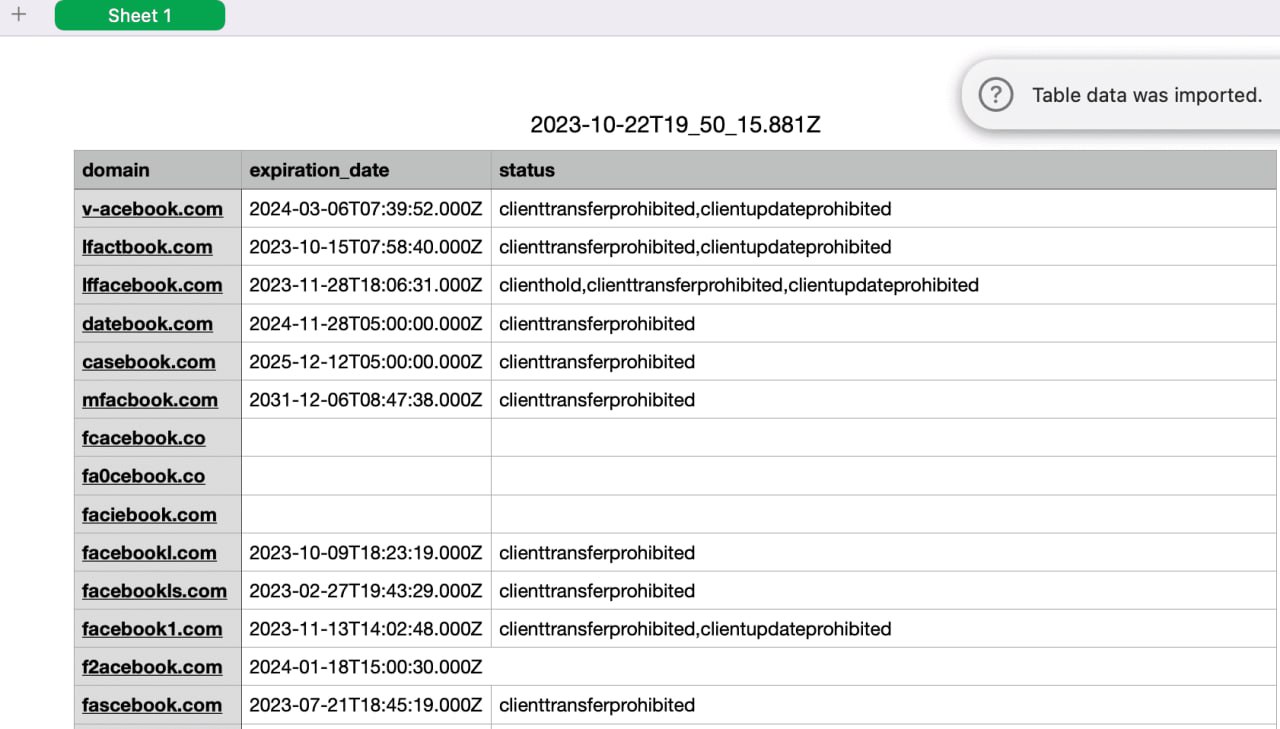
For example, you can select the CSV file format and the domain, expiration_date, status fields. Such a table can be conveniently viewed in Excel, Numbers or Google Docs.
Favicon Search
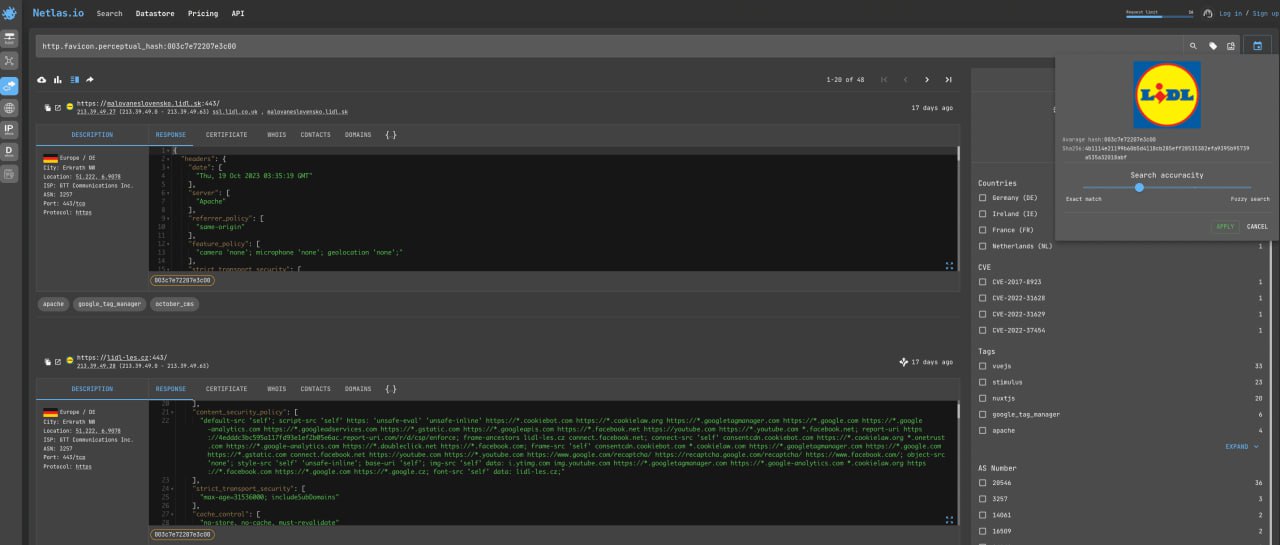
Searching for favicon.ico has three main uses.
First, it allows you to find potentially related sites and subdomains. Try to find IP associated with Lidl shops:
http.favicon.perceptual_hash:003c7e72207e3c00And also to find phishing sites that use the design of popular social networks, online stores, etc.
Second, it is a search for various IoT devices. Try to find HP products:
http.favicon.perceptual_hash:0c5ec8c181f37e2cThird, it searches for servers that have certain software launched on them. Try to find servers with PhpMyAdmin:
http.favicon.perceptual_hash:00084e5e5fffff8dThere are three main ways to search by favicon hash in Netlas:
- Click on the icon to the left of the search result.
- Click on the favicon search button to the right of the search bar and paste the favicon link into the pop-up window.
- Click on the favicon search button to the right of the search bar and upload the favicon file.
You can also use the following filters to search by favicon:
http.favicon.last_modifiedhttp.favicon.last_updatedhttp.favicon.urihttp.favicon.path
Search for Domains Associated with a Specific Subnet
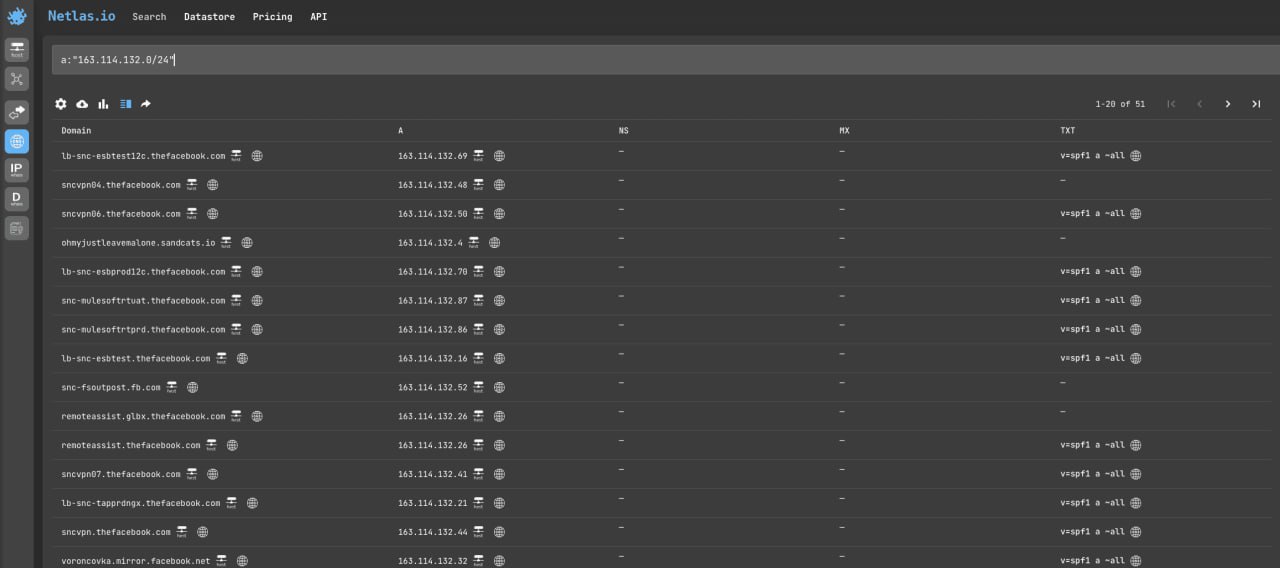
Netlas domain search allows to get a complete list of domains associated with a specific IP address or range of addresses. Fox example:
a:"163.114.132.0/24"API request example
Netlas CLI Tools:
netlas search -d domain a:\"163.114.132.0/24\"Curl:
curl -X 'GET' \
'https://app.netlas.io/api/domains/?q=a%3A%22163.114.132.0%2F24%22&source_type=include&start=0&fields=*' \
-H 'accept: application/json' \
-H 'X-API-Key: 'YOUR_API_KEY' | jq .items[].data.domainCode example (Netlas Python Library)
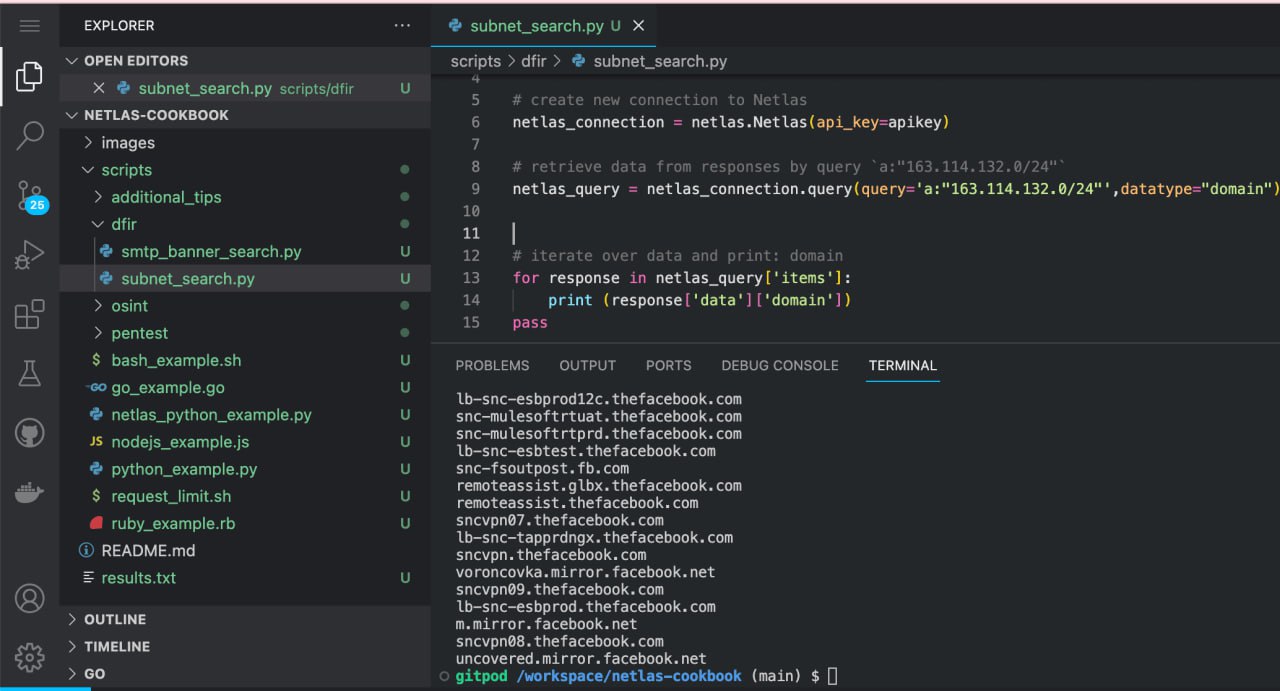
Run in command line:
python scripts/dfir/subnet_search.pySource code of scripts/dfir/subnet_search.py:
import netlas
apikey = "YOUR_API_KEY"
# create new connection to Netlas
netlas_connection = netlas.Netlas(api_key=apikey)
# retrieve data from responses by query `a:"163.114.132.0/24"`
netlas_query = netlas_connection.query(query='a:"163.114.132.0/24"',datatype="domain")
# iterate over data and print: domain
for response in netlas_query['items']:
print (response['data']['domain'])Search for Servers with Malicious Software
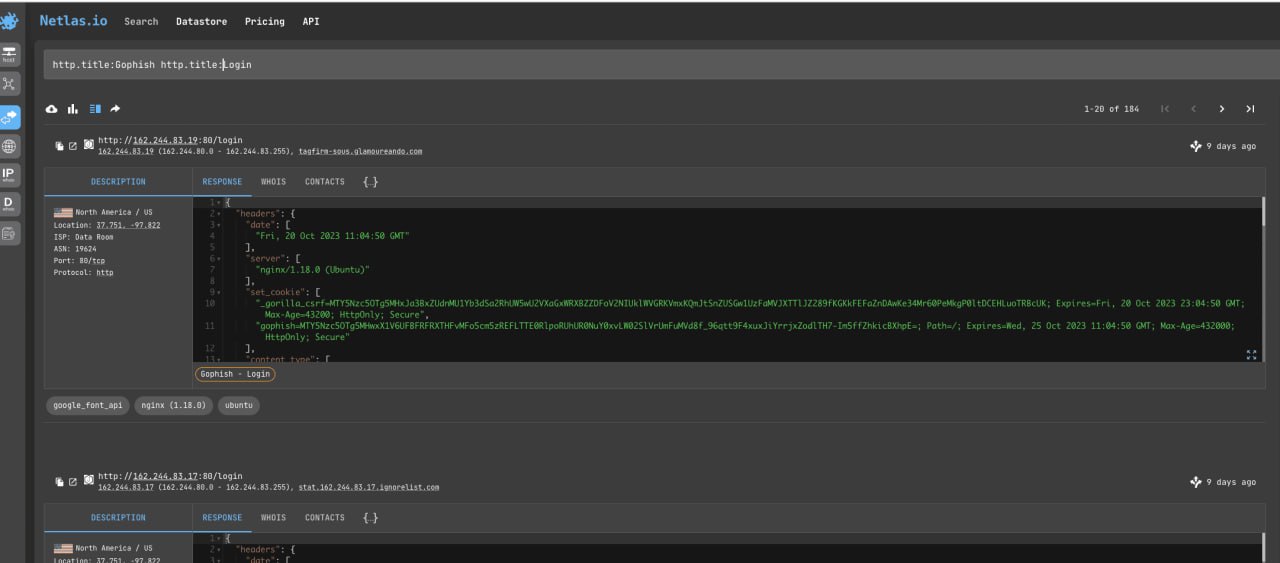
Netlas allows you to find servers that have various malware installed on them. You can find it by the presence of certain words in http.title or http.body, favicon hash, ssl and other parameters.
Here is an example of a query that will find servers that have GoFish (Open Source Phishing Framework) installed:
http.title:Gophish http.title:LoginNote that the technique of using the same operator twice (instead of an asterisk between two words) is used here. Sometimes this helps you get more search results.
Here are some more examples of similar requests:
http.title:CALDERA http.title:login
http.title:Deimos http.title:C2 API request example
Netlas CLI Tools:
netlas search "http.title:Gophish http.title:Login" -f jsonCurl:
curl -X 'GET' \
'https://app.netlas.io/api/responses/?q=http.title%3AGophish%20http.title%3ALogin&source_type=include&start=0&fields=*' \
-H 'accept: application/json' \
-H 'X-API-Key: YOUR_API_KEY' jq .items[].data.uriCode example (Netlas Python Library)
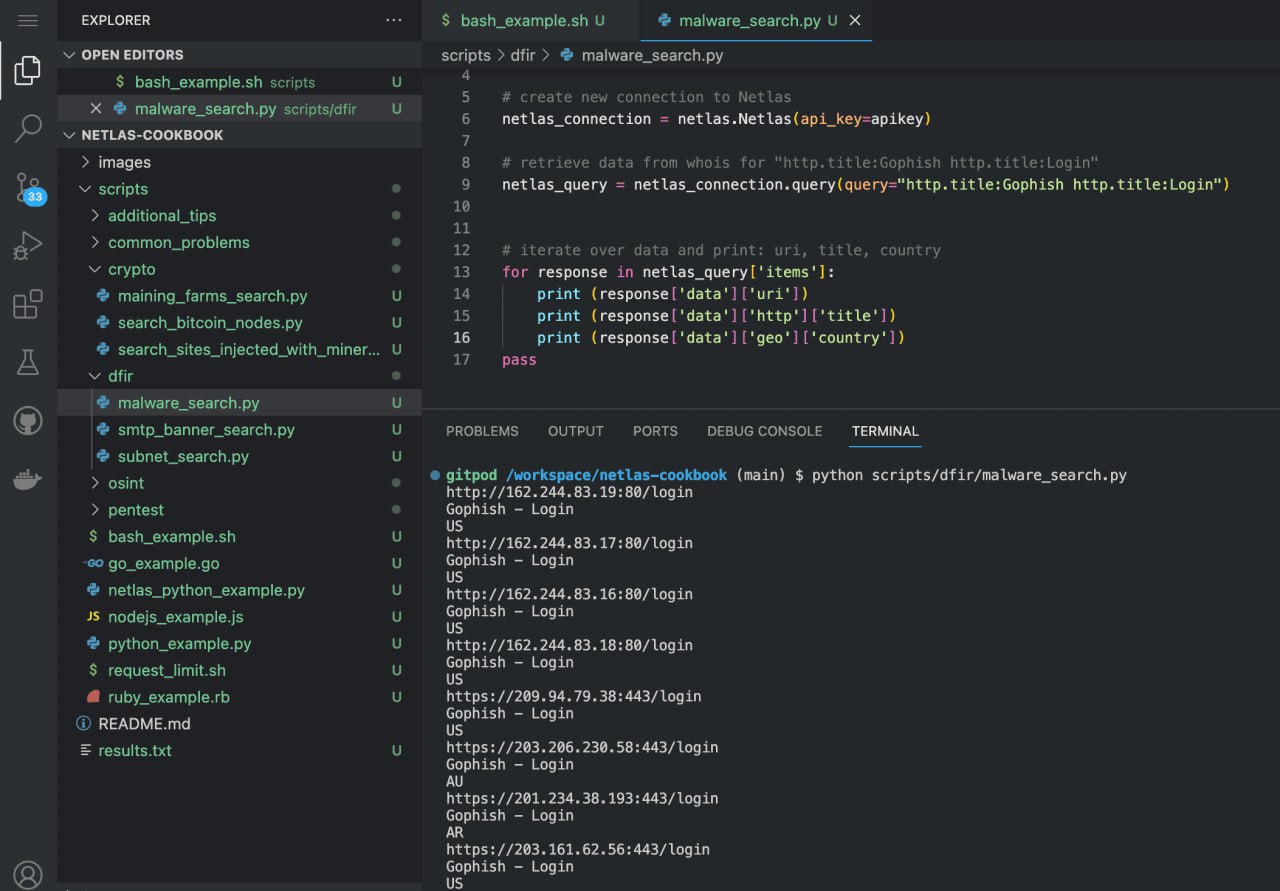
Run in command line:
python scripts/dfif/malware_search.pySource code of scripts/dfir/malware_search.py:
import netlas
apikey = "YOUR_API_KEY"
# create new connection to Netlas
netlas_connection = netlas.Netlas(api_key=apikey)
# retrieve data from whois for "http.title:Gophish http.title:Login"
netlas_query = netlas_connection.query(query="http.title:Gophish http.title:Login")
# iterate over data and print: uri, title, country
for response in netlas_query['items']:
print (response['data']['uri'])
print (response['data']['http']['title'])
print (response['data']['geo']['country'])Search for Technologies and Code Examples
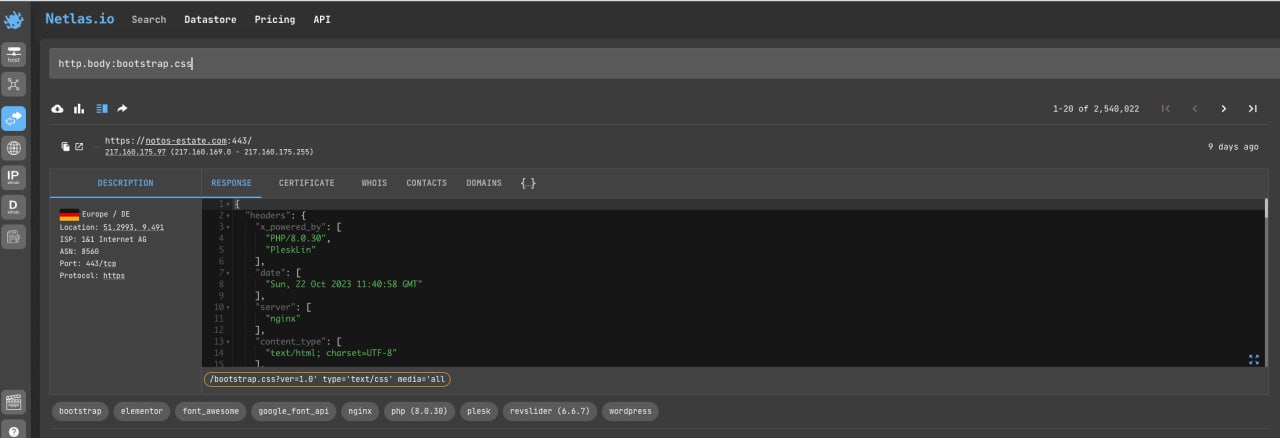
Netlas, unlike conventional search engines, allows you to search the entire HTML code rather than the text of the page. This allows you to find sites that use certain JavaScript libraries. This can help you find code samples suitable for your tasks and save your time.
For example, looking for sites that use an old obscure library to draw graphics:
http.body:kinetic.jsYou can also see how different CSS frameworks are used on sites of certain themes and borrow good design ideas:
http.body:bootstrap.css http.title:travelYou can also filter sites that use specific frameworks and technologies by using tags:
tag.bootstrap:*tag.angularjs:*tag.wordpress:*tag.nextjs:*Using Netlas.io for Fun or Netstalking
Netlas, like many other search engines, can be used without any specific purpose, and just explore with its help unexplored corners of the Internet, hoping to find something interesting there.
Here are some examples of search queries that will help you find what Google can’t.
Search by text of Telnet servers banners (yes, they’re still alive!):
telnet.banner:library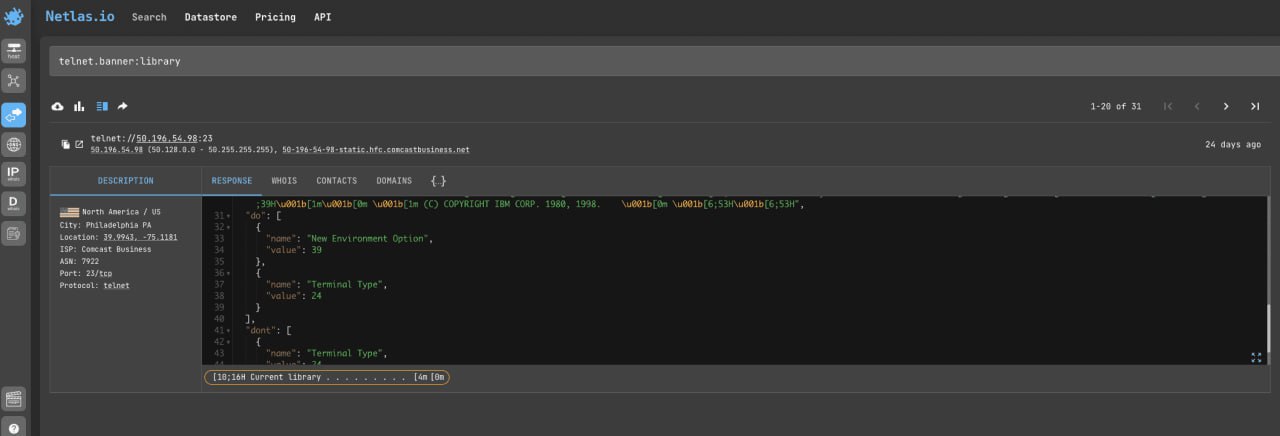
Search by text of FTP servers banners:
ftp.banner:*library*Search for links to books and documents:
http.body:*rowling*pdfSearch for links to music and video:
http.body:*cats*mp4Search for links to torrents file:
http.body:*cats*mp4Keep in mind that Netlas does not censor the content it stores in its database in any way. If you find something illegal or immoral, you should complain to the hosting provider whose contacts are listed in the domain information.
Common Problems
Error 429 - Too Frequent Requests
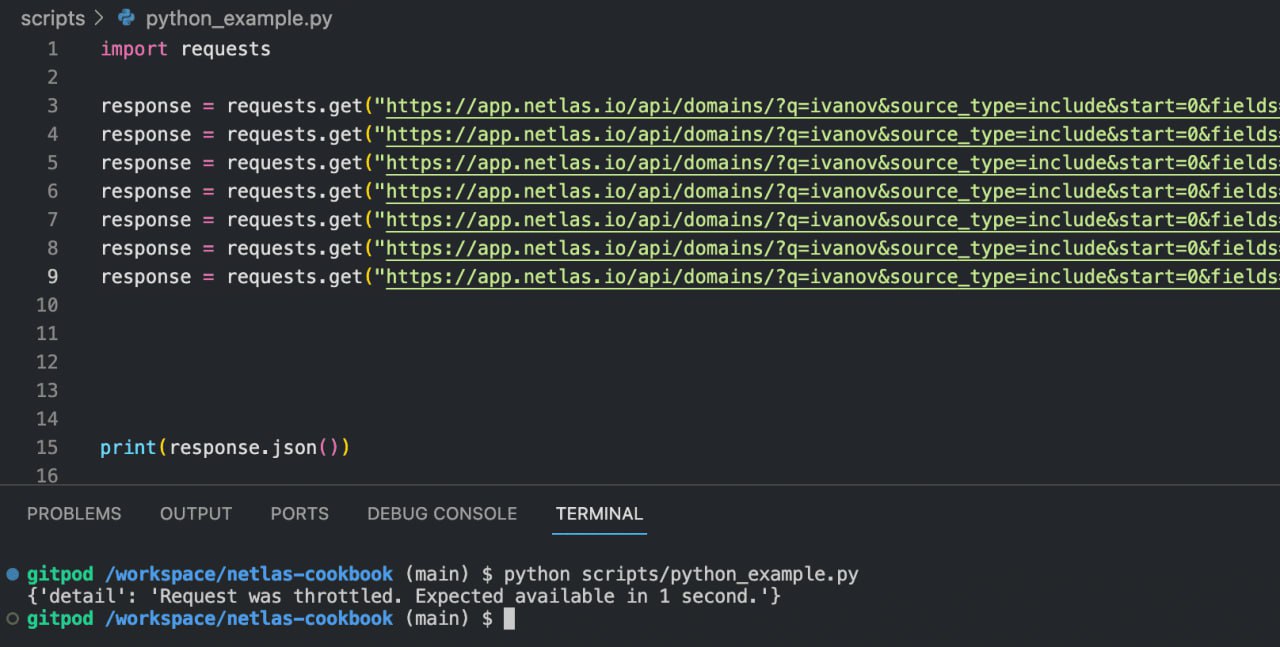
If your application includes multiple requests to the Netlas API, you may encounter this error:
{'detail': 'Request was throttled. Expected available in 1 second.'}One way to solve this problem is to use special Python libraries to configure time limits on query execution, such as Limiter Package.
Here is an example of its use in code (limit of no more than 60 requests per minute). First, install package:
pip install ratelimitAnd run rate_limit.py:
python scripts/common_problems/rate_limit.pyimport netlas
from ratelimit import limits
# One second - one call
@limits(calls=1, period=1)
def netlas_query():
apikey = "YOUR_API_KEY"
# create new connection to Netlas
netlas_connection = netlas.Netlas(api_key=apikey)
# retrieve data from responses by query `cve.description:weblogic AND cve.has_exploit:true`
netlas_query = netlas_connection.query(query="cve.description:weblogic AND cve.has_exploit:true")
# iterate over data and print: url, first CVE name first CVE description
for response in netlas_query['items']:
print (response['data']['uri'])
print (response['data']['cve'][0]['name'])
print (response['data']['cve'][0]['description'])
netlas_query()Similar packages exist for other popular programming languages, as exceeding the request limit is a very common problem when working with almost most APIs.
If you really need to make more than one enquiry per second, you can write to the sales team.
KeyError
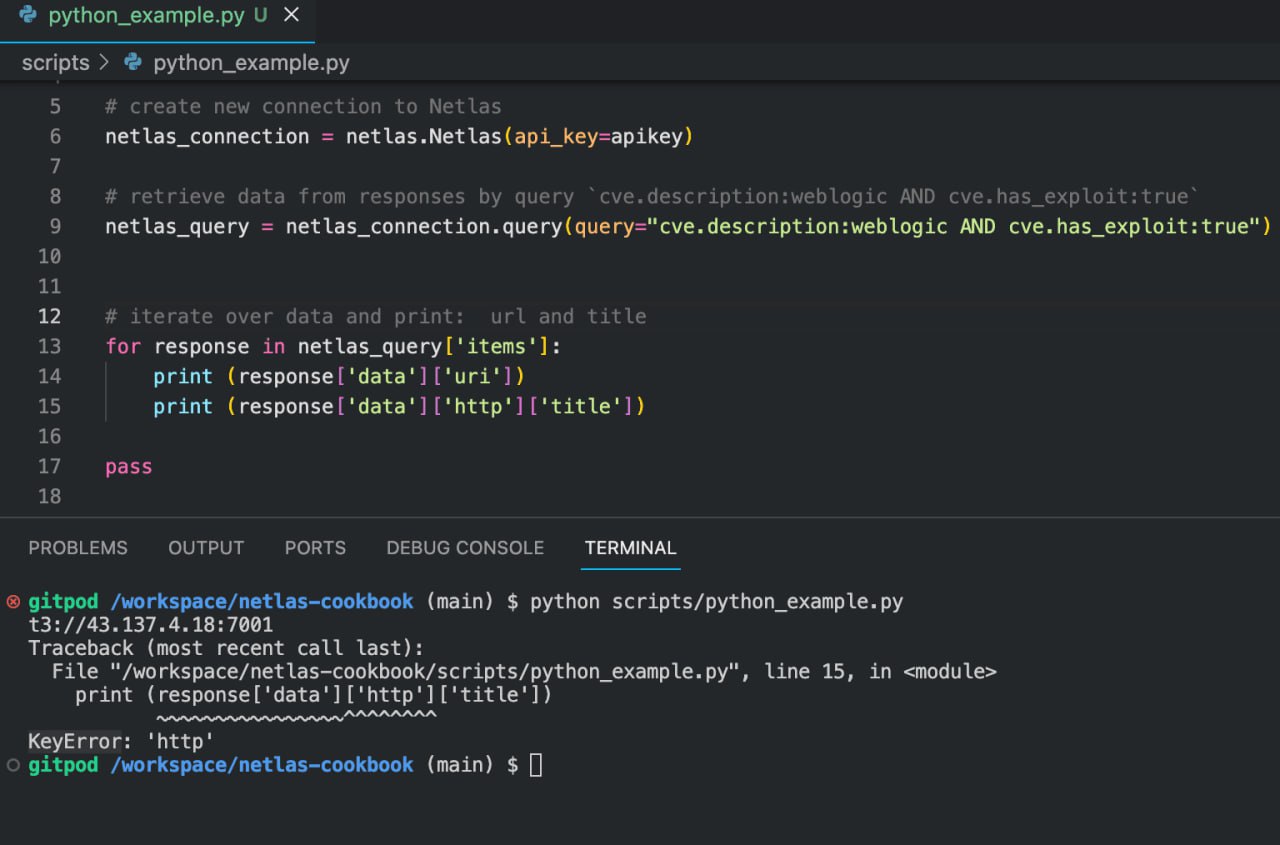
Another common problem is the lack of a specific key in response for some servers. For example, [‘data’][‘http’][’title’] is quite often missing.
If the key is missing, the script stops executing. Standard error handling will help to avoid this. For example:
try:
print (response['data']['http']['title'])
except:
print ("no title")Automation of Work with the List of Requests
The main advantage of working with Netlas Python or the Netlas API versus just typing queries in the web version of Netlas.io is that you can save a tremendous amount of time typing one-size-fits-all queries. For example, you can quickly gather information about a long list of domains using very simple Python code.
Run in command line:
python scripts/common_problems/domain_list_search.pySource code of domain_list_search.py:
import netlas
apikey = "YOUR_API_KEY"
# create new connection to Netlas
netlas_connection = netlas.Netlas(api_key=apikey)
# read file domains.txt line by line
with open("scripts/common_problems/domains.txt") as f:
# save each line to domain variable
for domain in f:
# retrieve data from responses by query `domain:domainname`
netlas_query = netlas_connection.query(
query=f"domain:{domain}", datatype="domain-whois"
)
# iterate over data and print: ip, isp
for response in netlas_query['items']:
print (response['data']['ip'])
print (response['data']['isp'])Similarly, you can work with a list of certificates, IP addresses, emails and whatever else you want.
An example of searching IP addresses from a URL-loaded list can be found in Tor exit nodes search.
Saving Data in CSV Format
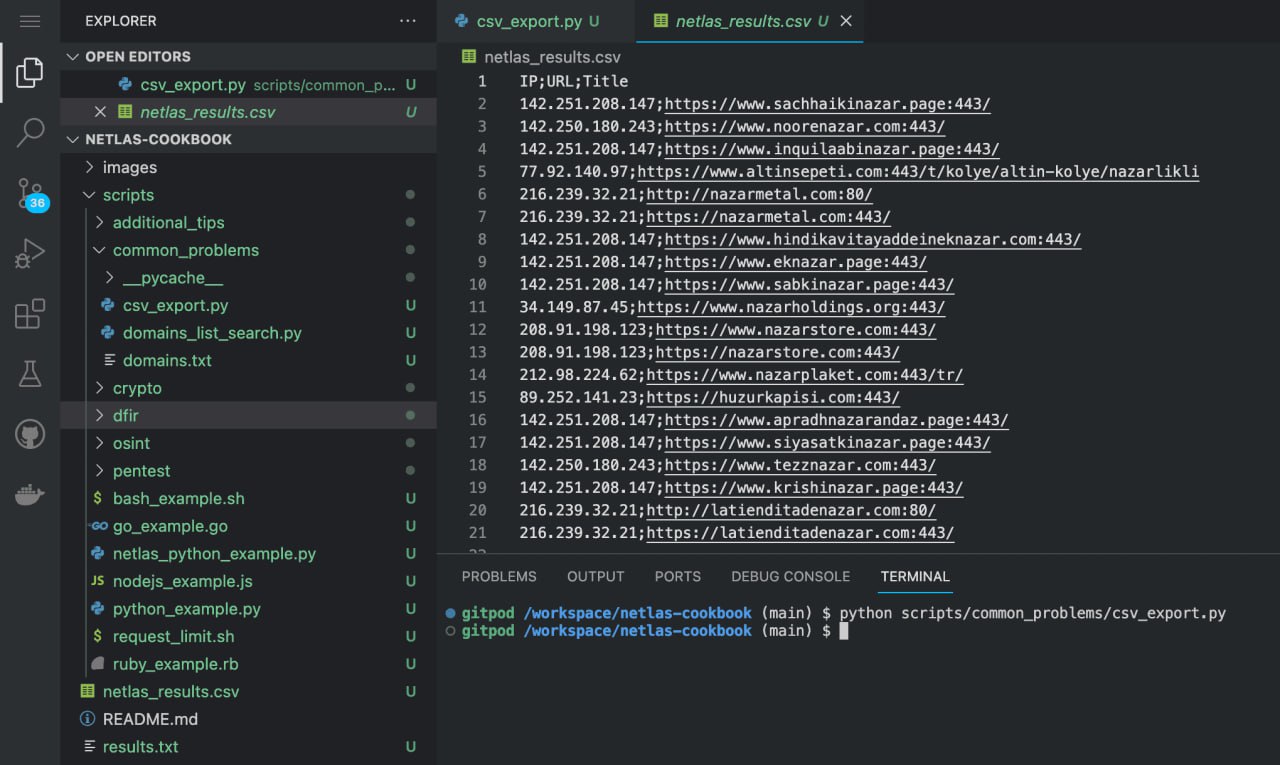
By default, the Netlas Python Library returns data of type Dictionary (which is very similar to JSON). If you want to export the data to MS Excel or Google Sheets, one easy way to do it is to save it in CSV format.
Here’s an example using the CSV package. Run csv_export.py:
python scripts/common_problems/csv_export.pyimport netlas
import csv
apikey = "YOUR_API_KEY"
# create new connection to Netlas
netlas_connection = netlas.Netlas(api_key=apikey)
# retrieve data from responses by query `http.meta:nazar`
netlas_query = netlas_connection.query(query="http.meta:nazar")
with open('netlas_results.csv', 'w') as csv_file:
# Create CSV writer object
writer = csv.writer(csv_file, delimiter =';')
# Create a list with data headers:
header = ['IP', 'URL', 'Title']
# Write headers to CSV file
writer.writerow(header)
# iterate over data and print: ip and url to CSV file
for response in netlas_query['items']:
# Create a list with one line of data:
data = [response['data']['ip'], response['data']['uri']]
# Write line to file
writer.writerow(data)
passYou can open netlas_results.csv in Excel or any text editor.
Saving Data in Other Formats
Using Python, you can generate a wide variety of documents based on data from Netlas, inserting images, data visualizations, and customizing the layout. Here are some examples of useful packages.
XLSXWriter - generate Microsoft Excel files.
PyPDF - generate PDF files.
PythonPPTX - generate Microsoft Power Point Presentations.
PythonDOCX - generate Microsoft Word files.
Decoding Punycode Domains
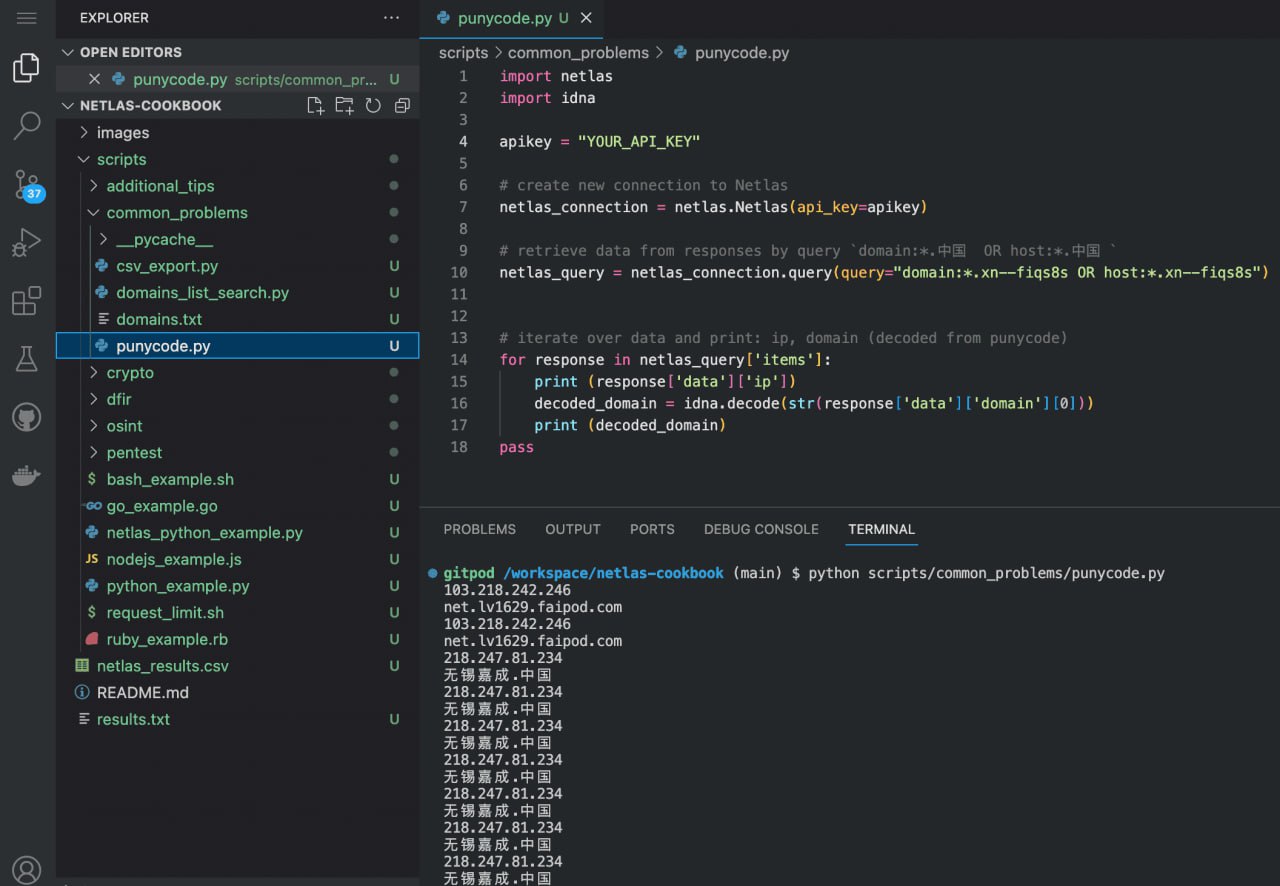
As mentioned above, Netlas does not store non-Latin domain names in their original encoding, but encodes them in Punycode. This is necessary for technical reasons, but it is completely inconvenient for human perception.
But this problem is easily solved with a couple of lines of Python code.
Install IDNA Python package:
pip install idnaAnd run punycode.py in command line:
python scripts/common_problems/punycode.pyimport netlas
import idna
apikey = "YOUR_API_KEY"
# create new connection to Netlas
netlas_connection = netlas.Netlas(api_key=apikey)
# retrieve data from responses by query `domain:*.中国 OR host:*.中国 `
netlas_query = netlas_connection.query(query="domain:*.xn--fiqs8s OR host:*.xn--fiqs8s")
# iterate over data and print: ip, domain (decoded from punycode)
for response in netlas_query['items']:
print (response['data']['ip'])
decoded_domain = idna.decode(str(response['data']['domain'][0]))
print (decoded_domain)What to Do If Search Queries Don’t Return Results?
Sometimes you may encounter a situation where no or very few results are found on query, although you are sure there should be many more. In this case we recommend you to experiment and try to change the queries a bit.
Try adding two asterisks to your keyword. For example, domain:github.com returns 1,592,846 results. domain:githib.com - only 7911 results.
Try using different search filters to achieve the same goal. For example, compare results for uri:github.com, host:github.com and domain:github.com.
Do not use spaces in keywords. If you need to find the phrase “Hello world” in http.body, use the following query:
http.body:hello http.body:worldor
http.body:(hello AND world)Refine your search filters as much as possible. For example, the query cve:2023 will not return results. But the query cve.name:2023 will return more than 28 million.
Try different tabs when working with the web app or different data types when working with the API. For example, when searching for domains, sometimes Host or Domain Whois (rather than response) works better.
Removing HTML Tags from HTTP Body
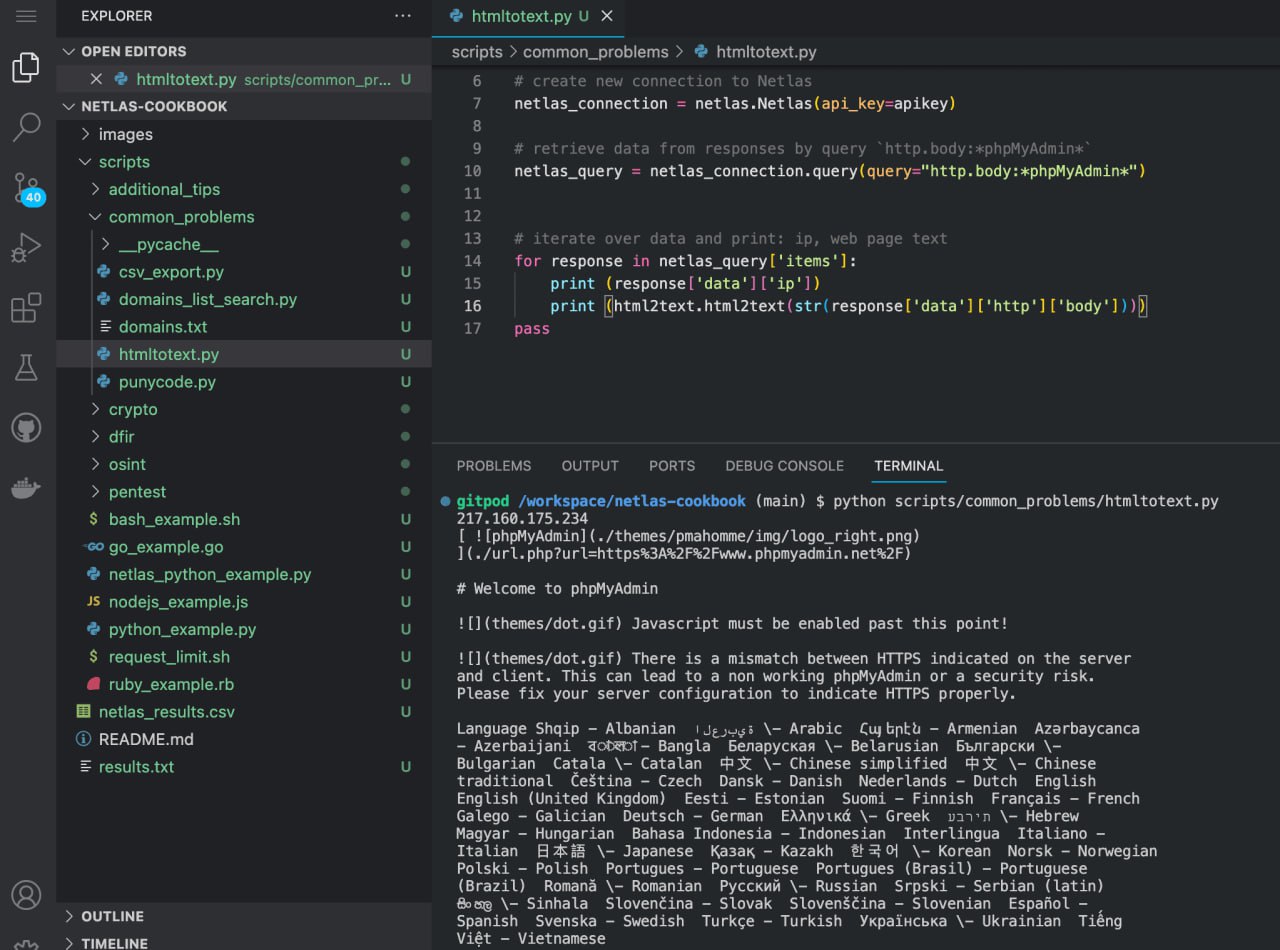
Key [‘data’][‘http’][‘body’] by default returns the full body text of the web page, including all html tags. This format is not very easy to read. But you can easily remove them with the Python package Html2text.
Run in command line:
python scripts/common_problems/htmltotext.pySource code of htmltotext.py:
import netlas
import html2text
apikey = "YOUR_API_KEY"
# create new connection to Netlas
netlas_connection = netlas.Netlas(api_key=apikey)
# retrieve data from responses by query `http.body:*phpMyAdmin*`
netlas_query = netlas_connection.query(query="http.body:*phpMyAdmin*")
# iterate over data and print: ip, web page text
for response in netlas_query['items']:
print (response['data']['ip'])
print (html2text.html2text(str(response['data']['http']['body'])))Attack Surface Management
The Netlas platform includes tools for attack surface management, but this topic is beyond the scope of this guide. If you are interested in attack surface management in general and using Netlas specifically, we recommend starting with these articles:
Working with Very Large Amounts of Data
If you have a really big challenge ahead of you. For example, you need to collect data on hundreds of thousands of domains, then perhaps a more rational solution in terms of time and financial costs will be to buy a dataset (csv/json) and work with it on your own server.
In Netlas Datastore you can find:
- Known domain names dataset (more than 2 billion items)
- Forward DNS dataset (more than 2 billion items)
- Known PTR records (more than 1 billion items) - FREE
- Top 1,000,000 most common subdomains
and more.
Acknowledgments
Many thanks @cyb_detective for help (https://cybdetective.com)